原文:Dynamo: amazon’s highly available key-value store
TL;DR
Dynamo是一种去中心化的KV分布式存储系统。它的主要设计目标是:
- 高可用性(always writable)。
- 高可伸缩性。
- 高性能(低延时)。
- 面向异构机器。
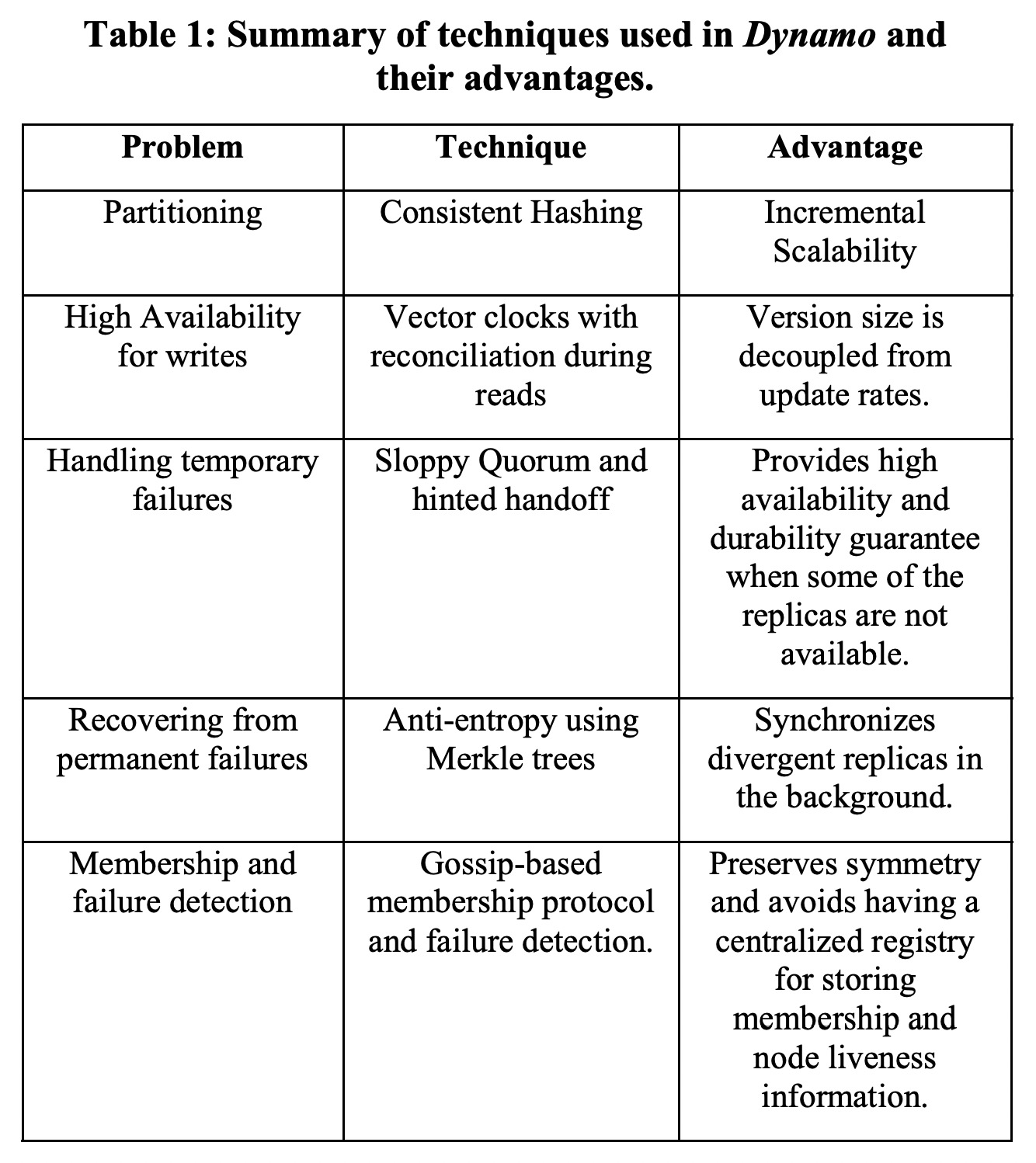
为此Dynamo在CAP中选择了AP,牺牲了一部分的一致性(最终一致)。针对潜在的数据修改的冲突,Dynamo将选择权交给了用户,读取会返回一个“vector clock”,由用户自己解决冲突。
另外为了避免单点问题影响可用性,Dynamo选择了去中心化架构,所有节点都是相同地位的,通过一致性哈希决定数据分片,通过gossip协议在不同节点间同步节点列表和所管理的数据范围。
Dynamo使用了quorum协议(即R+W>N)来读写不同replica的数据。为了进一步提升集群发生错误时的可用性,Dynamo使用了“sloppy quorum”以允许少数派节点也可以临时写入数据,因此造成的数据冲突由上面提到的vector clock来解决。
Dynamo与BigTable是同一个时期非常不同的两种技术选择,前者看重可用性,后者看重一致性,且有着更复杂的数据模型。目前来看,用户似乎通常不太喜欢自己来解决数据冲突,默认的“last write win”策略已经够好了。对于只在一个datacenter内的后继系统来说,Dynamo有点过于复杂了,中心节点可以极大简化系统设计。但对于跨datacenter的系统,quorum的价值一下子提高了很多。