TL;DR
Dynamo是一种去中心化的KV分布式存储系统。它的主要设计目标是:
- 高可用性(always writable)。
- 高可伸缩性。
- 高性能(低延时)。
- 面向异构机器。
为此Dynamo在CAP中选择了AP,牺牲了一部分的一致性(最终一致)。针对潜在的数据修改的冲突,Dynamo将选择权交给了用户,读取会返回一个“vector clock”,由用户自己解决冲突。
另外为了避免单点问题影响可用性,Dynamo选择了去中心化架构,所有节点都是相同地位的,通过一致性哈希决定数据分片,通过gossip协议在不同节点间同步节点列表和所管理的数据范围。
Dynamo使用了quorum协议(即R+W>N)来读写不同replica的数据。为了进一步提升集群发生错误时的可用性,Dynamo使用了“sloppy quorum”以允许少数派节点也可以临时写入数据,因此造成的数据冲突由上面提到的vector clock来解决。
Dynamo与BigTable是同一个时期非常不同的两种技术选择,前者看重可用性,后者看重一致性,且有着更复杂的数据模型。目前来看,用户似乎通常不太喜欢自己来解决数据冲突,默认的“last write win”策略已经够好了。对于只在一个datacenter内的后继系统来说,Dynamo有点过于复杂了,中心节点可以极大简化系统设计。但对于跨datacenter的系统,quorum的价值一下子提高了很多。
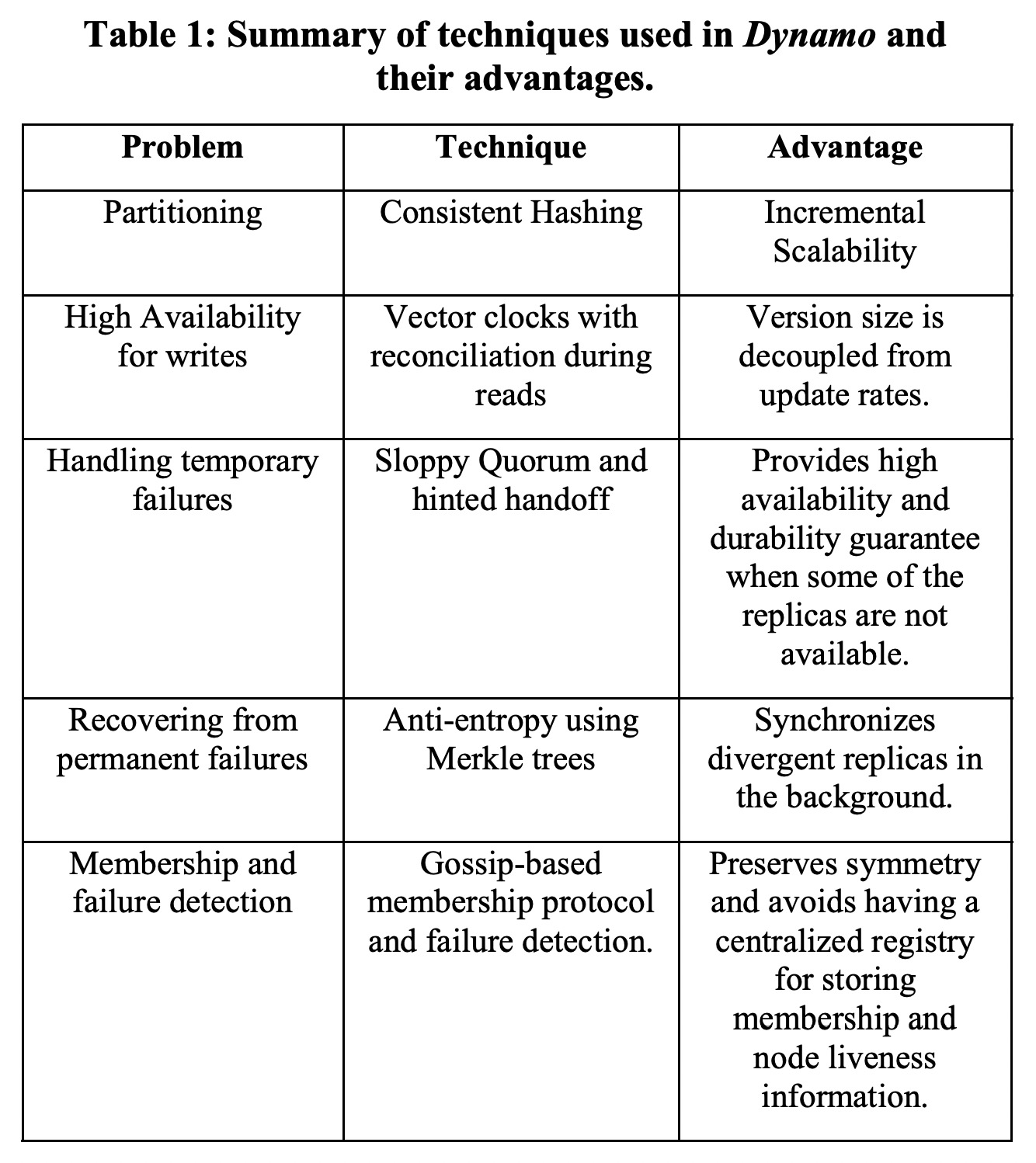
Partitioning and Replication
Dynamo使用一致性哈希,每个物理节点根据自己的处理能力(面向异构)使用多个虚拟节点。每个key range的N个replica由它对应的节点和前面的N-1的节点负责,其中它对应的节点称为coordinator,正常情况下负责处理这个key range的读写请求和replication。
这N个节点被称为这个key range对应的“preference list”。preference list中只包含物理节点。
Dynamo使用Merkle树来组织数据,这种数据结构的优点是每层都有hash value,可以非常方便地对比两个replica的数据是否一致,以及是哪部分不一致。不同replica会在使用gossip协议通信时完成这种比较,并后台合并冲突版本。
使用Merkle树的缺点是在有虚拟节点加入退出时涉及到的key range数据都要重新算。
Ensuring Uniform Load distribution
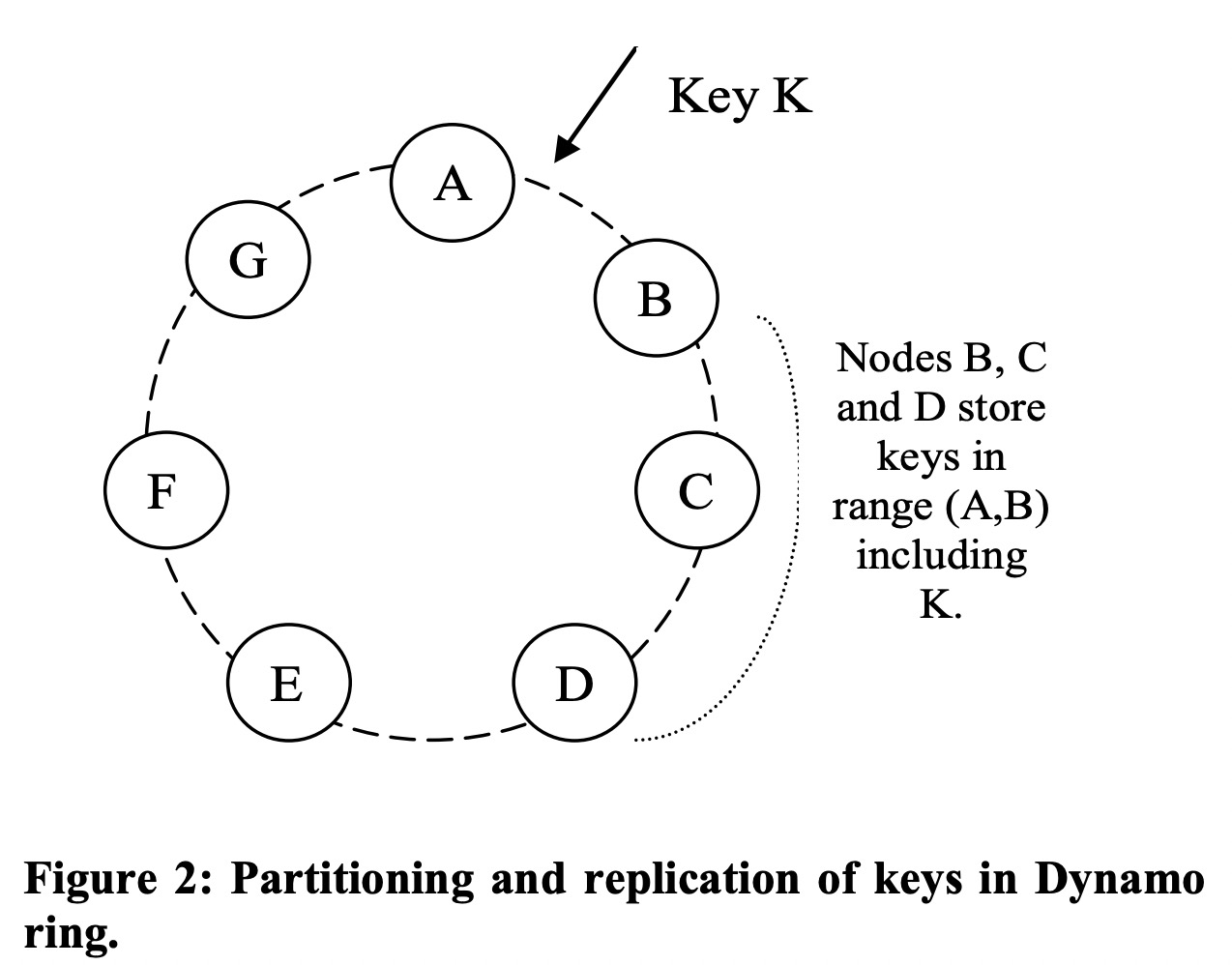
以下三种partition策略:
- 每个节点在整个哈希空间中随机选择T个token。
- 将哈希空间切成均匀的Q个区间,每个节点仍然随机选择T个token,但token要是区间的端点。
- 将哈希空间切成均匀的Q个区间,每个节点选择Q/S个token(S是节点数量),token不要求是区间端点。节点退出时将它的token均匀分给其它节点,加入时从其它节点获得token。
方案1是最早使用的,它的缺点是节点加入和退出时数据的迁移成本和Merkele树的计算成本都很高。另外它将数据分片和分布耦合在了一起,如果要增加节点以平摊负载,就不可避免地影响数据分布。
方案2中要求Q远大于N和S*T,这样token只影响数据分布,不影响数据分片。
方案3的metadata远比方案1要少,且有着更快的启动和恢复,也更容易归档数据。相比方案2,方案3的各节点负载更均衡。它的缺点是节点加入和退出要做额外的通信。
测试显示方案3的负载更均衡。
Data versioning
Dynamo的目标应用需要保证always writable,因此Dynamo允许在网络分区发生时,位于少数派的节点仍然有能力写数据。另外正常的异步replication也有可能导致数据写入在不同节点上有不同的顺序。
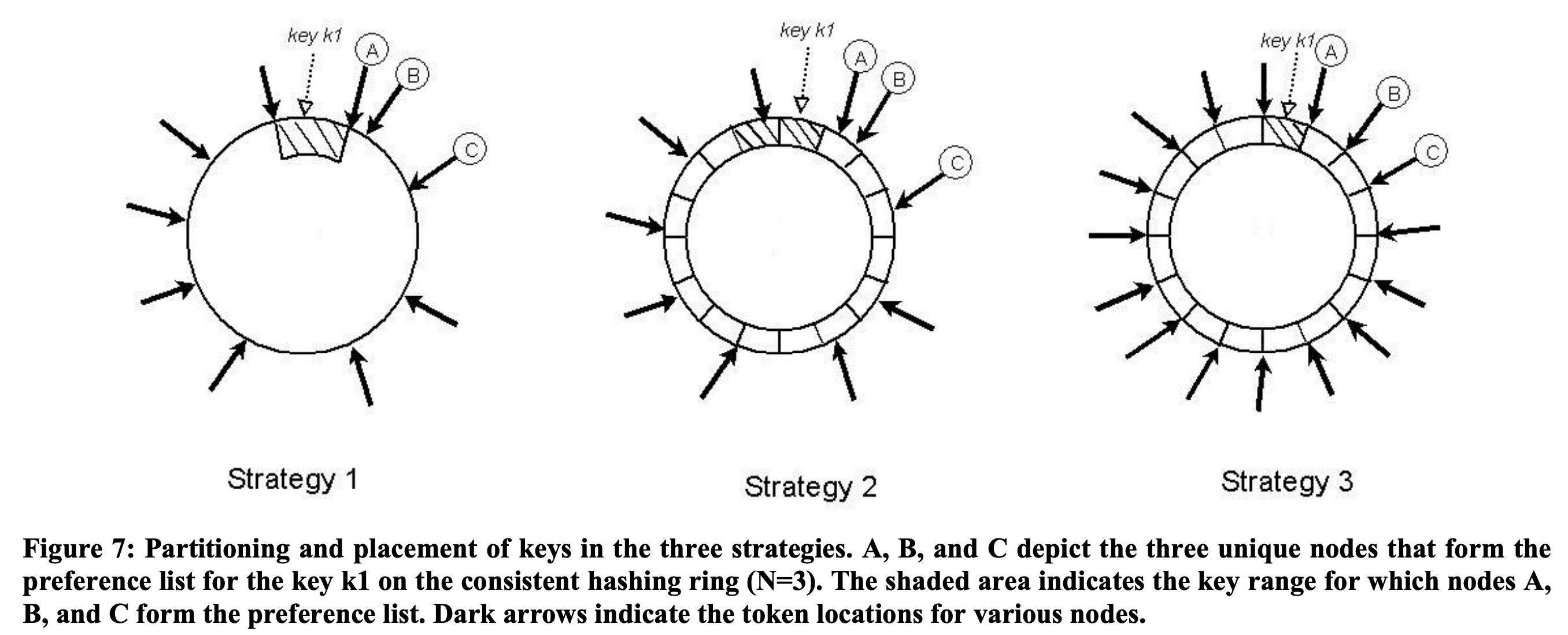
Dynamo选择将这些写入历史记录下来,构成vector clock,由用户解决。
一个vector clock由一组(node, counter)组成,记录了它在某个node的最后一笔写入的counter(node级别单调增),这样如果vector A在每个node上的counter都小于等于vector B,则称B包含A。两个互不包含的vector可以merge到一起,由用户决定最终值是什么。
Dynamo中用户更新某个值的时候就需要带上vector clock(通常由前面的读操作返回),它会清除掉包含的其它vector clock,从而解决冲突。
通常vector长度不会超过N,但考虑到极端场景(频繁失败 + 节点加入退出),Dynamo会在vector长度超过一个阈值时将最古老的那个node从vector中踢掉。理论上会丢失一些历史,但生产场景没遇到过。
put and get
client在读写某个key的时候有两种方式:
- 通过load balancer,将请求扔给任一节点。
- 直接与coordinator通信。
方案2可以少一跳,但可能导致压力不均衡。
如果client不知道谁是coordinator,或使用了load balancer,与它通信的节点会负责将请求转发给对应的coordinator。如果coordinator此时处于错误状态,请求会被转给preference list上的其它节点。
coordinator收到put请求后,它会在本地写入并将请求转发给preference list上其它N-1个replica,并在收到W-1个回应后返回给client。失败的请求不会回滚,coordinator后续还会重试。
读的时候coordinator也会等收集到R-1个回应后就返回client。这R个结果不需要是相同的,coordinator会负责将它们的version clock合并起来返回。
如果读的时候有节点的version clock是被其它节点包含的,会触发read repair,将这个节点的数据更新成包含它的最新版本。
通常coordinator就是preference list的第一个节点,但这样可能造成压力不均匀,因此Dynamo允许这N个节点作为coordinator,尤其是对于read-write场景,Dynamo会选择前一次读中响应最快的节点作为这次写的coordinator,还可以提高获得“read-your-writes”一致性的机会。
sloppy quorum
当健康节点不够W个时,Dynamo不会禁止写入,而是会找再之前的若干个节点临时存放数据,这种协议称为sloppy quorum。
数据写入临时节点时还会附带有信息表明这些数据本该属于哪个节点,临时节点会在正式节点恢复后移交数据。
当然sloppy quorum也增大了数据冲突的概率。
Membership and Failure Detection
每个节点会在本地持久化集群成员列表,并通过gossip协议相互同步,同步的结果是最终一致的。
当有新节点启动时,它先本地持久化几个虚拟节点,之后通过gossip协议逐渐将这个信息扩散出去。为了保证这些信息最终能传播给每个节点,Dynamo会预先选择几个种子节点,每个其它节点的初始列表都有这些种子节点。
Cassandra论文中描述它的gossip协议是每个节点每轮选择一个任意节点,交换信息,这样logN轮之后就可以同步整个集群的信息了。
相应地,如果节点A发现节点B不可达,它也会通过gossip协议同步这个信息,之后可以用不同的方案来检测哪些节点有问题了。