原文:Alibaba Hologres: A Cloud-Native Service for Hybrid Serving/Analytical Processing
TL;DR
Hologres是一种融合了NoSQL的写和OLAP的读的系统,它自称为HSAP,即Hybrid Srerving and Analytical Processing,目标是针对那些同时有着大量在线写入和实时分析需求的场景。
Hologres的主要特点:
- 计算存储分离。
- 兼容PostgreSQL。
- 同时支持行列两种存储形式,从而支持高性能的写入、点查、扫描。
- 高效的高并发实现。
- TableGroup,支持表之间colocate。
- 还支持其它存储引擎,实现federation query。
(没有讲schema change)
HSAP
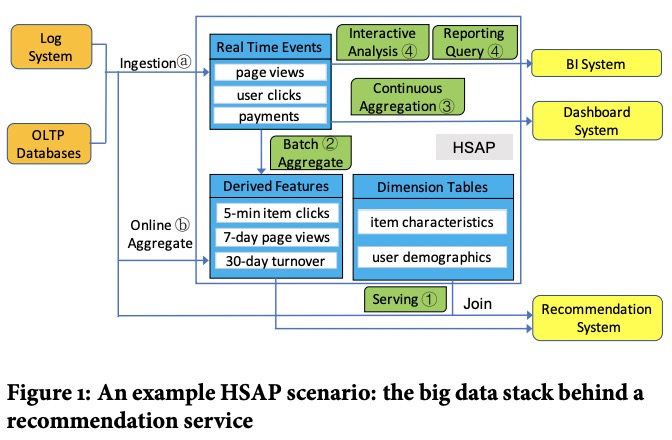
HSAP要服务的典型场景同时需要实时和离线的写入和分析。
传统的OLAP系统通常难以处理高并发的实时请求。HSAP系统既要满足实时和离线请求的SLO,又能充分利用系统资源,还要能保证实时写入的数据在非常短的时间(小于1秒)内可见,还要能处理请求的尖峰。
为了满足以上需求,Hologres选择了:
- 计算存储分离的架构,计算层和存储层可以各自按需求扩缩容和演进;
- 数据被分为若干个tablet,每个tablet都是单写多读的,保证读写路径都是latch-free的;
- 读写路径分离,采用LSM和MVCC,写入亚秒级可见。
具体到实现上,Hologres将请求处理封装到了Execution Context——一种超轻量的调度单位(听起来像协程)——中,充分挖掘了请求内并发能力。
架构
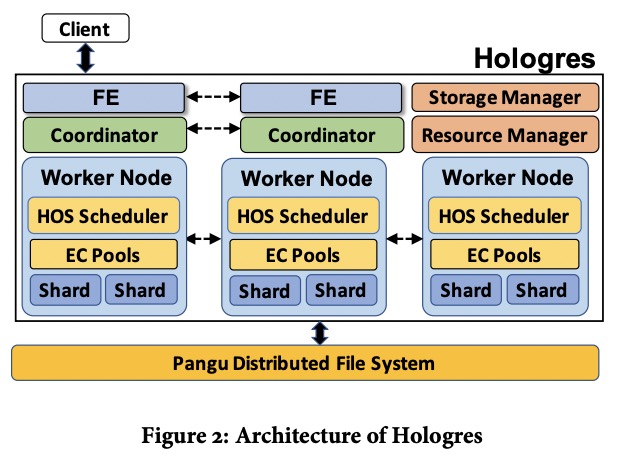
Hologres中FE负责接收请求并解析,coordinator负责执行,每个worker会管理若干个tablet并处理它们的请求。worker里面EC pool是Execution Context运行的地方,而HOS Scheduler负责调度这些EC。
resource manager会在worker间调度table group shard(包含一个或多个tablet),每个shard会占用worker上的一些资源。resource manager还负责增加和移除worker。在有worker挂掉或集群负载突然升高时resource manager都会增加新worker进来。
storage manager管理table group shard列表和它们的元数据,如物理位置(猜测是文件位置,所在的worker node由resource manager管理,但看下文又像是所在的worker)和key range。每个coordinator都会缓存这些信息供分发请求用。
Hologres也可以从其它系统读取数据,如PostgreSQL,查询会下推到这个系统中执行。
存储
数据模型
Hologres中每张表都需要定义一个clustering_key,如果它保证唯一,则使用它作为row locator,否则Hologres会为这张表增加一个唯一id生成器,此时row locator的格式为<clustering_key, uniquifier>。row locator用于分shard。
每张表会从属于一个table group,每个table group会分为若干个shard(可能是按key range分吗),每个shard内包含这个table group中每张表和index的一个tablet。tablet可以是行存或列存,前者面向点查优化,后者面向扫描优化。主表肯定是有row locator的;如果某个index的indexing key不保证唯一,主表的row locator会被插入进来,与indexing key一起组成index的row locator。
table group的好处是单个shard内多张表可以原子写,equi join不需要传输数据。
Table Group Shard
每个TGS有一个WAL,其下每个tablet有自己的memory table和若干个sst,采用leveled compaction。

Hologres中一个请求可以只写一个TGS,也可以写多个TGS,两者都保证是原子的。
只写一个TGS的过程:
- WAL manager分配LSN。
- 持久化log entry。
- 更新涉及的tablet的memory table,且可能触发flush。
写多个TGS时会使用2PC,由收到请求的FE节点来锁住所有参与的tablet(为什么不是coordinator?谁来管理锁?),之后每个TGS:
- 分配LSN。
- flush所有涉及的tablet的memory table。
- 将请求中的数据写成一个sst或多个sst(可以并发写)。
以上是准备过程,接下来FE节点会通知所有tablet提交刚刚写下去的sst,每个TGS会写一个log entry标记这个transaction已经提交了。最后FE节点来释放锁。(如果写失败了怎么处理呢?比如一个tablet挂了再起来,此时之前写的sst可以重用吗?如果FE节点挂了呢?)
Hologres的一致性等级是read-your-writes,每个client保证能看到自己刚写下去的数据,具体做法是每个写请求会返回一个LSN,client下次读的时候就可以带上这个LSN。
每个TGS会维护一个LSNref,是需要支持MVCC的最老的version,在flush和compaction时所有低于这个LSN的数据都可以按key合并,大于等于LSNref的数据都需要保留所有版本,不能合并。
目前每个TGS都同时支持读写,未来Hologres计划做只读的TGS以分担读压力,有两种类型:
- 与主TGS完全sync的replica,数据保证是最新的,缺点是所有写入都是2PC(但repilca上不用落盘)。
- 部分sync的replica,只保证meta file是最新的,这样还没flush下去的数据是不可见的。
当有TGS挂掉时,coordinator会接到通知,之后会hold一些请求等TGS恢复。
Row and Column Tablet
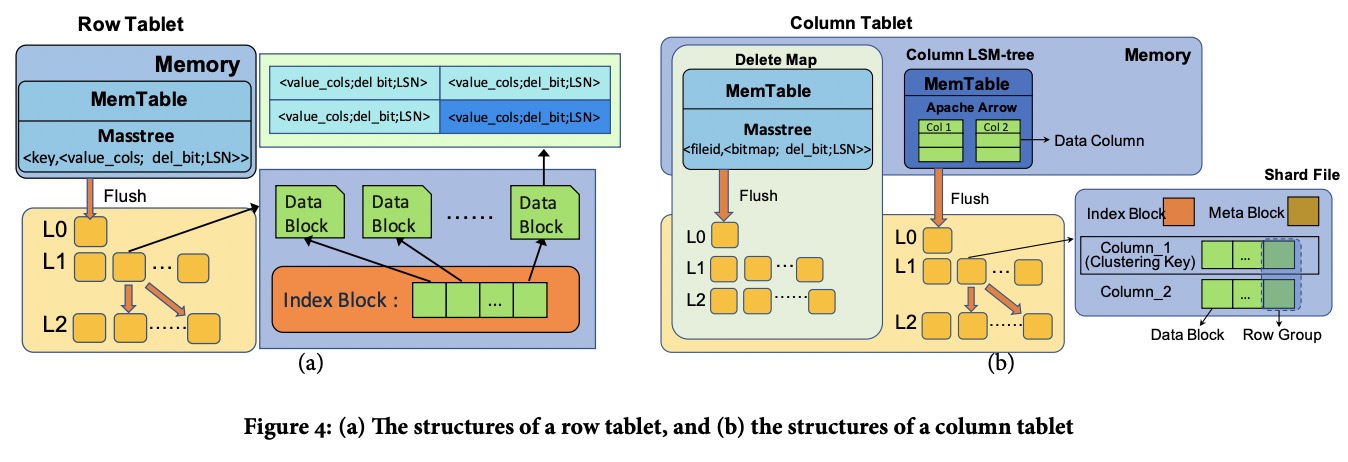
Row Tablet与LevelDB等差不多,区别在于它的memory table没有用SkipList,而是用了Masstree,后者对cache更友好,高并发读时性能更高。
Column Tablet分为两部分,一个column LSM树,一个delete map。
每列在LSM的内存部分对应一个Apache Arrow,数据按写入顺序排好;磁盘部分就是标准的行列混合模式,即文件内按rowkey排序,分为若干个row group,每个row group内按列写为若干个data block。
shard file的meta block包含:
- 每列的data block的偏移,每个data block的range和编码。
- 文件的压缩算法,总行数,LSN,key range,每个row group的first key。
delete map是一个Row Tablet,其中key是shard file id,value是一个bitmap加LSN,表示这个LSN下对应文件的哪些行被删掉了。
在读的时候,Hologres会先按shard file的min和max LSN来判断要不要过滤掉文件。对于有数据要读的文件,Hologres会先从shard file中读出LSN列,构造一个备选bitmap,再从delete map中读出所有小于等于LSNread的bitmap,合并起来后得到可见的行。
在读Column Tablet中每个shard file可以自己确定哪些行是要的,而不需要参考位于其它level的shard file,因为delete map可以知道每个shard file直到LSNread有哪些行被删掉了。
在写Column Tablet时,insert很正常;delete会对所有包含这行的shard file写一笔(也解释了上段话);update被实现为一次insert加一次delete。
Column Tablet的实现保证了一行只会存在于一个文件中,这样扫描就可以非常简单,而不用担心两个文件的数据有重叠。
Hierarchical Cache
Hologres中有三级cache:本地的SSD Cache、Block Cache、Row Cache。其中Row Cache缓存的是最近Row Tablet的点查的结果。
Query处理
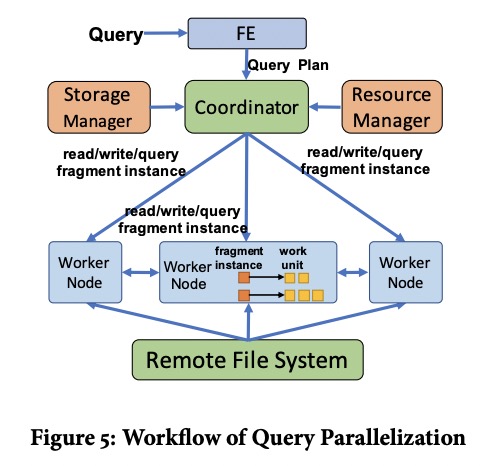
Hologres的FE节点会将Query转换为DAG,再将DAG按shuffle边界切为多个fragment。fragment有三种,read、write、query,其中query fragment表示非读非写的算子(迷惑)。每个fragment随后被并行化为多个fragment instance。
coordinator负责执行这个DAG,其中read和write fragment会被发给对应的TGS所在的worker执行,而query fragment可以由任意worker执行,分派的时候会考虑到局部性和负载。
Execution
在worker上执行时,每个fragment instance对应一个worker unit(WU),是worker的执行单元。WU可以在运行期派生出新WU。
read fragment instance被映射为一个read-sync WU,获取所有shard file和memory table的一个snapshot,之后派生出若干个read-apply WU并发执行。
write fragment instance中所有非写的操作(可能包含flush什么的?)被映射为一个query WU,后面接一个write-sync WU来持久化WAL,随后派生出若干个write-apply WU分别更新tablet。
query fragment instance总是被映射为一个query WU。
Hologres封装了一种用户态线程Execution Context(EC)。每个worker上有三种EC pool:
- data-bounded pool可以支持WAL EC和tablet EC。其中每个TGS有一个WAL EC,每个tablet有一个tablet EC。WAL EC中执行write-sync WU,tablet EC中执行write-apply和read-sync WU。
- query pool可以执行query或read-apply WU。
- background pool可以执行其它的后台任务,如flush和compaction等。
每个EC有两个task queue,一个lock-free internal queue放自己提交的task,一个thread-safe submit queue放其它EC提交的task。调度EC时会将submit queue中的task移到internal queue中。
EC也可以被cancel或join(类似go的Context?)。
Hologres中另有一类stub WU用来与其它系统通信。如需要运行UDF时,Hologres会与PostgreSQL进程通信,保证进程隔离。
Scheduling
Hologres中请求处理是基于pull的,coordinator会反复去worker上拉数据。在此基础上Hologres实现了反压和预读两种优化。
(Load Balancing、Scheduling Policy、Experiments略过)