原文:Pebblesdb: Building key-value stores using fragmented log-structured merge trees
TL;DR
PebblesDB在LevelDB(实际是HyperLevelDB)的基础上,借鉴了SkipList中的guard概念,提出了一种Fragmented Log-Structured Merge Trees(FLSM),将整个fileset分成了多层的,层内多个不重叠的区间,每个区间内可以有多个文件。这样compaction可以只在level i做,而不涉及level i+1,从而显著降低了写放大。代价是读的时候从level 1开始每层都可能引入多个文件(对比LevelDB每层一个),开销会变大。PebblesDB因此也引入了一些优化以降低读路径的延时。
生产中有大量写多的workload,这些场景下PebblesDB的意义很大,且它的实践难度并不高,值得集成到现有系统中。
写放大
LevelDB和RocksDB是最常见的LSM存储引擎,它们的特点是:
- SST分为若干个level。
- Flush会生成level 0的文件,level 0的文件key range可以重叠。
- 从level 1开始文件key range不可重叠。
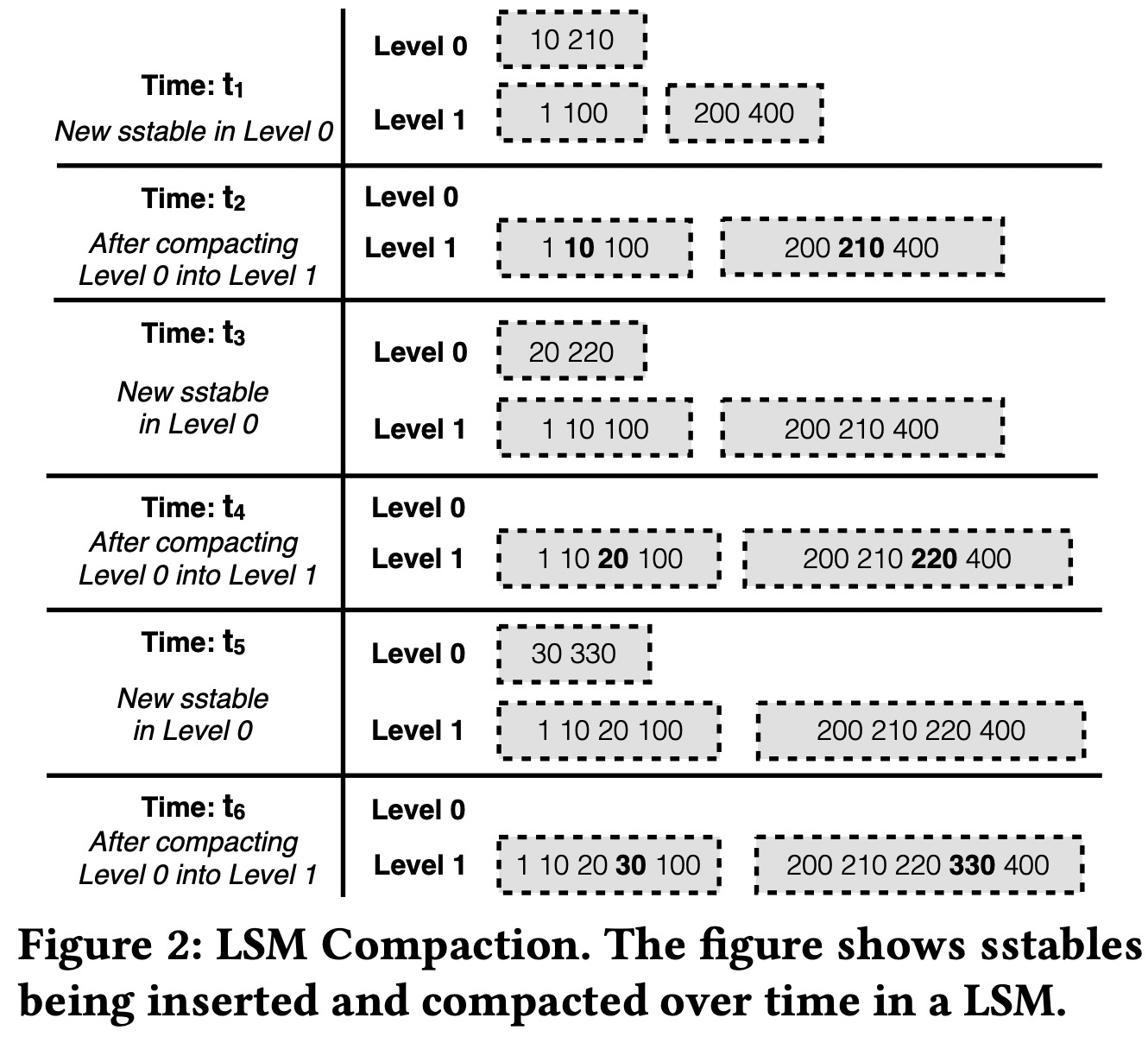
- Compaction会选择第i层的一个文件(如果是第0层,可以是与它有重叠的所有文件),加上第i+1层所有与之有重叠的文件,生成一个i+1层的文件。
这个过程中,一个key的整个生命期(从第0层到最高层),可能要经历多次重写,称为写放大。

图中可以看到LevelDB和RocksDB有着非常高的写放大系数。而FLSM在这方面有着非常好的表现。
传统的Leveled Compaction如此之大的写放大是因为它要时刻保证每层的严格有序。
写放大一方面会占用磁盘带宽,另一方面会导致compaction不及时而影响正常的写请求处理。
RocksDB中的Universal Compaction(或称Tiered Compaction)的思路是第i层做compaction时不要涉及到第i+1层的文件,从而控制写放大(每层只需要一次重写)。但这是以牺牲读性能为代价的——每一层的文件都是可能重叠的。
Fragmented Log-Structured Merge Trees
传统的Leveled Compaction保证了每层的严格有序,代价是写放大;Tiered Compaction不保证这点,降低了写放大,但增加了读放大。FLSM在其中寻找到了一个平衡点,每层整体有序,局部无序:每层分为若干个不重叠的连续的区间,称为fragment,区间之间显然是有序的,每个区间内可以有多个文件,相互不保证顺序。
每个fragment的文件数量或大小超过一定阈值后就会触发compaction,新生成的文件从第i层下移到第i+1层。这次compaction不会涉及第i+1层的已有文件。
为了保证文件从第i层移入第i+1层时既不需要与第i+1层的文件做compaction,又不破坏区间性质,FLSM借鉴了SkipList中的guard,使用guard来划分区间,保证第i层的guard也会是第i+1层的guard。
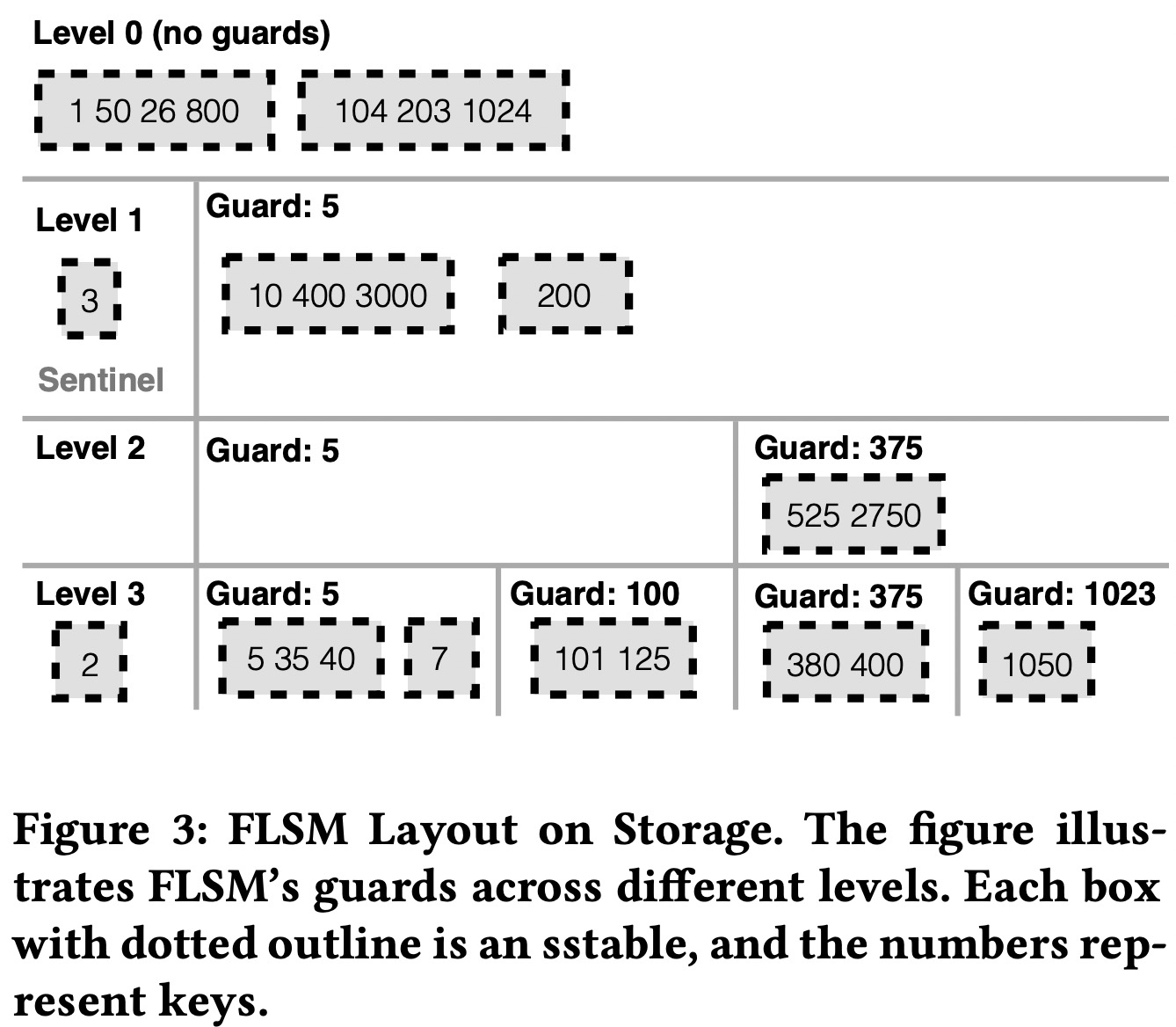
与SkipList类似,FLSM中guard也是在插入时随机选取,一个key是第i+1层开始的guard的概率是第i层的概率的B倍。
Guard生成后是异步生效的:下次compaction时才会根据新的guard列表来切分文件。被切分的文件会被移到下一层。
理论上guard也是可以删除的,但实践中并没有发现空的fragment会对性能产生影响:都被过滤掉了。但当文件在fragment之间分布不均匀时,通过删除guard来合并fragment是有价值的。Guard的删除也是异步生效的,被合并的两个fragment的文件既可以停留在第i层,也可以下移到第i+1层。
Guard不一定需要被整个删掉,可以只删掉它的最上面k层。
FLSM的缺点与Tiered Compaction类似,局部的无序也会带来读放大,尤其是范围读。应用以下几种优化可以提升读性能:
- 激进的compaction策略,从而减少需要
seek的文件数。 - 并行
seek。但如果要读的block已经在cache中了,并行seek实际会降低性能。为此,PebblesDB只针对最底层文件使用并行seek。 - 文件级别而不是block级别的BloomFilter(这也是优化?)。
总体来看FLSM非常适合那些大量随机写的场景,但以下场景并不适合用FLSM:
- 数据量小,可以常驻内存的,此时FLSM的读放大对性能的影响会非常明显,而降低写放大的收益又没那么大。
- 顺序写场景,此时Leveled Compaction直接移动文件即可,不需要真正做compaction,而FLSM会在尾部一直生成guard,导致文件下移时仍然需要做compaction。
- 大量写之后立即大量小的范围读的场景,此时FLSM的开销要比RocksDB多30%。但一旦读范围变大,或读写交替进行,这种额外的开销就会降低甚至消失。
性能评估
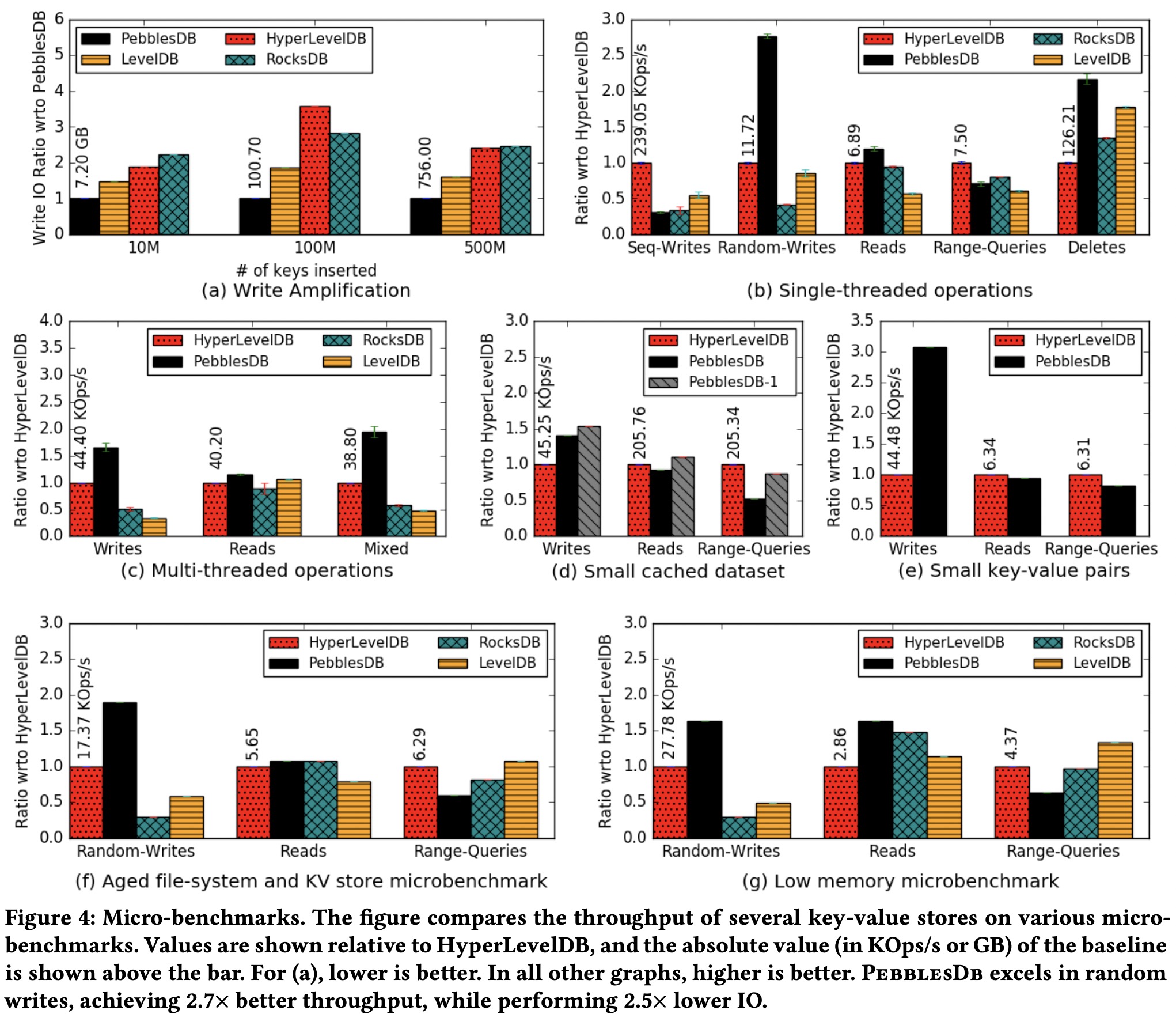
- 写放大:PebblesDB有明显优势。
- 单线程:
- 随机读写:PebblesDB在所有写场景都有明显优势;随机点查上PebblesDB因为允许更大的文件,文件数更少,且所有index block都常驻内存,性能略有优势。
- 顺序写:PebblesDB显然不适合这种场景。
- 范围读:PebblesDB因为需要读的文件数更多,在范围读上有着明显的劣势。
- 空间放大:大家都差不多。
- 多线程:
- 并发读写:PebblesDB有明显优势,因为写放大不严重,写吞吐就更高;FLSM的compaction更快,因此文件数下降更快,文件体积更大,读延时因此更低。
- 小数据集:当数据集可以常驻内存时,PebblesDB的劣势体现出来了。但如果把每个区间的最大文件数改为1,此时FLSM与LSM的性能就很接近了。
之前提到的三种读优化的效果:
- 不做任何优化时,PebblesDB的范围读吞吐下降66%。
- 启用并行
seek后,范围读吞吐下降48%。 - 启用激进的compaction后,范围读吞吐下降7%。
- 启用文件级别BloomFilter后,点查QPS提升63%。
YCSB测试的结论也差不多。
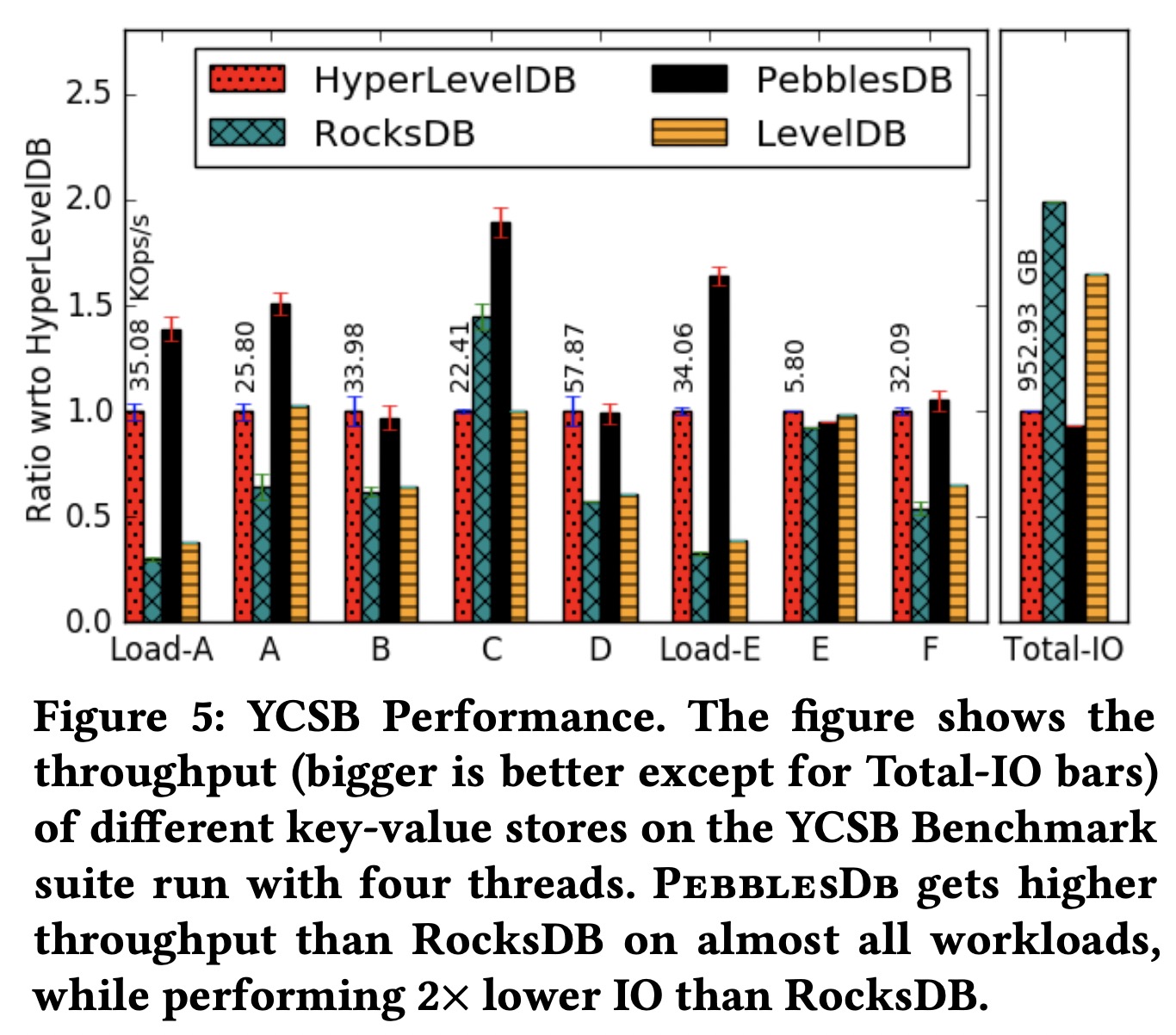
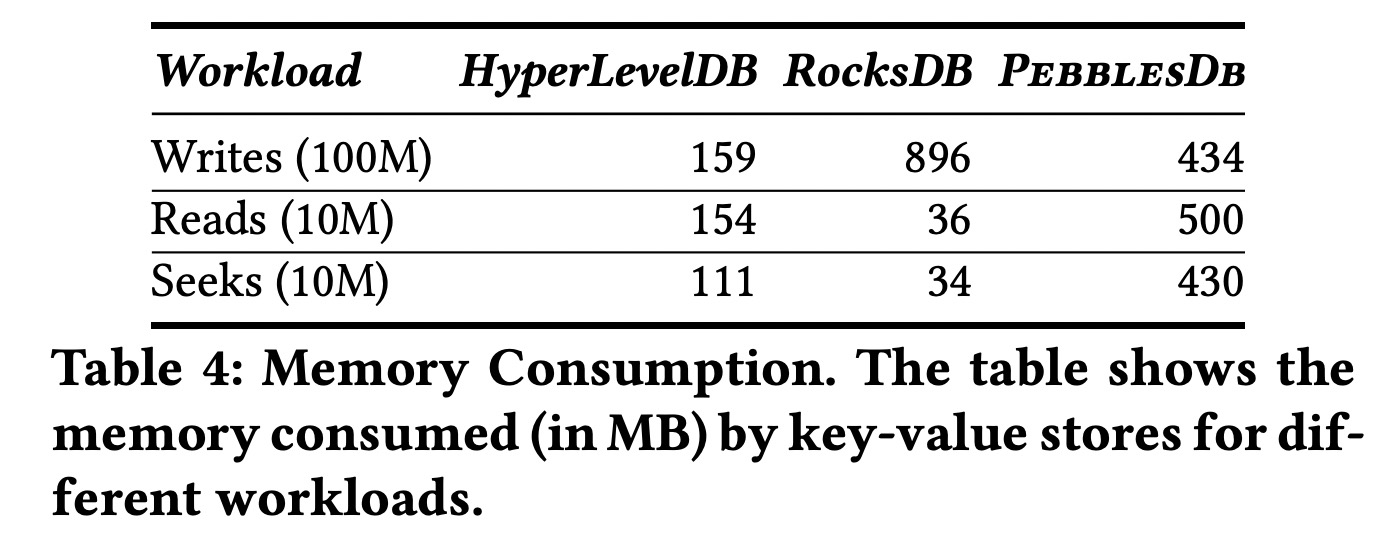
值得一提的是,PebblesDB的index block常驻内存,因此它的内存使用要高于LevelDB和RocksDB: