TL;DR
F1 query是一种federated query processing平台,它的特点是:
- 计算存储分离。
- 支持不同的存储引擎,如BigTable、Spanner、Mesa等,因此称为federated query processing。
- 使用三种不同的模式处理不同规模的query:单节点模式处理短的实时query;分布式模式处理中等query;远程模式使用MapReduce处理大型query。
- 使用启发式的query optimizer。
这里面最有价值的部分就是它如何融合不同的数据源与处理模式。
设计目标
F1 Query的目标是成为一种one-size-fits-all的查询引擎,同时能服务以下场景:
- 涉及很少行的OLTP风格的点查。
- 低延时大数据量的OLAP查询。
- 大型ETL pipeline,将多个源的数据转换合并到新的、支持复杂查询和报表的表中。
以下是对F1 Query的架构有重要影响的需求:
- 数据碎片化。不同的场景需要将数据存放在不同的系统中,而F1 Query要有能力查询这些来自多个系统的数据。
- 计算存储分离。Google的网络架构(Google的Jupiter网络支持数万节点之间两两通信)能最大化缓解因此带来的延时上涨(相比使用本地磁盘)。但如何减小延时波动仍然是未来F1 Query的主要挑战。
- 可伸缩性。通过前面说的三种处理模式,在数据量上涨时提高并发度。
- 可扩展性。F1 Query支持自定义函数(UDF)、自定义聚合函数(UDA)、自定义表函数(TVF)。
Overview
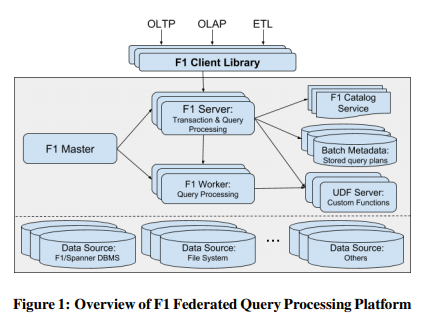
F1 Master负责监控和管理F1 Server,F1 Server负责接收和处理请求。当请求涉及的数据量较大时,F1 Server会将任务转交给若干个F1 Worker,自身变成coordinator。
F1 Server和Worker都是无状态的。
F1 Server在解析请求过程中会把它涉及的数据源提取出来,如果其中有任意数据源不在当前datacenter,且有其它F1 Server位于更靠近数据源的datacenter,当前Server会将最适合的Server集合返回给client。即使在高速网络下,选择更近的datacenter仍然能对延时产生巨大影响。
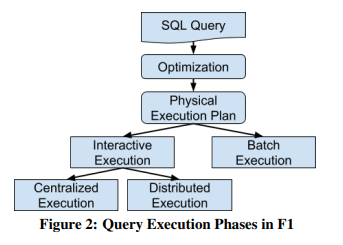
数据量较小时,接收请求的F1 Server直接处理掉这个请求,称为集中模式;中等数据量时,接收请求的F1 Server作为coordinator,协调若干个F1 Worker处理请求,称为分布模式;批处理模式下F1 Server会启动一个远端的MapReduce任务,并将执行情况保存在一个单独的仓库中。
F1 Query支持的数据源有:
- 其它数据系统,如Spanner、BigTable、Mesa。
- Colossus上的行存(RecordIO)或列存(ColumnIO、Capacitor)文件。
- CSV等文本文件。
F1 Query使用一个全局的目录服务记录不同数据源的元信息。client也可以在运行时通过DEFINE TABLE来提供数据源的元信息。
1 | DEFINE TABLE People( |
用户可以使用TVF来接入自己的数据源。
用户可以使用CREATE TABLE来创建由F1 Query托管的表,或用EXPORT DATA导出数据。
F1 Query支持SQL 2011标准,加上Google针对嵌套类型(Protobuf)的支持。
交互式执行
单线程执行
集中模式下F1 Server会使用单线程执行,以pull模式每次拉8KB数据。
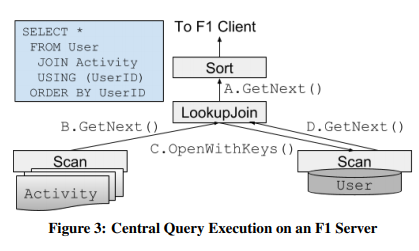
执行计划的叶子节点通常是Scan,不同的数据源支持不同的Scan,有的只支持全表扫,有的支持index查询。有些数据源支持下推一些简单的非主键的filter。所有数据源都支持直接在源端解析pb。
F1 Query支持多种join,如:
- lookup join,用左边读到的key,去右边做index lookup。
- 多级hash join,可以在Colossus上写临时文件。
- merge join,需要两边有相同的key order。F1 Query还可以把merge join下推到Spanner里,使用它现成的机制。
- array join,形式为
JOIN UNNEST(ARRAY)。
分布式执行
如果数据源较大,F1 Server会将整个查询计划分为若干个fragment,每个fragment交给一组F1 Worker线程执行。每个F1 Worker是多线程的,因此同一个Worker可能同时处理同一个query的不同部分。
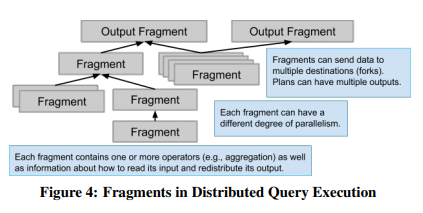
优化器以自底向上的方向计算fragment的边界(哪些算子属于同一个fragment)。每个算子有自己的分片规则(如按某个field hash),如果相邻算子的分片规则相兼容,就会被分到同一个fragment中,否则会在它们中间插入一个exchange算子,将它们分到不同的fragment中。
每个fragment可以有不同的并行度,也是自底向上计算的,从input开始,多个input的算子会取input中最大的并行度。
分片策略
数据在跨越fragment边界时会由exchange算子重新分片,整个发送过程使用RPC完成(不物化)。这种RPC模式能很好地支持每个fragment有数千分片。需要更高的并行度就要切换到批处理模式了。
有些算子会跨fragment执行,如lookup join与它的左input在一个fragment中,而hash join通常有多个fragment,每个有多个分片。
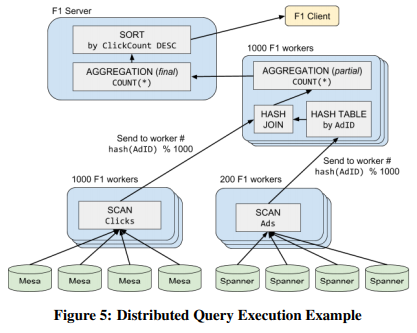
aggregation通常需要先分片做预聚合,再汇总到一个Node上做最终的聚合。
同一个input或fragment可以有多个下游,针对每个下游它可以有不同的分片方式,且保证数据只算一次。
针对执行过程中可能的死锁(如self-join),exchange算子会先在内存中缓存数据,再在所有下游都阻塞时将数据写到Colossus上以解开循环依赖。
性能考量
F1 Query中的性能问题主要是由数据倾斜和读取数据源方式不合理导致的。hash join对两边的热点key非常敏感:接收方可能数据量太大溢出到磁盘上,发送方可能消耗太多cpu和网络资源。如果其中一方数据量很少,F1 Query支持broadcast hash join,将它的拷贝发送给所有参与的worker。
最基本的lookup join的实现是一个一个key做lookup,考虑到延时长尾,这么做就太慢了。F1 Query可以缓存若干行之后批量做lookup,这样还可以减少对相同key的重复的lookup。scan算子也可以用类似的方法来提速——将对相同数据源分片的多次访问合并为一次。如果对数据源分片的请求数量超过了它能服务的并发数,这些请求可以乱序执行,因此能隐藏掉底层存储系统的延时长尾——慢请求在处理的同时,快请求也一直在处理。
如果直接将lookup join算子与它的左输入放到一起,也可能产生倾斜和非预期的数据访问,比如根本没办法聚合相同的key。为此,优化器可以将左输入再次分片,分片函数可以有多种。像Spanner和BigTable这样的key range分片的数据源可以得益于基于key range的分片方法。如果想利用这一点,我们可以把所有destination fragment按静态的key range进行分片。
F1 Query采用了一种动态分片,即各个输入源按自己的数据进行分片(接收端仍然和左输入源一起)。基于观察,一个数据源的数据分布通常与整体数据分布类似。这样分片的数据在worker之间更均匀,也能自适应地将热点key分散到多个接收分片。
F1 Query的算子通常尽可能地在内存中做流计算,而不是checkpoint到磁盘上。配合有激进的缓存机制的数据源,即使是复杂的分布式query也可以在几十或几百ms内完成。client端会重试失败的查询,但对于长时间的查询,分布式执行不够了,需要批处理了。
批处理
对于长时间的ETL,F1 Query会启动一个远端的MapReduce任务,从而解决worker出错问题。这个模式下F1 Server会定期查询MapReduce任务的状态。
批处理模式面临以下挑战:
- 交互模式下所有fragment会同时激活,因此可以用RPC通信,而在批处理模式下就不行了,需要有不同的通信方式。
- 需要有容错机制来持久化查询的中间状态。
- 需要有更上层框架来追踪所有的MapReduce任务。
一次query中,每个fragment都可能映射为一个MapReduce任务,输出会被写到Colossus上,提供足够的容错性。F1 Query借鉴了FlumeJava的MSCR优化,多个算子可以聚合到一个mapper或reducer中。针对map-reduce-reduce类型的任务,F1 Query会插入一个占位的mapper,变成map-reduce-map<identify>-reduce。未来可以使用像Google Cloud Dataflow这样的系统来处理map-reduce-reduce任务(用Spark或Flink都可以)。
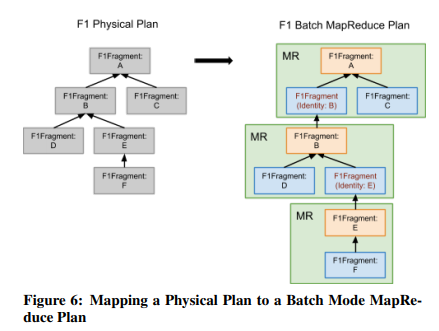
交互模式下整个query是以pipeline的形式进行的,上下游算子是并行执行的。批处理模式下要所有上游算子的输出都持久化到Colossus上,下游MR才能启动。但不依赖的MR任务可以同时执行。
为了减少批处理模式下exchange算子要持久化的数据量,F1 Query可以将hash join替换为lookup join。针对那些小,但没小到可以broadcast的输入源,或是有明显倾斜的输入源,批处理模式下可以将它们持久化为SSTable,做磁盘lookup,同时使用分布式cache以减少IO次数。
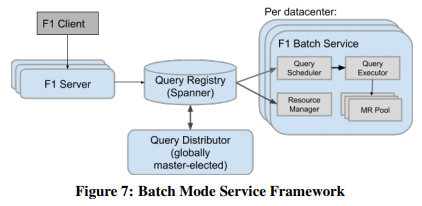
其它用于追踪MR任务的上层框架如图:
优化器
F1 Query中所有查询计划的优化都会应用到三种模式中。
F1 Query的优化器设计上借鉴了Cascades风格,且与Spark的Catalyst planner共享一些设计原则(两个团队在早期设计阶段有交流)。优化器先将SQL解析为AST,再将AST转换为关系代数计划。这阶段F1 Query会启发式应用一系列规则,直到满足某种条件,从而产生最优化的查询计划。
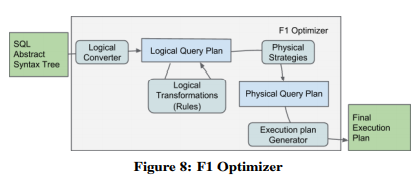
值得注意的是F1 Query的优化是以启发式规则为主的,辅助以基于静态统计信息的规则(如果存在的话)(可能是因为数据源不支持统计信息)。
在应用转换AST的规则时,每种规则要么运行一次,要么反复运行直到满足退出条件。F1 Query支持的规则有:
- filter下推。
- 常量折叠。
- 属性裁剪。
- 常量传播。
- outer join窄化(缩减范围?)。
- 排序消除。
- 公共子计划消除。
- materialized view重写。
逻辑计划后面会被转换为物理计划。转换过程被封装为若干个strategy模块,每种strategy会试图匹配上一种特定的逻辑算子组合,之后为这组算子产生物理算子。F1 Query会用可以追踪数据属性的类来表示物理算子,包括数据分布、顺序、唯一性、估计的势(cardinality)、相比其它数据源的波动性等。优化器会用这些属性来决定何时插入exchange算子。如果任意scan的并发度超过了集中模式的处理能力,整个查询会变成分布式执行。
优化器产生的查询树的算子是不可变的,每种规则只能产生新算子以修改查询树,这么做的好处是可以生成用于探索的计划(不确定要不要最终应用到查询树上),以及重用子树。所有算子都只会在内存中构造数据结构,并在临界区外析构,从而避免算子的构造和析构对性能产生影响。
优化器使用python和jinja2代码生成了所有算子的约6000行C++代码。生成的代码支持DSL,且为每个算子都产生了一个hash函数,用于比较两个节点的相等性。还可以把生成的查询树写到C++容器中,方便测试。
得益于代码生成和C++模板的使用,生成的代码性能与手写的C++相当。
扩展性
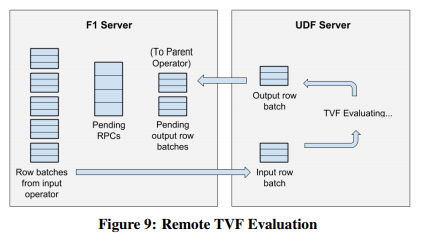
F1 Query支持多种语言的UDF。SQL和Lua的UDF会被直接包含在query中一起解析掉。其它语言的UDF会被编译为UDF Server,查询过程中与F1 Server通过RPC通信。UDF Server的生命期完全由client控制,可以和一次查询相同,也可以长期运行。
UDF只可以用于projection算子。通过pipeline发送UDF请求,F1 Server和UDF的RPC开销就可以被掩盖住了。
UDF Server也支持UDA(自定义聚合函数)。聚合算子会在内存中维护要交给UDA聚合的数据,当内存buffer满了之后再把这些数据批量发给UDF Server。
TVF(自定义表函数)既可以是以标量和表为参数的函数,也可以是一段SQL(此时与materialized view类似)。
1 | SELECT * FROM EventsFromPastDays( |
高级特性
F1 Query会在性能降级的时候将整个降级过程平滑化,避免出现陡峭的曲线,导致影响查询的稳健性。降级可能来自非预期的数据模式(数据量、选择度等),比如原本认为可以内存排序的数据,当数据量超出预期,需要转为有磁盘参与的排序算法时,F1 Query会只将必要的部分放到磁盘上,而不是将整个排序都改掉。