原文:Omid, Reloaded: Scalable and Highly-Available Transaction Processing
Omid三部曲:
- Omid: Lock-free transactional support for distributed data stores
- Omid, Reloaded: Scalable and Highly-Available Transaction Processing
- Taking Omid to the Clouds: Fast, Scalable Transactions for Real-Time Cloud Analytics
这是Omid的第二篇(2017年),相比2014年的初版,它在规模和可用性上做了增强。
主要改动有两个:
- 增加了meta table,将事务的commit信息下放到存储层,减轻了控制层的的负担。
- Status Oracle(SO)进一步变为Transaction Manager(TM),负责timestamp分配(TSO)、冲突检测(SO)与写meta table。
相比其它分布式事务的实现,Omid控制层与数据层切分得非常干净,很适合云上部署。
相比Omid 14中事务meta完全放到TM的内存中,Omid 17独立出来的meta table能支持更大规模,在failover时恢复更快(Omid 14需要从头恢复WAL)。
Omid实现了snapshot isolation,相比Spanner的external consistency(strict serializable isolation)和CockroachDB的serializable snapshot isolation,Omid的优点是只读事务不会abort(但这只是设计的tradeoff吧?)。
(Omid很容易扩展为支持write snapshot isolation,类似于CockroachDB的SSI,参见[笔记] A Critique of Snapshot Isolation)
Omid 17的架构:
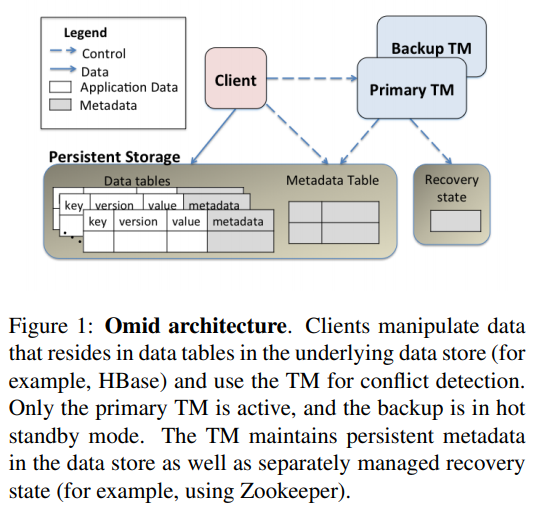
TM是主备架构,primary使用了lease,且能容忍小段时间两个primary的重叠,而不影响client访问。
Omid 17的最大区别是除了内存,TM还将事务的提交信息写到了commit table(CT)里,后者与数据一样存储在HBase中。

与此同时数据中也像Percolator一样保存了对应事务的commit_ts。commit_ts字段如果为空表示对应事务可能还未提交。
事务提交后所有修改过的行的commit_ts都会被更新,之后CT中对应的行就可以删掉了。因此CT中只会有已提交但还没修改完所有行的事务,不会很大。有后台任务会定期扫描这张表并推进。
有了CT后,client在判断inSnapshot时就可以直接通过CT,不再需要像Omid 14那样由TM返回事务的commit records。

算法1中值得注意的点:
- 为了减轻client维护write set的负担,
Put中只记录64位的hash(代价是引入了很小的false abortion)。 - 在
GetTentativeValue中,考虑到数据中的commit_ts与CT有并发修改的corner case,如果CT中没有这个事务,我们需要再回头检查一下数据。 Commit中,根据TM返回不同的状态,client可能执行清理,也可能执行提交后的修改。注意事务状态的source of truth是CT,即使这一步client失败了,也不会影响后续操作的结果。
接下来是TM的修改。
Omid 17中TM引入了多线程来处理并发的client请求,因此也引入了一些实现上的复杂度:
Begin需要等待其它线程处理完所有更小ts的事务的提交,从而维持ts的单调增。ConflictDetect引入了分桶的hash table,每个桶的检测冲突与修改key对应的ts是原子操作,需要所有桶都返回COMMIT,整个事务才能COMMIT。注意这里又引入了一些false abortion:
- key可能被hash。
- 如果某个事务最终被认为冲突而abort,已经检测过的前K个桶的状态也不会rollback。

为了控制hash table的大小,我们只需要保存那些晚于某个活跃事务start_ts的已提交事务信息。但这仍然不能保证有个上界。Omid的做法是每个桶只保留固定数量的slot,如果slot满了且要提交的事务的start_ts小于这个桶的最小的commit_ts,这个事务也被认为冲突。这又是一个false abortion的地方。
TM还会维护一个commit_ts的low water mark,用在两个地方:
- 数据中每行低于LWM的版本最多保留一个,更低的会被清理掉。
- 事务提交时如果start_ts低于LWM,直接返回ABORT(引入false abortion)。
(文章中没有细说LWM的提升规则)
TM的高可用是通过主备实现的,需要在主备切换时避免出现以下不一致情况:
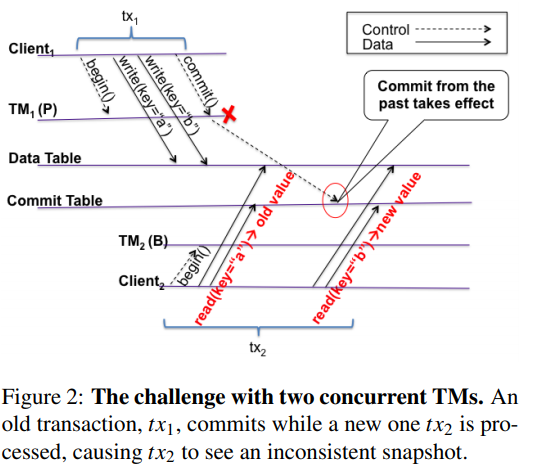
为了避免引入昂贵的同步开销,Omid的高可用方案不阻止两个primary同时工作,而是通过以下性质的保证来避免数据的不一致:
- 所有TM2分配的ts都高于TM1分配的ts(ts不回退)。
- 一旦有事务以ts2开始,不再会有以ts1(ts1 < ts2)提交的事务能修改任何数据行(但仍然可以提交),且
- 一旦有事务读到commits_ts为nil的行,它能确定这行会不会在未来以一个比它的start_ts更小的commit_ts提交。
P1保证了ts是单调增的。P2保证了事务的read snapshot不可改变。P3保证了事务可以确定它的read snapshot。因此这三个性质可以保证正确的SI。
一种basic方案如下:
- 为了保证P1和P2,TM会持久化一个最大已分配ts,maxTS,当自认为是primary的TM发现maxTS比自己以为的大,就主动退出。
- 为了保证P3,我们允许client在发现commit_ts为nil的行时,直接尝试abort对应的事务,这需要在CT中增加一列invalid,并依赖于存储层的put-if-absent。

接下来讲优化。
为了降低提升maxTS的开销,TM会一次分配大块的timestamp,称为epoch。并且,为了降低检查maxTS的开销,TM会维护一个lease。当secondary TM发现lease过期而变成primary,它会直接提升maxTS到下个epoch,这样就不需要等旧primary退出了。
(这里的问题是lease依赖于本地时间,无法完全保证正确性)
检查maxTS保证了P1和P2,但还没有保证P3(考虑到TM切换过程中commit已经发出去了)。这里我们可以限制检查P3的场景:
- 对于commit,只在TM的lease过期时检查。
- 对于read,只在start_ts属于上个TM分配的epoch时检查。
最终我们得到了Omid 17的高可用算法。
