这篇文章提出了一种保证了serializability的write-snapshot isolation(WSI)。相比snapshot isolation(SI),WSI是serializable的,且有着不弱于SI的并发性能。相比serializable snapshot isolation(SSI),它的检测成本更低,性能更高。
Introduction
事务ACID中的I即Isolation,定义了并发事务间的相互作用。最高的isolation级别是serializability(可串行化),这个级别保证了系统的行为如同是将所有事务按某个顺序串行执行的结果。但众所周知的是serializability实现开销巨大,且严重限制了系统的并发能力。
许多实际系统因而采用了另一种可以达到高并发的isolation,snapshot isolation。这种isolation下,每个事务只能看到它开始时的DB状态(一个snapshot)。只读事务不会与其它事务冲突,因而不需要任何锁机制。但两个修改相同元素的写事务之间仍然可能有冲突,称为写写冲突(write-write conflict)。
基于锁的snapshot isolation实现非常直接,每个事务在修改元素前尝试加锁,如果加锁失败则abort(或wait)。但snapshot isolation相比serializability还欠缺一项,即检测出读写冲突(read-write conflict)的能力。然而检测RW冲突会带来明显的开销,因为读事务占了典型workload的大头,且最直接的RW检测还可能导致只读事务abort,限制了系统的并发能力。
一种无锁的snapshot isolation实现(omid前身)[1]中每个事务都要将自己的修改列表发给中心节点(status oracle)来检测WW冲突。这种设计同样也可以用来检测RW冲突,只要每个事务将自己读过的row也发给SO即可。
这篇文章分析了WW和RW冲突,得出结论:
- SI的WW冲突超出了serializability的需要,即允许WW冲突也可以实现serializability。
- 只需要检测RW冲突就可以满足serializability。
作者随后提出了write snapshot isolation,只检测RW冲突(不需要处理WW冲突),如果一个事务读过的数据在提交前被其它事务修改了,这个事务就需要abort。
作者预期WSI能达到SI同等的并发能力:
- WSI和SI都不会abort只读事务,而这就占据了大部分事务。
- RW冲突和WW冲突都有假阳性(事务冲突但仍然满足serializability)。
(WSI因此具备和SI同等级的性能,且拥有更高的isolation级别,但似乎仍然达不到serializability,还需要gap锁之类的机制来避免conditional update中的phantom read)。
Snapshot Isolation
Snapshot isolation的机制略。SI的优势在于一个事务的写不会阻塞其它事务的读。
两个事务Ti和Tj发生WW冲突的条件是:
- 空间上重叠:都写同一行r。
- 时间上重叠:Ts(Ti) < Tc(Tj)且Ts(Tj) < Tc(Ti)。
如下图中txnn和txnc存在WW冲突。

基于锁的SI实现有Percolator。当一个事务要写被锁住的行时,可以有不同实现:wait;自身abort;强行abort掉占有锁的事务(wound-wait)。
作者本身倾向于[1]这样的无锁的SI实现。它会依赖于一个中心化的SO。作者认为SO可以达到50K的TPS,不太会成为并发的瓶颈(严重怀疑)。
下面是这种实现的commit过程。

这里关键是如何管理每行的commit ts。最直接的想法是由SO本身管理,但这样扩展性不好。也可以写回DB[1]或由client来维护[2](更详细的分析可以看omid[3][4][5])。
Serializability
Q1:避免WW冲突是serializability的充分条件吗?
显然不是,避免WW冲突也没办法避免write skew:
1 | H 1. r1[x] r2[y] w1[y] w2[x] c1 c2 |
H1中两个事务分别读了对方要写的行,显然没有WW冲突,但不满足serializability。
1 | H 2. r1[x] r1[y] r2[x] r2[y] w1[x] w2[y] c1 c2 |
H2中两个事务都读了x和y,想要保证x + y > 0,假设初始x = y = 1,T1将x改为-1,T2将y改为-1,两个事务在SI下都会成功,不满足serializability。
Q2:避免WW冲突是serializability的必要条件吗?
SI能避免ANSI SQL标准中定义的以下异常:
- 脏读(dirty read),读到了未提交的值。
- 不可重复读(fuzzy read),读到了已被其它并发事务删除的值。
- 幻读(phantom),满足一组条件的数据集被并发事务修改且被读到。
另外它还能避免写丢失(lost update)异常:
1 | H 3. r1[x] r2[x] w2[x] w1[x] c1 c2 |
但注意如果T2没有读x,则不构成写丢失异常:
1 | H 4. r1[x] w2[x] w1[x] c1 c2 |
这是因为在事务重排序后,H4等效于:
1 | H 5. r1[x] w1[x] c1 w2[x] c2 |
显然H5是满足serializability的,H4因此也满足。
H4的例子就说明WW冲突可能会阻止一些合法的、满足serializability的场景。
结论就是:避免WW冲突既不是serializability的充分条件,也非必要条件,我们需要重新审视SI要避免WW这一观点。
Read-Write vs. Write-Write
SI实际应该称为RSI(read-snapshot isolation),因为事务的读永远不会被打断,每个read对应的snapshot是隔离的(isolated)。而对应地,WSI中事务的写永远不会被打断,每个write对应的snapshot是隔离的。但如果它的read set被其它事务修改了,就没办法提交了。
WSI中Ti与Tj冲突的条件是:
- RW空间重叠:Tj写行r,Ti读行r。
- RW时间重叠:Ts(Ti) < Tc(Tj) < Tc(Ti)。
注意到WSI中只有写的事务(即blind write)是不会被打断的。

上图中:
- Tn和Tc’’在SI的定义中时间是重叠的,但在WSI的定义中时间是不重叠的:Tc’’的提交时间晚于Tn。
- Tn和Tc存在RW时间重叠,但RW空间不重叠:Tn读行r,Tc写行r’。
- Tn和Tc’存在RW时间和空间重叠,必须abort掉其中一个。
我们知道只读事务占了实际workload的大头(只读事务占了TPC-E的77%,Megastore超过86%)。为了优化只读事务的场景,注意到只读事务的commit不会修改任何数据,所有数据的版本由start ts决定,因此可以把commit ts设置为不小于start ts的任意值,因此它不会与任何事务有时间重叠。因此WSI中只读事务不参与冲突检测,也就不会abort。

Q1:避免RW冲突是serializability的充分条件吗?
我们需要证明任何满足WSI的历史都等价于某个满足serializability的历史。
我们保证以下顺序不变:
- 一个事务内的操作顺序。
- 事务的提交顺序。
这样如果一个事务在两个历史中读到的snapshot不变,它提交时写下去的内容也不变。为了保证这种,我们可以再保证事务的开始顺序不变。
接下来我们需要避免事务间有重叠。做法是将写事务的所有操作都移到它的commit ts,只读事务的所有操作都移到它的start ts。因为WSI保证了不会有RW冲突,这种移动不会影响最终结果。
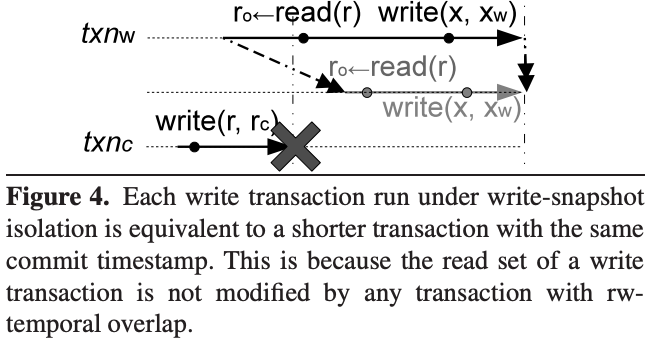
abort的事务不会对其它事务有影响,因此不参与讨论。
引理1:这样生成的历史是serial的。
既然每个事务的操作要么在commit时发生,要么在start时发生,且timestamp不重复,也就不存在并发事务,整个历史就是serial的。
引理2:新历史与旧历史是等价的。
已知只读事务读到的数据只与它的start ts有关,又知所有写事务的commit ts不变,因此每个只读事务读到的值不变。因此整个历史的结果是由写事务的提交决定的。已知所有写事务的提交顺序不变,那么只要保证它们读到的数据不变,它们提交的结果也就不变,新历史与旧历史就是等价的。
而WSI保证了一个最终走到提交的事务,它读到的数据不会在start ts到commit ts之间被修改,即使用commit ts来读与用start ts来读是一样的。因此新历史中每个事务读到的数据与旧历史相同。
结论:WSI是serializable的。
Q2:避免WW冲突是serializability的必要条件吗?
WSI相比SI的一个优势就是避免了一些serializable但WW冲突的事务被abort。但它也会abort其它有RW冲突但serializable的事务。
1 | H 6. r1[x] r2[z] w2[x] w1[y] c2 c1 |
H6会被WSI阻止,但它实际等价于:
1 | H 7. r1[x] w1[y] c1 r2[z] w2[x] c2 |
结论:SI和WSI都有假阳性,都会abort满足serializability的事务。
Lock-free Implementation of Write-snapshot Isolation

WSI的commit开销比SI要大,因为每个请求要同时包含读过的数据和要写的数据。
只读事务仍然要执行commit,但请求中不需要携带任何数据。理论上只读事务可以跳过commit,但这样SO就无法分辨正常的事务与client失败了。
这套实现是针对OLTP的,如果要用在OLAP中,障碍在于每个事务的读数据集会非常庞大,导致commit开销大,且abort概率也增加了。前者可以通过精简请求格式缓解,后者是本质问题,需要通过分离系统的TP和AP部分来解决(ingestion路径独立出来)。
Evaluation
后面的评测略过,这里只介绍一下作者的实现。作者使用了BookKeeper作为SO的WAL,HBase作为data store。整条路径为:读HBase;写暂存在client buffer中;SO使用BookKeeper记录redo;最终数据再写回HBase。