原文:Omid: Lock-free transactional support for distributed data stores
Omid三部曲:
- Omid: Lock-free transactional support for distributed data stores
- Omid, Reloaded: Scalable and Highly-Available Transaction Processing
- Taking Omid to the Clouds: Fast, Scalable Transactions for Real-Time Cloud Analytics
Omid的目标是为支持MVCC的分布式KV增加乐观事务(2PC)功能,实现snapshot isolation。
它的特点:
- 乐观锁(它称为lock-free)。
- 有中心化的Status Oracle。
- 依赖于client进行SI需要的判断。
这是Omid的第一篇paper(后面还有2篇),从后续paper来看,这篇paper的实现在规模上还是存在问题,但它确实解决了Percolator的延迟高(尤其是有事务失败时)的问题。
在Omid之前,Google的Percolator也实现了类似的功能,但[1]表示Percolator有以下问题:
- 数据与锁meta存在一起的做法导致了数据server负担过重,容易产生高延迟。
- 去中心化的设计导致一旦事务失败(如client宕机),一段时间内锁不能被及时清理,阻碍后续事务进行。
Omid使用了中心化的Status Oracle(SO),所有锁的meta由SO管理,与data分离,解决了问题一;中心化节点去除了分布式事务的必要性,大大降低了实现复杂度,也解决了问题二。
但中心化使得:
Omid解决(内存)容量问题的方式仍然是裁剪meta,但保留了SI需要的信息,因而保证了一致性。而在处理能力方面,Omid会将一个事务需要的meta信息轻量化地复制给client,允许client本地做SI需要的判断,从而分担了SO的处理压力。
这里面的关键点就是只读事务不需要它的start_ts之后开始的其它事务的信息,SO每次在回复client的get_timestamp请求时,都会带上距离上次请求之间的meta修改,这样client就可以在开始事务后本地构建出它需要的meta视图。
我们知道SI中判断两个事务冲突的规则是:
- 空间上重叠:都写同一行r。
- 时间上重叠:Ts(Ti) < Tc(Tj)且Ts(Tj) < Tc(Ti)。
那么为了做判断,需要的信息有Ts(开始时间)、Tc(提交时间)和writes(修改过的行)。
假设有和Percolator一样的TSO来提供全局唯一单调增的timestamp作为事务id,则SO不需要记录Ts,只需要记录每行对应的Tc。算法如下:

注意第6行,我们需要维护每个事务的Ts与Tc的映射,这样后续的事务Tr才能判断它读的行是否在它开始之前提交了(在它的read snapshot中):

Omid底层使用了HBase来存储数据,数据的版本是对应事务的Ts(注意不是Tc),因此client在完成一次读取时需要通过inSnapshot来判断哪些版本是需要过滤掉的。一种naive的实现就是向SO发送对应的请求:

下面开始讲Omid的设计。
为了限制内存使用,Omid只会保留最近NR个事务的meta,以及Tmax(不在内存中的最大的Ts),如下图。

当行r对应的lastCommit(r)不在内存中时,我们知道它也一定小于Tmax,因此有Tmax < Ts(txni)意味着lastCommit(r) < Ts(txni)。
由此我们得到算法3:

注意行2会导致一些合法的事务被abort,SO内存保留的事务越多,这种false positive概率越小。
接下来,我们需要让inSnapshot能在裁剪事务列表后仍然能正确工作。
Omid中维护了aborted和uncommitted两个事务列表,不在这两个列表的事务就默认是committed(得益于Omid的中心化设计,SO有所有事务的start信息)。这样所有事务就分成了四类:
- 大于Tmax的已提交事务,有commit_ts。
- 不大于Tmax的已提交事务,没有commit_ts。
- 位于aborted队列的事务。
- 位于uncommitted队列的事务。
为了控制两个队列的长度,Omid会:
- 在Tmax提升时将uncommitted队列中小于Tmax的事务abort掉(移到aborted队列中)。这意味着持续时间过长的事务会被提前中止掉。
- 在aborted事务对应的数据被清理后移除将事务从aborted队列中去掉。这种清理是由client主动发起的,并在完成后通知SO。
这样我们有了新的inSnapshot算法:

注意当前事务(txnr)的start_ts不可能小于Tmax(会被abort)。
接下来,我们来解决一下naive方案中依赖SO做inSnapshot判断的问题。
Percolator的做法是将commit_ts再写回到数据存储中(图4),但这样SO的工作量就非常大。Omid的做法是在处理getTimestamp时将事务meta返回给client,让client有足够的信息本地做inSnapshot的判断(图5)。
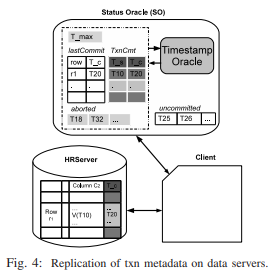
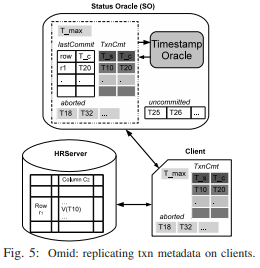
这种设计得益于以下信息:
- 大于start_ts的commit信息可以忽略。
- 数据不走SO,因此SO属于CPU密集应用,网络带宽不成问题。
getTimestamp返回的数据量通常非常小,再加点数据(压缩后)也能装进一个packet里,因此这种设计几乎没有额外开销(有点怀疑)。- 假设有N个client,每个client在每个事务过程中请求一次
getTimestamp,则每次返回的事务meta平均下来不会大于N。
对于每个事务,client只需要维护以下信息:
- Tmax。
- 介于Tmax与Ts间的已提交事务的start_ts和commit_ts。
- aborted列表。
注意client不需要维护lastCommit数据,而这个是最占SO内存的部分。
由此我们得到了优化后的Omid事务全过程:

(从2017年的paper可以看到SO还需要维护一个WAL,但这篇没有提)