原文:Mesa: Geo-Replicated, Near Real-Time, Scalable Data Warehousing
TL;DR
Mesa是一种面向Google Ads的特定模式数据的准实时数仓,而不是面向非常通用场景的离线数仓。Mesa的设计上偏向于高伸缩性和准实时响应,目标是保证简单query场景的高性能;相对地,Mesa不支持完整的ad-hoc查询(似乎也不支持SQL),可以支撑支持SQL的更上层系统(如MySQL、F1、Dremel)。
Mesa依赖Google的Colossus、BigTable、MapReduce,数据被水平分片并复制到多个datacenter。Mesa会批量导入数据,每行数据都有version,使用MVCC,周期性提升可见的数据版本。为了保证跨datacenter的更新一致性,Mesa还使用了基于Paxos的同步协议。
Mesa比较有特色的是它的聚合函数、数据版本管理、以及多datacenter同步。
设计目标
- 原子更新,更新完之前不被查询到。
- 一致性和正确性,需要提供强一致性和跨datacenter的可重复读。
- 可用性,不能有单点问题,能承受单个datacenter或region挂掉。
- 准实时更新,能每秒更新百万量级的行,并提供分钟级的跨datacenter和view的可见性。
- 查询性能,能服务需要低延时的在线业务,以及需要高吞吐的离线业务,点查的P99延时要在百ms这个量级,且每天的读吞吐能达到千亿行量级。
- 伸缩性,系统要能跟得上数据和查询规模的增长,要能支持千亿量级的行、PB量级的数据,并在数据大幅度增长时还保持更新和查询性能稳定。
- 在线变更数据schema和元数据,且不影响正常的读写请求。
存储层
Data Model
Mesa中数据按表组织,每张表的schema分为两部分,keyspace和valuespace,分别可以包含多列,但角色不同:keyspace唯一确定一行,key列都可以作为predicate;每个value列各自关联一个聚合函数F,查询时通过F来获得这列的聚合值,不作为predicate。
聚合函数需要能满足结合率,通常也满足交换率(但不要求)。
每张表也可以有若干个索引,每个索引的key column是主表key column的一个排列。
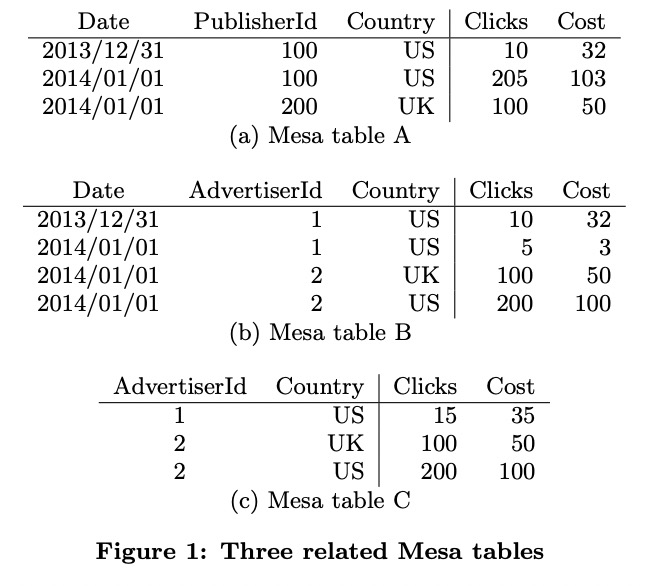
上面例子中,表A的key column有Date、PublisherId、Country,value column有Clicks和Cost。表B没有PublisherId列,但有AdvertiserId列。两张表的value column的聚合函数都是SUM。
表C实际是表B的一个materialized view:SELECT SUM(Clicks), SUM(Cost) GROUP BY AdvertiserId, Country。Mesa要求MV的聚合函数要与主表相同,因此也是SUM。
Updates and Queries
Mesa接受批量写入,每次写入时会带上版本号V(从0开始单调增)。
查询包含一个predicate P和最大版本n,Mesa会将所有匹配P的行的0到n版本的value聚合起来返回。Mesa支持的其它更复杂的查询也都是基于此实现的。
在对前面表A、B、C进行更新时,可以分别对表A和B更新(不同的行),表C会自动更新,也可以一次更新同时包含AdvertiserId和PublisherId,这样表A和B也会一起更新,但开销比较大(为什么?)。
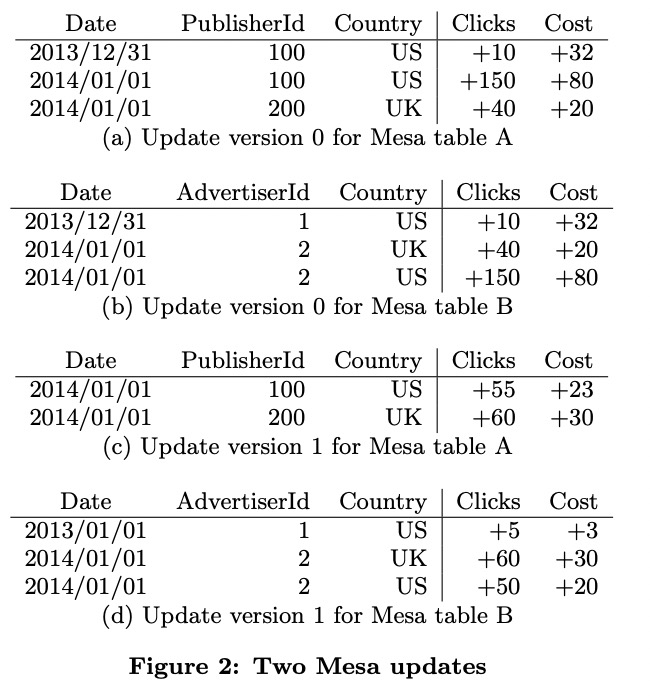
一次更新可能会涉及多张表和view,在结束之前这些数据都不可见,保证了查询的原子性。
Versioned Data Management
为了提高版本聚合的性能,Mesa将所有版本的数据进行了预处理,分为base、delta和singleton delta:
- base表示查询中能指定的最早的version。Mesa不可能永久保存所有version,因此它会定期将0-base的所有version聚合成一个值,比如一天之前的数据。
- delta指一个区间
[V1, V2]的聚合值。[V1, V2]和[V2+1, V3]可以合并为[V1, V3]。Mesa会在base之后维护若干个delta version,用于加速聚合。 - singleton指某个具体version,或
[V1, V1],它与delta version表示的范围是一样的。
Mesa会定期提升base,删掉老的base和无用的delta version、singleton delta。
Mesa的delta是分多层的,越近的delta的区间越小。

Physical Data and Index Formats
Mesa中文件都是immutable的,这样文件格式的设计就简化了很多,首先考虑空间效率,其次是支持快速seek和聚合。每表Mesa表都有一个或多个索引。
数据文件中的行都是排好序的,切分为多个row block,每个单独按列存格式编码和压缩,压缩时优先考虑压缩率和解压速度,压缩速度可以慢一些。
每个数据文件都对应一个block index文件。
系统架构
单datacenter实例
Mesa用BigTable保存元数据,用Colossus保存数据文件。
单个datacenter内Mesa实例分成了controller和worker。controller负责管理任务和维护元数据,包括每张表的待更新version与数据文件、delta compaction policy、每种操作类型最近涉及的entry等。
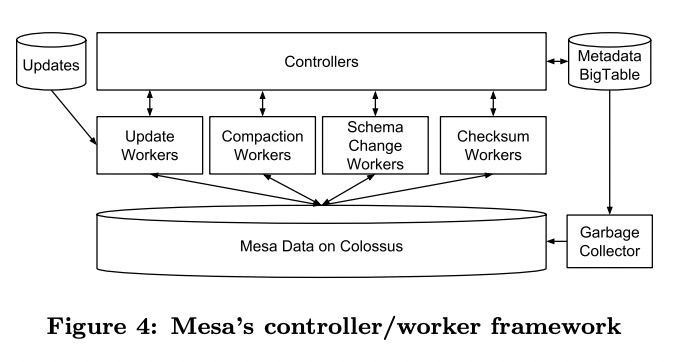
controller是按表做shard的,本身是无状态的,启动时会从BigTable中读出所有元数据,之后会订阅表的创建、删除操作,表的元数据本身只有controller能修改。
controller对于不同的操作都有单独的队列,交给不同的worker执行。单instance内部的操作如更新和delta compaction,controller自己就能发起;跨instance的操作会由外界模块向controller发送RPC触发。
每个worker会周期性从controller那里拉任务,拉到的任务会有一个lease,保证了慢worker不会永久占用任务。controller只会接受指定的worker传回的结果,保证了安全性。
Mesa同时服务于在线和离线业务,因此需要通过优先级来做隔离和资源分配。一个Mesa实例中的query server分为多组,每组可以服务的表都是相同的。分组的目的:
- 分批次升级而不影响在线服务。
- 可以将相同表的请求路由到同一组,允许预读和缓存Colossus上的数据。
- 方便不同组之间做load balance。
每个query server在启动时会将它能服务的表注册到global locator service上,之后client会用这类信息来选择query server。
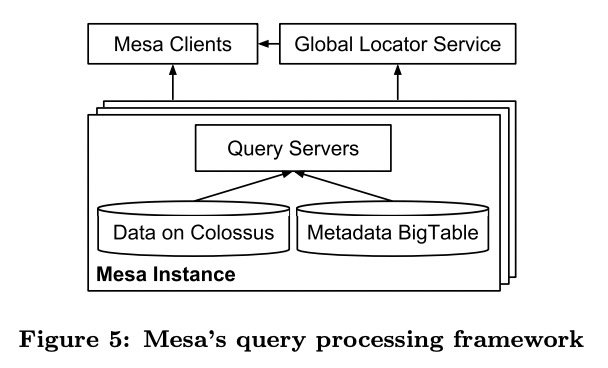
多datacenter部署
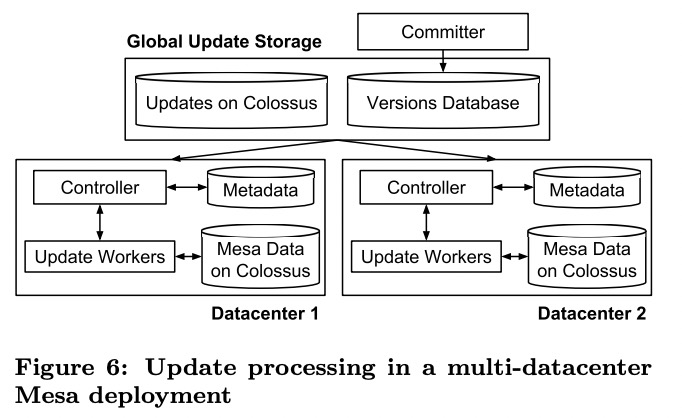
Mesa有全局的committer和version DB,前者是部署在多个datacenter的无状态的server,后者是基于Paxos的跨datacenter的datastore。
上游服务会定期将数据批量导入Colossus,再通知committer。committer为数据赋上version,再将这次更新相关的元数据写入version DB。
各个datacenter的controller会订阅version DB的修改,发现这次更新后会创建任务交给worker执行,执行完毕后将结果(success)写回version DB。
committer会周期性检查每次更新的执行完整性,等到所有controller都执行成功后,再修改version DB中的committed version,这次修改才可见。
这种异步提升version的方式不需要任何锁的参与,能保证跨表和view的修改在所有datacenter同步可见,但代价是数据可见性的延时较大。
新datacenter加入的时候类似于分布式系统中的新节点加入,先p2p加载已有数据,再应用过去一段时间的新修改。在追上之前,新datacenter不会影响committer提升committed version。
Enhancements
Query Server Performance Optimizations
query server会根据查询的key range来过滤完全不相关的delta,比如基于时间的过滤效果会非常好。
在寻找匹配的row时,Mesa会在第一列超出P的范围后seek到下一个值,从而避免scan(Tablestore也做了类似的优化,难点在于如何评估当前key的数据量,需要统计信息辅助)。
为了避免大query超时,Mesa可能会返回部分结果,并带有resume key。
Parallelizing Worker Operation
Mesa的worker可能会做涉及到超大数据量的任务(如compaction等),此时Mesa会使用MapReduce来调度worker。为了更均匀地切分数据,Mesa在写数据时会抽样row key,与数据一起写进文件。后面读的时候就可以先将所有抽样信息读上来,分片好之后再交给各个worker执行。
(具体计算分裂点的算法略,看起来与Tablestore的类似)
Schema Changes in Mesa
Mesa运用两种技术实现了在线schema变更:一种适用于所有情况的、简单但开销高的方法,一种覆盖多种重要且通用的场景的优化方法。
简单方法:
- 钉住某个version,使用新schema存一份表数据。
- 在新数据上应用这个version后面的修改。
- 原子更新query使用的schema(基于BigTable的原子更新)。
复杂方法是记录下新schema和对应的version,但不变更持久化的数据,而是在query路径上转换。新数据直接采用新schema,老数据等到下一轮base compaction时变更。
Mitigating Data Corruption Problems
在Mesa这个量级下,只在文件里记录checksum已经不足以保证数据安全了。Mesa使用了在线和离线两种方式检查数据。
各个实例在修改和查询时都会做在线检查。修改的时候会检查行序、key range、聚合值是否正确。
每隔一段时间Mesa还会做全局的离线检查,在所有实例间比较checksum。另外Mesa还会做另一种轻量的全局检查,只检查最近的committed version对应的数据的聚合值是否一致。这项检查只需要读元数据,因此开销比前面的全局离线检查要低很多。
Mesa还定期备份,即使所有实例都坏了,还可以恢复备份数据。
Experiences & Lesson Learned
只记录两点:
- 激进地预读Colossus上的数据以缓解将数据从本地磁盘迁到Colossus带来的性能降级。
- 基于像Colossus和BigTable这样的现成的系统开发,帮助作者专注于Mesa自身的架构。