TL;DR
这篇文章讲的是如何实现自己的“云原生”数据库,以及探索S3是否适合作为DB的共享存储。
S3的优点是安全、无需运维、按使用付费,缺点是访问延时高、使用廉价硬件可能会牺牲一致性(这里作者引用了Dynamo,不太确定Dynamo和S3的关系)、更新不保证顺序。
本文的贡献:
- 演示了如何在S3上实现需要被并发修改的小对象。
- 演示了S3上如何实现B树。
- 提出了可以演示如何用S3实现不同一致性级别的协议。
- 使用TPC-W基准测试了不同一致性级别下使用S3的成本。
本文的目的是在保证可用性和资源利用率的前提下,探索如何将DB的性质尽可能多地搬到云上。
结论:显然只是一次实验,验证了使用S3作为共享存储的可行性,但实用性不高。如果换成EBS的话可能更好一些。它的PU queue有点像Bw-tree。
依赖的AWS服务
EC2和S3忽略。
Simple Queueing System(SQS)是一种不保证顺序的队列服务,每个client在调用receive获取若干条消息后,SQS会锁住这些消息,等待client后续调用delete,或超时解锁。
架构
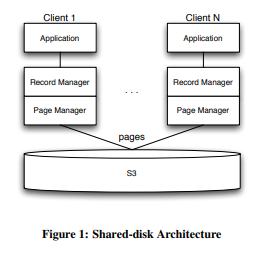
这套架构假设client的数量可能达到百万这个量级。为了保证任何client挂掉都不会阻塞其它client,client不会去拿阻塞的锁,且都是无状态的。
为了保证可用性,这套架构采用最终一致性,client可以缓存数据,也不支持完整的事务。
与S3有关的有两层,RecordManager和PageManager。client只与前者以Record为单位交互,S3只与后者以Page为单位交互。除此之外,PU queue(Pending Update queue)负责序列化log record、Lock queue负责确保同时只有一个client能应用log record、Atomic Queue负责保证client不会只写入一个commit的不完整内容。
这些模块可以组合出不同的一致性级别。
RecordManager与PageManager
RecordManager向client暴露基于record的API,但内部会将这些record组成page,由PageManager管理。
每个collection对应S3的一个bucket,每个page对应一个S3的一个object。
PageManager会在本地有一个buffer pool(内存或本地存储),其中每个page可以有状态和TTL,过期的page被访问时会通过S3的get-if-modified请求来更新。client的修改开始时只应用到本地的page上,在commit时会将所有更新写进S3或PU queue,并将所有状态为modified的page置为unmodified。abort时会清除这些modified page。
Logging和B-tree
S3上的数据组织为B树,每个节点对应一个object,实现上采用了B-link tree,即每个节点会包含指向同级兄弟节点的指针(这里是URI)(具体原理不清楚)。
B树的root的URI会在创建collection时生成,之后保持不变。
log record分为insert、delete、update三种,都要保证是幂等的:
(insert, key, payload)(delete, key),如果要实现undo log,这里还需要记录beforeimage。(update, key, afterimage),update必须要与具体的page关联。如果要实现undo log,这里还需要记录beforeimage。
Security
为了安全性考虑,数据可以加密后存进S3,且不同page可以用不同的key(记录到page header中),这样可以允许不同client只能访问不同的page。
commit协议
为了保证不同的一致性级别,这篇文章提出了三种commit协议:basic、monotomic、atomic。
三种协议都可以分为两个阶段:
- client将log record写入SQS。
- 应用log record到S3(称为checkpointing)。
其中第一步成功就被视为commit成功,只是数据还不可见。client可以继续干别的去了,等待数据异步可见。
Basic协议
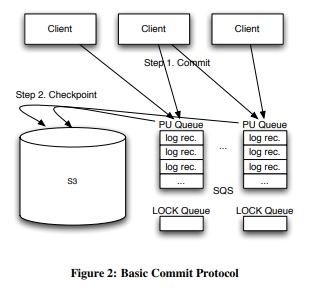
在Basic协议中,B树的每个叶子节点对应一个PU queue,里面是对这个page的所有update,另外B树本身还有一个PU queue,里面是所有insert和delete。
每个PU queue对应一个Lock queue,里面有一个元素。负责checkpointing的client会尝试去获取这个元素,如果获取成功,表明此刻只有它自己在操作这个PU queue,它就会开始应用log record到本地,之后如果没有timeout,再将新page更新到S3上并删除PU queue中应用过的log record。如果已经timeout了,则放弃更改。
如果在更新到S3之后和删除PU queue中的record之间client挂了,这些record可能被应用两次,可能导致同一个key的值不一致(因为SQS不严格保序?),此时需要使用monotonic协议。
checkpointing的触发间隔会影响数据的可见延时,但越小的checkpointing,整体的开销越大。
默认是写时定期checkpoint,但为了避免有只写一次的page永远不更新,可以允许reader也能checkpoint。
Atomic协议
如果一个client在commit一半时挂了,可能只写了部分内容到S3。为了解决这个问题,保证所有更新要么都成功,要么都失败,我们可以增加一个Atomic Queue。
client每次commit时,先将所有log record写入自己的Atomic queue,最后再写一条表示所有record都写成功的commit record,里面包含commit id和record数量。之后再走正常的commit流程。
如果client failover,它会检查Atomic queue,将其中不完整的事务对应的record都删掉,再重新commit完整的事务。
注意,这里只保证了提交的all or none,不保证atomic的可见性。
一致性级别
以下讨论几种一致性级别该如何实现:
- Monotonic reads:一旦读到x,后续只会读到x或比x更新的值。client可以在本地记录每个page id上次读到的version,这样如果这个page读到了更旧的version,client可以重新从S3中读取。
- Monotonic writes:每个client的update record中可以记录一个client维度的counter,这样在checkpointing时可以按
(client, counter)排序,将乱序的record留在PU queue中等待下一轮处理。 - Read your writes:client更新过x后,后续只会读到x或比x更新的值。默认满足。
- Write follows read:同一个client先读到x,后更新,只会取代x或比x更新的值。