TL;DR
本文探讨如何基于 AWS 的多种存储介质(本地 SSD、EBS 与 S3)实现一个 cloud native 版的 kv engine(比如 TiKV [狗头]),以及其中为什么要引入文件系统这一层抽象。
目前的 Cloud TiKV
长话短说。TiKV 的架构如下:
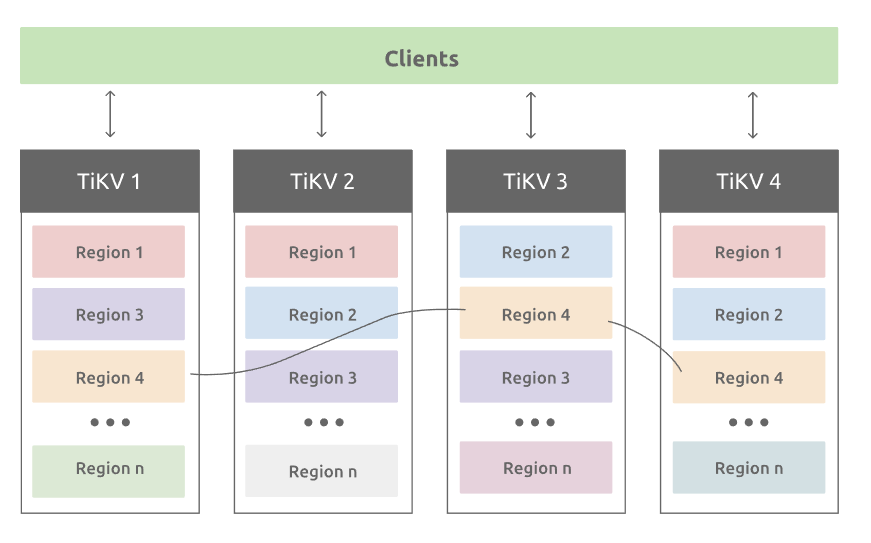
每个节点都维护一个本地的 kv store,节点间通过 raft 协议保证多副本的一致性。如果将 TiKV 直接搬上 AWS,每个 TiKV node 底下需要挂载一块盘当作本地存储。截止到 TiDB 6.0,Cloud TiKV 仍然挂载的是 EBS。
这带来几个问题:
- 成本。EBS 相比 S3 很贵,而相比本地 SSD 又 IOPS 受限。
- 弹性。EBS 不支持被多个 instance 挂载(EFS 又贵又不好用),因此只能被当作本地磁盘使用。这导致了 TiKV 在扩缩容的时候真的在搬数据。集群扩容规模大一点动辄需要几个小时。
- 资源浪费。TiKV 的每个副本会独立进行 compaction。我们知道 lsmt engine 中 compaction 通常是非常消耗计算资源的。当使用可靠存储介质时,我们完成可以只让写节点(比如 leader)compaction 一次,而让生成的文件被多个读节点(比如 follower)反复使用。
TiKV 的存储实际可以分为 WAL 与 Data 两部分,两者对存储介质的需求差别较大,且通常前者成本远低于后者。本文主要探讨 Data 的管理,可以假设 WAL 仍然以多副本的形式保存在 EBS 上。
免责声明:本文只是以 TiKV 为例,以下内容不保证符合 TiKV 实现。
为什么不直接用本地 SSD
相比 EBS,本地 SSD 有以下问题:
- 可靠性较差,带来额外的容错负担。
- 容量有限,如 r5d.2xlarge(8C 64GB)只能挂载 300GB 的 NVME SSD。
为什么不直接用 S3
S3 可以解决前面说的几个问题:
- 成本。S3 的存储成本远低于 EBS。
- 弹性。S3 提供了一种 global namespace,这样扩缩容期间数据不需要真正被移动,新节点直接 load S3 上的数据就可以了。
- 资源浪费。基于 S3 的高可靠性与 global namespace,只需要写节点写一份数据,其它读节点就可以直接 load 使用。
但对于 OLTP 应用来说,S3 会带来几个新问题:
- 读延时太高,且不稳定。
- IOPS 受限。
- 频繁的 PUT/GET 成本并不低。
对于 WAL,S3 的另一个问题是不支持 append。这也是本文假设 WAL 仍然保存在 EBS 上的原因之一。
结合 S3 与本地 SSD
S3 的种种不足,提示着我们,它需要一层 cache。翻出经典的 Computer Memory Hierarchy:
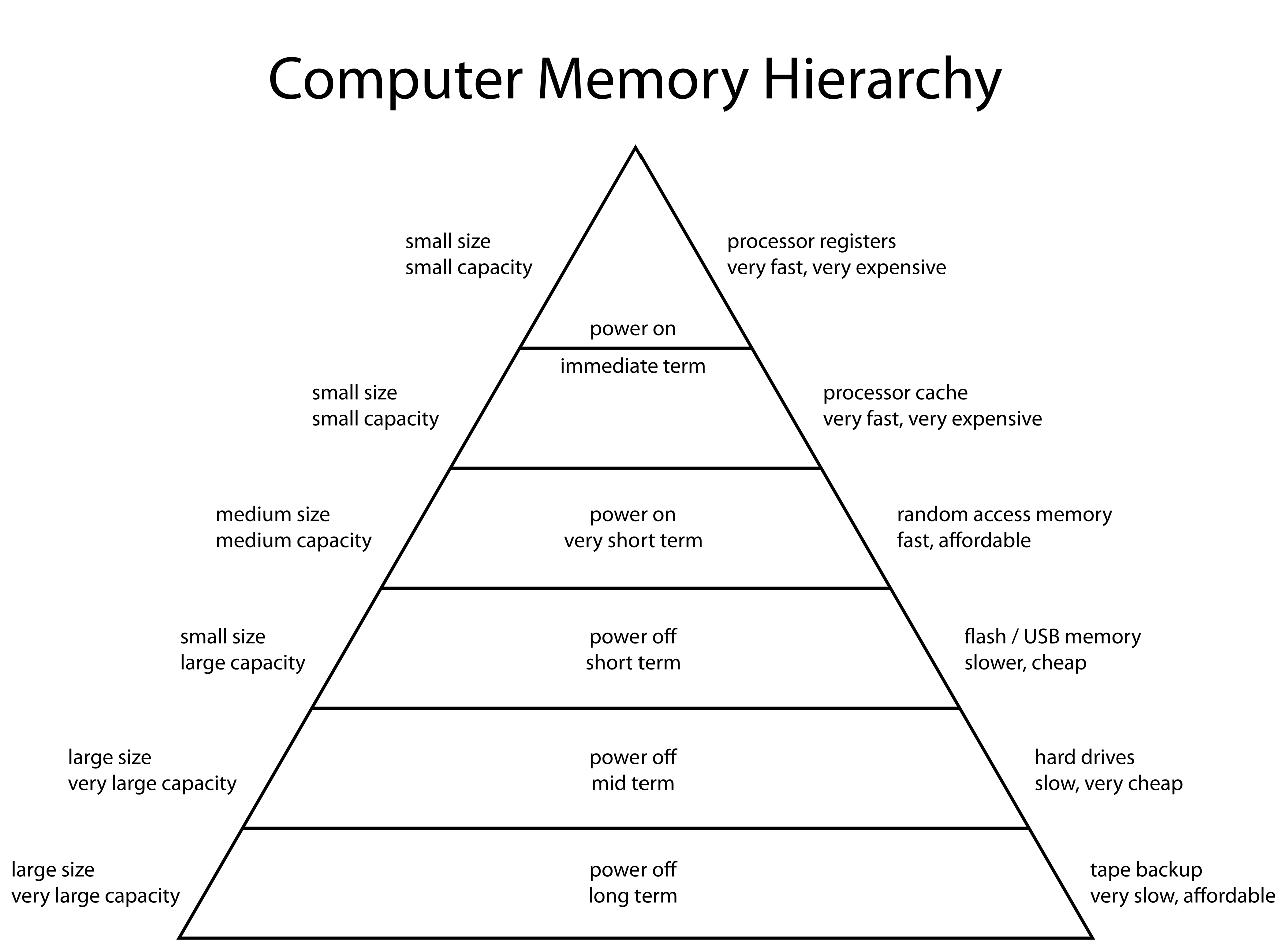
对于 S3 这种 remote storage,最适合的 cache 就是 local storage。恰好这种定位能够解决本地 SSD 容量有限的问题(cache 不需要保存全量数据)。
我们的新设计中,WAL 仍然会写三份 EBS,但只有 leader 会做 flush 与 compaction 这样的写操作。数据直到存放到 S3 上才算持久化完成。之后 follower 异步将需要的数据缓存到自己的本地 SSD 上。
这样:
- 存储主要在 S3 上,且只存一份。
- 扩缩容不再需要大量移动数据。
- 命中本地 SSD 的请求不再需要访问 S3,降低了请求成本,也降低了延时。
整套架构与 解耦NoSQL系统的写、读、Compaction 差不多。
leader 会向 follower 发送两类数据:
- data。
- manifest change。
当收到 data 之后,follower 仍然会将其写入 Memory,但不持久化。这样基于一个 manifest 的 snapshot 与足够新的 memory data,follower 仍然可以正确服务读请求(假设我们需要 follower read)。此时本地 SSD 上的数据可能部分与 memory data 重复,但不影响结果正确性,后续也可以异步清理。
抽象为分布式文件系统
前面的设计中,隐含的假设是本地 SSD cache 的单位是 S3 object,也就是单个文件。但我们知道文件是可以很大的,比如达到几十上百 GB 都是可能的,这个粒度显然太粗了。Block 这个粒度又可能太细了。我们需要有办法将文件分成较小的块(如 4-64 MB)。
另一方面,为了能快速过滤数据,文件中的 meta 与 data 也需要不同的管理策略,如 meta 要尽可能保持在 cache 中(无论是本地 SSD 还是 memory)。
这些都要求我们细粒度管理文件中的不同块。
在实际动手之前,请先停一下。我们回看整个设计在做什么:
- global namespace,每个 client(即 TiKV 节点)可以访问任意文件。
- 一写多读,且文件写完之后不再更新。
- 文件需要被切割成较小的块。
有没有分布式文件系统的意思?
我们可以将前面的设计抽象为一个基于 AWS 的分布式文件系统:
- 需要额外的 metadata service 管理 chunk objects。
- 不需要单独的 chunk server,直接将 chunk 保存为 S3 object。每个 chunk 大小在 4-64 MB 之间。
- 托管本地 SSD 与 S3 之间的换入换出和写回(针对 leader)。
这样,我们可以将文件分成几类:
- manifest,维护文件列表。
- meta file,包含各种 index 与 filter。
- data file,包含实际数据。
上层 kv store 在访问时仍然基于 <filename, offset>,底下 fs 负责将其翻译为 <chunk_object, offset>。如果这个 chunk 命中本地 SSD cache,就直接返回;如果没命中,再访问 S3 加载对应的 chunk。
这样上层应用不再需要关心底层的存储介质,同时仍然可以在成本与性能之间达到一个平衡。
难道 TiFlash 就不需要这样的一个文件系统吗?