原文:Windows Azure Storage: A Highly Available Cloud Storage Service With Strong Consistency
年代:2011
Windows Azure Storage(WAS)是Azure的存储层,它的特色在于基于同一套架构提供了对象存储(Blob)、结构化存储(Table)和队列服务(Queue)。
这三种服务共享了一个提供了强一致、global namespace、多地容灾、支持多租户的存储层。
个人猜测这种设计(同时推出三种服务)更多出于组织架构的考虑,而不是技术层面上有非这么做的理由。
以及这篇文章作者中有多名后来加入阿里云存储的大佬,所以可以从这里面看到一些后来阿里云存储产品发展的影子。
三种服务都使用了同一套global namespace,格式为:
1 | http(s)://AccountName.<service>.core.windows.net/PartitionName/ObjectName |
其中:
- AccountName会作为DNS解析的一部分,来确定这个account对应的primary data center(如果需要跨地域就需要使用多个account)。
- PartitionName是跨对象事务的边界。
- ObjectName是可选的,Blob就没有。
Table的每行的primary key由PartitionName和ObjectName组成。Queue的PartitionName用来标识队列,而ObjectName则用来标识消息。
WAS的底座是Windows Azure Fabric Controller,负责分配和管理资源,WAS会从它那里获取网络拓扑、集群物理布局、存储节点的硬件信息等。
一套WAS环境由若干套storage stamp和一套location service组成:
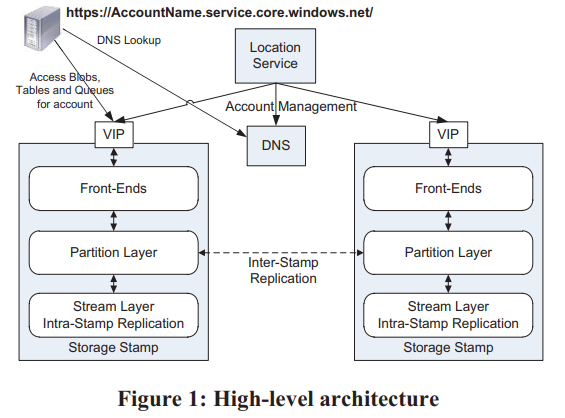
每套storage stamp是一个小集群,典型的大小是10-20个rack,每个rack有18个节点。第一代storage stamp容量是2PB,下一代会提升到30PB。storage stamp的目标是达到70%的使用率,包括了容量、计算、带宽。
location service负责管理account到storage stamp的映射与迁移(一个account只能有一个primary storage stamp)。
storage stamp内部分为三层:
- stream层提供类似于GFS的能力。数据组织为extent(类比chunk),extent再组织为stream(类比file)。这一层是三种服务共享的。
- partition层提供三种服务特有的能力。它负责提供应用层抽象、namespace、事务与强一致的能力、数据的组织、cache。partition和stream的server是部署在一起的,这样最小化通信成本。
- front-end(FE)负责处理请求。它会缓存partition map从而快速转发请求。另外它还可以直接访问和缓存stream层的数据。
storage stamp提供了两种replication:
- stamp内部,在stream层提供同步的replication,提供数据的强一致性。
- stamp之间,在partition层提供异步的replication,提供数据的多地容灾能力。
区分两种replication还有一个好处是stream层不需要感知global namespace,只需要维护stamp内的meta,这样metadata就不会那么多,更容易全部缓存到内存中。
在stream层数据组织为三层:
- block是读写的最小单元,但不同block可以有不同大小。每个block有自己的checksum,每次读都会校验。另外所有block定期还会被后台校验checksum。
- extent是stream层replication的单元,它由一系列block组成。每个extent最终会长到1GB大小,partition层可以控制将大量小对象存储到一个extent,甚至一个block中。
- stream类似于一个大文件,但它不拥有extent,只是保存了若干个有序的extent引用。将已有的extent组织起来就可以得到新的stream。
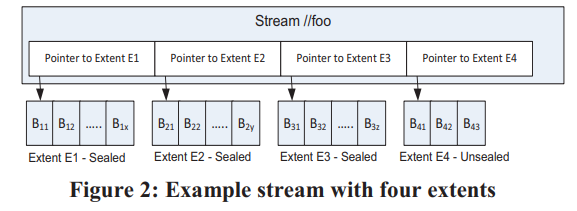
注意stream层是append-only的,每个stream只有最后一个extent可以被写入,其它extent都是不可变的(immutable,被seal了)。(猜测未seal的extent不可被多个stream共享)
stamp内部有两类组件:stream manager(SM)和extent node(EN),前者是master,后者是data node。
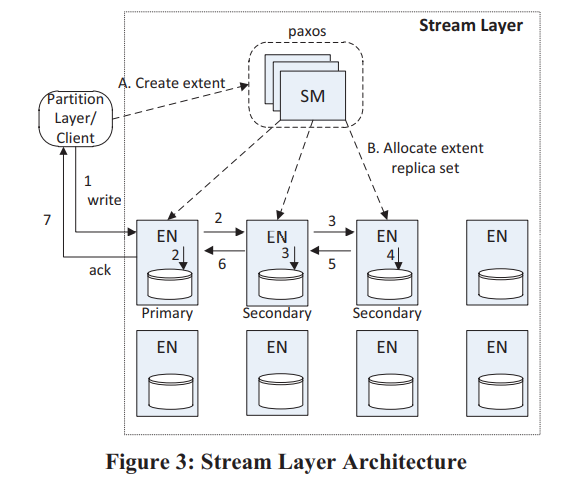
(大概讲SM怎么与EN通信来管理extent,类似于GFS,略过)
extent支持原子append多个block,但因为重试原因可能数据会被写入多次,client要有能力处理这种情况。
client会控制extent的大小,如果超过阈值则发送seal指令。被seal的extent不可再被写入,stream层会对sealed extent做一些优化,如使用erasure coding等。
stream层提供的强一致保证:
- 一旦写入成功的消息告知了client,后续所有replica上这次写入的数据都可见(read committed)。
- 一旦extent被seal了,后续所有已经seal的replica的读保证看到相同内容(immutable)。
每个extent有一个primary EN和若干个secondary EN,未被seal的extent的EN是不会变的,因此它们之间不需要有lease等同步协议。extent的写入只能由primary EN处理,但可以读取任意secondary EN(即使未seal)。primary会将所有写入排好序,确定每笔写入的offset,再发给所有secondary EN。所有replica都写成功了之后primary才会告知client。
client在写入过程中会本地缓存extent的meta,不需要与SM通信(直到需要分配新extent)。如果某次写入失败了,client可以要求SM来seal这个extent,然后立即开始写新extent,而不需要关心旧extent末尾是否有数据不一致。
seal过程中SM会与每个replica EN通信,并使用可用的EN中最小的commit length。这样能保证所有告知过client的数据都不会丢,但有可能会有数据还没来得及告知client。这是client需要自己处理的一种情况。(是不是可以让client缓存一个commit length,seal时告知SM)
client在读多副本的extent时可以设置一个deadline,这样一旦当前EN无法在deadline之前读到数据,client还有机会读另一个EN。而在读erasure coded数据时,client也可以设置deadline,超过deadline后向所有fragment发送读请求,并使用最先返回的N个fragment重新计算缺少的数据。
WAS还实现了自己的I/O调度器,如果某个spindle(这个怎么翻译?)已经调度的I/O请求预计超过100ms,或有单个I/O已经排队超过200ms,调度器就不再向这个spindle发送新的I/O请求。这样牺牲了一些延时,但达到了更好的公平性。
为了进一步加速I/O,EN会使用单独的一块盘(HDD或SSD)作为journal drive,写入这台EN的数据会同时append到journal drive上,以及正常写extent,哪笔写先完成都可以返回。写入journal drive的数据还会缓存在内存中,直到数据写extent成功(阿里云的pangu使用了类似的方案)。journal drive方案的优点:
- 将大量随机写转换为了顺序写。除了写journal drive天然是顺序的,这种设计还使得写extent时可以使用更倾向batch的I/O调度策略,进一步提高了磁盘带宽的利用率。
- 关键路径上读写请求分离,前者读数据盘(或cache),后者写journal drive。
使用了journal drive可以极大降低I/O的延时波动率(对在线业务意义重大)。
(Partition层的设计类似于BigTable,略过部分信息)
Partition层数据保存在了不同的Object Table(OT)中,每个OT分为若干个RangePartition。OT包括:
- Account Table
- Blob Table
- Entity Table
- Message Table
- Schema Table
- Partition Map Table
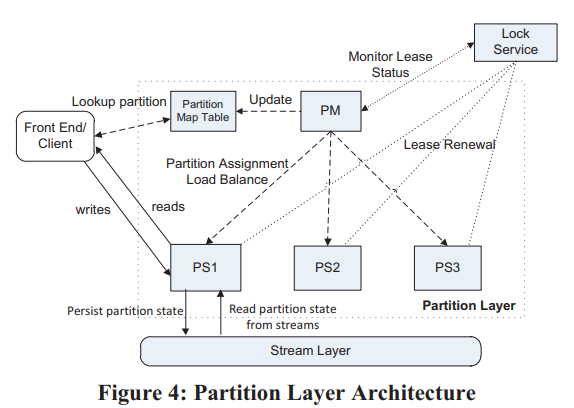
Partition层的架构:
- Partition Manager(PM):类似于BigTable的Master,管理所有RangePartition。
- Partition Server(PS):类似于BigTable的Tablet Server,加载RangePartition,处理请求。
- Lock Service:类似于Chubby。
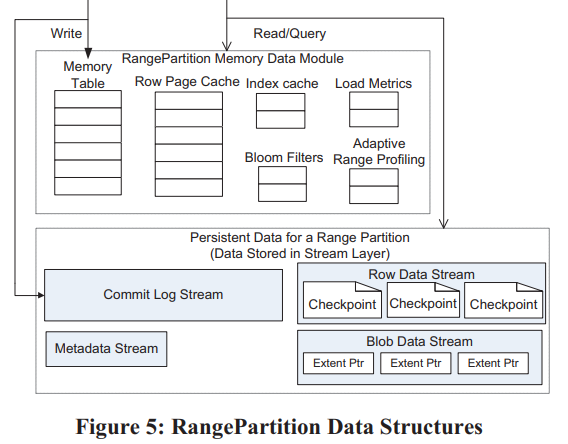
Blob Table有个类似于后面Wisckey[1]的优化,就是大块数据进commit log,但不进入row data(不进cache、不参与常规compaction等),相反row data中只记录数据的位置(extent+offset),并且在checkpoint的时候直接用commit log的extent拼装成data stream。
RangePartition的分裂(Split)过程:
- PM向PS发请求,要求将B分裂为C和D。
- PS生成B的checkpoint,然后B停止服务(此时是不是可以不停读)。
- PS使用B的所有stream的extent组装成C和D的stream。
- C和D开始服务(client还不知道C和D,此时应该不会有请求发过来)。
- PS告知PM分裂结果,PM更新Partition Map Table,之后将其中一个新Partition移到另一台PS上(分散压力)。
合并(Merge)过程类似:
- PM将C和D移动到相同PS上,之后告知PS将C和D合并为E。
- PS生成C和D的checkpoint,之后C和D停止服务。
- PS使用C和D的stream的extent组装为E的stream,每个stream中C的extent在D之前。
- PS生成E的metadata stream,其中包括了新的stream的名字、key range、C和D的commit log的start和end位置、新的data stream的root index。(这里commit log的meta管理有点复杂,如果连续分裂怎么办?Tablestore是先停止服务再生成checkpoint,就不需要分别记录C和D的log meta,但停止服务时间会比较长;WAS这种方案停止服务时间短,但meta管理复杂)
- E开始服务。
- PS告知PM合并结果。
最后是一些经验教训的总结:
- 计算存储分离。好处是弹性、隔离性,但对网络架构有要求,需要网络拓扑更平坦、点对点的双向带宽更高等。
- Range vs Hash。WAS使用Range的一个原因是它更容易实现性能上的隔离(天然具有局部性),另外客户如果需要hash,总是可以基于Range自己实现,而反过来则不然。
- 流控(Throttling)与隔离(Isolation)。WAS使用了SimpleHold算法[2]来记录请求最多的N个AccountName和PartitionName。当需要流控时,PS会使用这个信息来选择性拒绝请求,大概原则是请求越多,被拒绝概率越大(保护小用户)。而WAS会汇总整个系统的信息来判断哪些account有问题(异常访问),如果LoadBalance解决不了就更高层面上控制这种用户的流量。
- 自动负载均衡(LoadBalancing):WAS一开始使用单维度“load”(延时*请求速率)来均衡,但无法应对复杂场景。现在的均衡算法是每N秒收集所有Partition的信息,然后基于每个维度排序,找出需要分裂的Partition。之后PM再将PS按各维度排序,找出负载过重的PS,将其中一部分Partition移到相对空闲的PS上(整体思路与Tablestore的LoadBalance差不多,更系统化一些,但Tablestore的LoadBalance策略更多,更灵活)。
- 每个Partition使用自己的log file。这点与BigTable的整个Tablet Server共享log file区别比较大。单独log file在load/unload上更快,且隔离性更好,而共享log file更节省I/O(综合来看单独log file更好一些,尤其是随着存储性能的提升、计算存储分离架构的流行,共享log file的优势越来越小,劣势越来越大了)。
- Journal drive。它的意义是降低I/O波动。BigTable使用了另一种方案,用2个log来规避长I/O,但导致了更多的网络流量与更高的管理成本。
- Append-only。(与log as database理念差不多)
- End-to-end checksum。
- Upgrade。重点是在每一层将节点分为若干个upgrade domain,再使用rolling upgrade来控制upgrade的影响。
- 基于相同Stack的多种数据抽象。就是指Blob、Table、Queue(其实还应该有Block)。
- 使用预定义的Object Table,而不允许应用定义自己的Table。意义在于更容易维护(真的有意义吗)。
- 限制每个Bucket大小为100TB。这个是教训,WAS计划增大单个storage stamp。
- CAP。WAS认为自己在实践层面上同时实现了C和A(高可用、强一致),具体策略上是通过切换新extent来规避掉不可访问的节点(实践上有意义,但也不能说是同时实现了C和A)。另外[3]表示使用chain replication就可以同时实现高可用和强一致。
- 高性能的debug log。这点很重要。
- 压力点测试。WAS可以单独测试多个预定义的压力点(如checkpoint、split、merge、gc等)。(除此之外现在还需要考虑chaos test)。