原文:Hekaton: SQL Server’s Memory-Optimized OLTP Engine
年代:2013
Hekaton是SQL Server的一个内存数据库子系统,它有以下特点:
- 数据全在内存中,但具备持久化存储能力(不会丢数据)。
- 使用无锁结构(latch-free/lock-free)。
- MVCC结合乐观并发控制(optimistic concurrency control)。
- 存储过程可以预编译为C代码,再进一步编译为机器指令。
Hekaton的目标是将现有的SQL Server的吞吐提升10-100倍以上,有三个方向:
- 提升scalability;
- 提升CPI;
- 减少指令数。
有分析表明前两个方向只能提供3-4倍的提升,那么就要在减少指令数方面有巨大的进步:10倍提升需要减少90%的指令;100倍提升需要减少99%的指令。这就需要重新设计存储与数据处理系统。
Hekaton的解法是无锁结构、乐观并发控制、预编译存储过程、不使用分区。最后一个比较有意思,其它很多内存数据库都将DB分为若干个partition,分别由不同的CPU核服务。但Hekaton认为这种做法对query的限制过强,一旦query跨分区性能就急剧下降,无法为各种各样的workload提供稳定的服务。
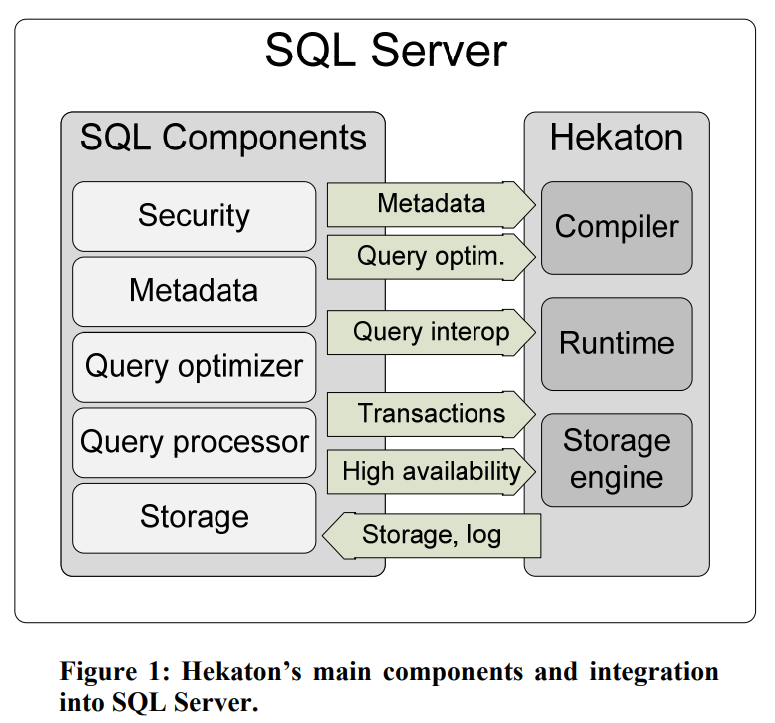
整体架构上Hekaton是基于SQL Server之上的,通过定制的Compiler、Runtime、Storage三个模块来提供内存数据的服务。
Hekaton的MVCC是通过每个record中记录begin time和end time来实现的,一行的所有版本的begin和end time连续且不重叠,对任意时间T,都只有一个版本是有效的。
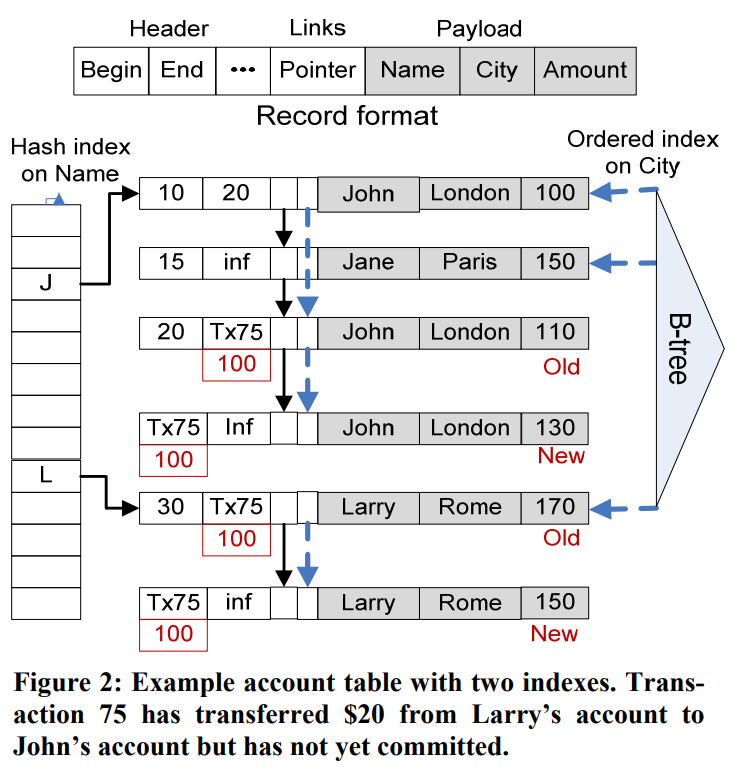
每个record中还有一些link用于构建索引。
Hekaton支持两种索引,hash index(基于lock-free的hash table)与range index(基于lock-free的Bw-tree)。hash index会使用record的第一个link,将每个桶的所有record链接起来。Bw-tree中保存的是指向record的指针,且使用第二个link将相同key的record链接起来(此时Bw-tree中指针指向链表的第一项)。
当执行读时,Hekaton会先指定read time,然后用这个时间去找那些有效(begin <= rt < end)的记录。如前所述,每行只会有一个版本出现在read set中。
当执行写时,事务提交前,Hekaton会将被删除的record的end time和插入的record的begin time改为事务ID,在提交时再修改为提交时间。
与很多其它支持MVCC的系统一样,Hekaton也支持snapshot isolation,但为了提供serializable isolation,Hekaton还增加了以下两种检查:
- 读集合不变(Read stability):在事务T提交前检查它读过的数据没有被修改过。
- 避免幻读(Phantom avoidance):在事务T提交前再次scan,确保没有新的数据出现。
更弱的isolation只需要放宽这两项检查:repeatable read只需要第一项,snapshot isolation与read committed不需要额外检查。
这两项检查都是在提交时进行,具体来说是在获得commit time后。Hekaton认为这两项检查的开销还好,不是那么恐怖,原因是检查过程中会touch的数据大概率仍然在L1/L2 cache中(存疑)。
这里Hekaton要解决的一个问题是,在乐观并发控制下,如果T1读到了T2写的数据,当T2先进入提交检查的阶段,T1就需要依赖于T2检查的结果。这就产生了一个commit dependency:T2如果abort,则T1也需要跟着abort(避免dirty read);T1如果要commit,需要等待T2的commit结束。
事务提交过程中还会记logical redo log(不需要undo),包含所有新增与删除的record,因此每个事务需要维护自己的write set直到提交。index不需要写log。
被删除或被abort的record在没有活跃事务引用之后就可以gc掉了,但前提是所有index也都不再引用这个record。
整个gc过程分为两阶段:
- 协作阶段,每个工作线程扫index过程中遇到无效的record都可以unlink掉,最后一个unlink的线程就可以回收这个record了。
- 有背景线程定期并发扫无效的record,尝试将其在所有引用的index中unlink,再回收。
最后是Hekaton的预编译。
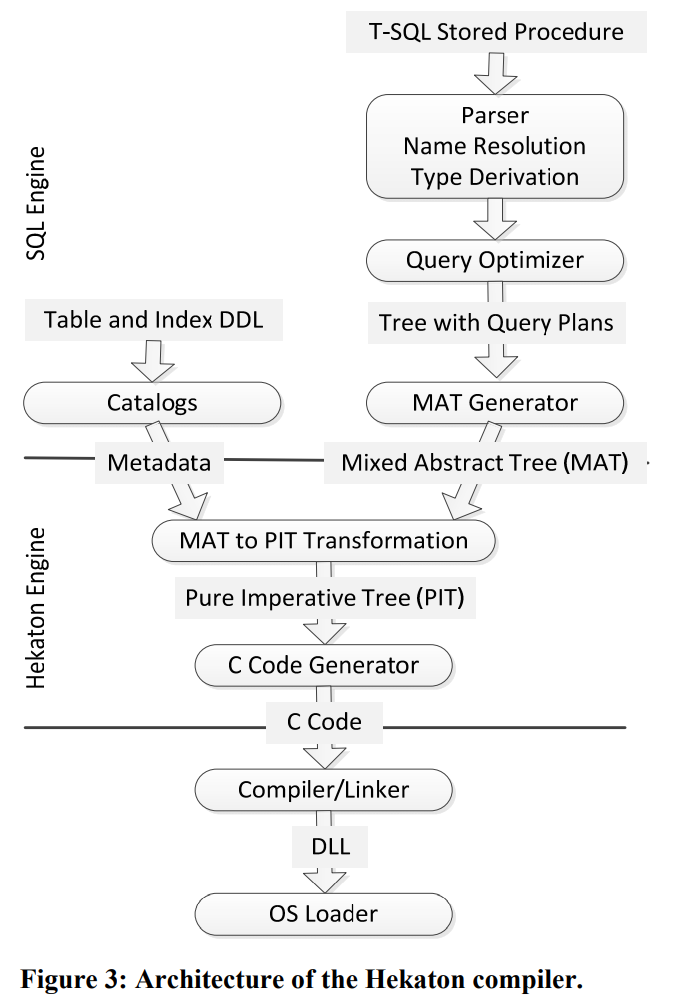
Hekaton因为是一个OLTP系统,不值得对ad-hoc query做JIT,因此它的预编译发生在两个时刻:表创建时、存储过程创建时。
Hekaton会在表创建时将每张表的schema编译为一组callback,其中包含了对record的处理,如hash、compare、serialize等,这样保证了Hekaton仍然是不需要感知表结构的。
而当创建一个存储过程时,Hekaton会先为其生成C代码,再进一步编译为机器指令。
Hekaton的代码生成有两个特点:
- 整个query生成一个函数,其中大量使用goto跳转。这样虽然降低了可读性,但生成的代码本来就不是给人读的,且这样的代码执行效率最高。
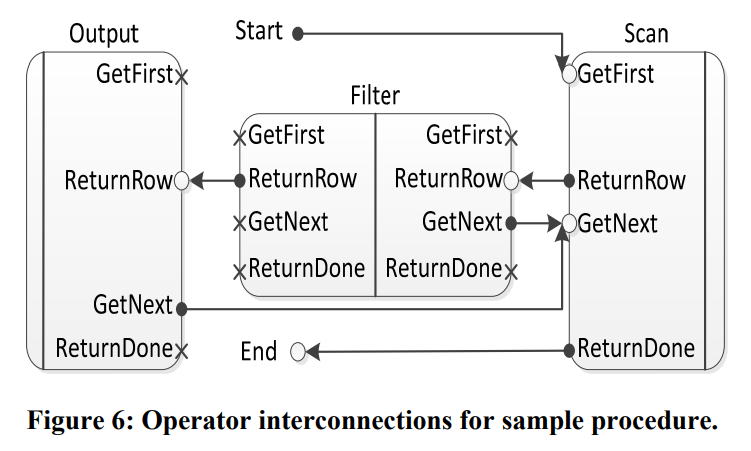
- 虽然executor是自顶向下的volcano风格,但生成的代码是自底向上的,函数入口是最底层operator。这个过程相当于将operator的pipeline转换为了全局的状态机。
如下图这个简单的query:
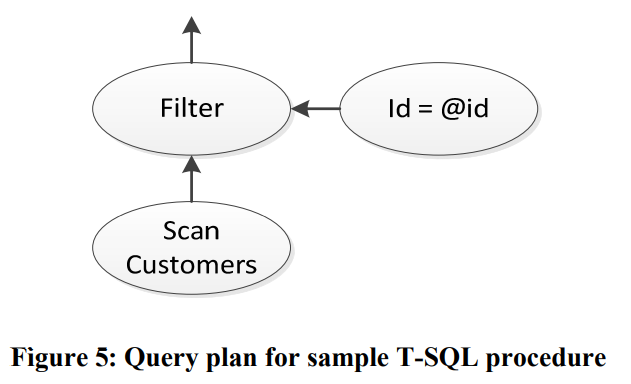
会生成下面这种执行流: