LLAMA是一种无锁的page管理系统,它包含内存cache与磁盘log structured store(LSS)两部分,并自动控制page在两者之间移动(flush、换入/换出)。
它有以下特点:
所有操作都是无锁的(latch-free),内存部分基于epoch机制回收数据。
优点:系统并行度高;epoch机制几乎是额外开销最小的回收机制,且容易实现。
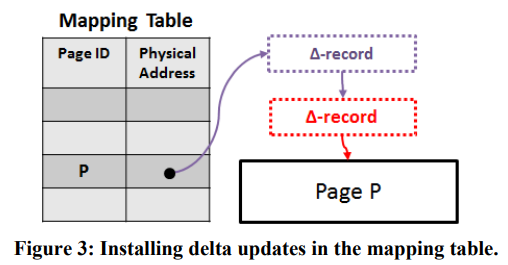
所有page都是immutable的,对page的修改要通过附加一个delta来实现,并通过对mapping table进行CAS来让新的page可见。
优点:既满足了无锁的需求,又对cache非常友好。
磁盘部分是一种log structured store,可以写入完整的page,或delta。
优点:可以只写入delta能显著降低写放大;LSS这种append-only的结构将所有随机写转化为了顺序写,性能更高,且可以省掉Flash的FTL。
LLAMA可以作为Bw-tree的底层系统。
LLAMA的核心是一个mapping table,维护每个pageID到具体的pageAddr。这里的pageAddr既可以是内存地址,又可以是LSS的地址,使用最高位来区分。
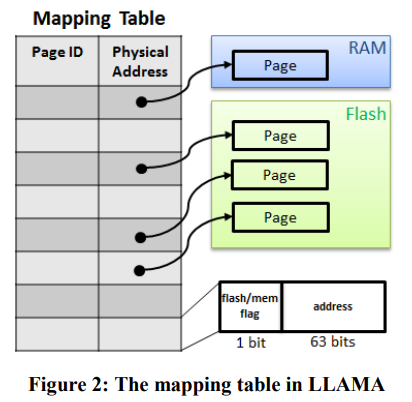
LLAMA提供两种更新page的方式:
Update-D(pid, in-ptr, out-ptr, data):增量更新,向pid对应的page上附加一个delta,会产生一个新的delta item指向旧的pageAddr。Update-R(pid, in-ptr, out-ptr, data):全量更新,将pid替换为新的page。
无论是哪种方式,最终都需要通过CAS来替换mapping table中的pageAddr。
另外LLAMA的Read(pid, out-ptr)也可能会修改mapping table:对应的page在LSS中,Read会将它载入内存,并CAS修改mapping table。
上面的操作只是在修改内存数据,另外LLAMA还提供了与LSS交互的接口:
Flush(pid, in-ptr, out-ptr, annotation):将page的状态(完整page或只是delta item)拷贝到LSS的buffer中,但不一定落盘。Mk-Stable(LSS address):保证LSS address及之前的数据都落盘。Hi-Stable(out-addr):返回最高的已经stable的LSS addr。Allocate(out-pid):分配一个新的pid,需要使用系统事务来完成操作。Free(pid):释放一个pid,每个epoch被释放的pid会组成一个free-list。同样,Free也需要使用系统事务来完成操作。
系统事务可以理解为原子的修改+Flush,Bw-tree会用它来实现树结构的修改(SMO)。每个活跃的系统事务在LLAMA的active transaction table(ATT)中对应一个entry list,其中保存着这个事务所有的修改。如果事务最终commit成功,这些修改会拷贝到LSS buffer中并flush,否则所有修改会逆序rollback掉(包括Allocate和Free)。
注意:Update-R因为不方便rollback,不能用于事务中。
支持事务的操作(如Update-D)可以传入tid和annotation,它们会被放到delta item中,其中annotation是给应用自己用的。
注意系统事务只是保证了多个操作的原子性,并不保证它们与其它操作相互隔离,用户需要理解这种受限事务的语义,并小心避免预期之外的结果。
Bw-tree的SMO被设计为不依赖事务的隔离性:
- 在mapping table中分配page。
- 写page(此时page对其它线程不可见)。
- 更新已有的page,将新page连接上去,或移除已有的page。
即用户需要自己注意操作的顺序,人为保证隔离。
但上面的第3步既要更新mapping table,让修改可见,又要保证接下来commit(flush)成功。因此LLAMA提供了一种事务性的Update-D,即修改后直接flush。
整个系统事务只在内存层面可见,即abort的事务不会进入磁盘存储,因此recovery不需要感知事务。
LLAMA中flush是非常重要的操作,被flush过的page就可以被换出内存了。但因为LLAMA的无锁机制,flush就有点麻烦。
flush需要解决的问题:
- flush过程中page可能被修改,需要保证如果page被修改过,则flush失败。
- 一个page被多次flush的话,需要保证它们进入LSS的顺序与flush顺序相同。
- 因为flush也是一次CAS,需要有办法区分LSS中哪些entry是flush失败的(否则recovery不好实现)。
flush过程:
- 获得当前page状态。
- 从LSS buffer中预分配足够的空间。
- 生成flush delta(其中包括刚刚分配的LSS addr),并执行CAS。
- 如果CAS成功,开始向LSS buffer拷贝数据,LLAMA保证这期间不会有磁盘I/O(避免数据不完整)。
- 如果CAS失败,向LSS buffer中写入“Failed Flush”,这样recovery期间可以跳过这样的entry。
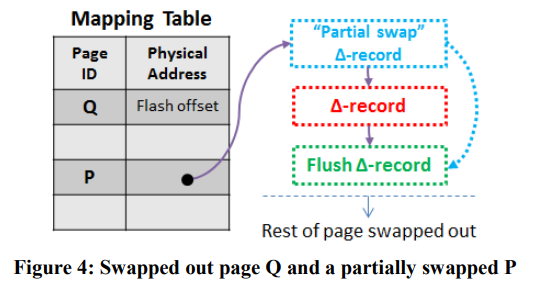
flush过的page就可以换出内存了。如果被换出的page被完整flush了,则mapping table中它的地址会被换成对应的LSS addr。LLAMA还支持只换出page的一部分(可能还有部分delta在内存中),此时LLAMA会生成一个partial swap delta,其中指向page原来的地址,以及最高的被换出的LSS addr,再CAS替换mapping table。
接下来是LLAMA中LSS的管理。LSS分为两部分,一部分是内存中的buffer,一部分是磁盘存储。
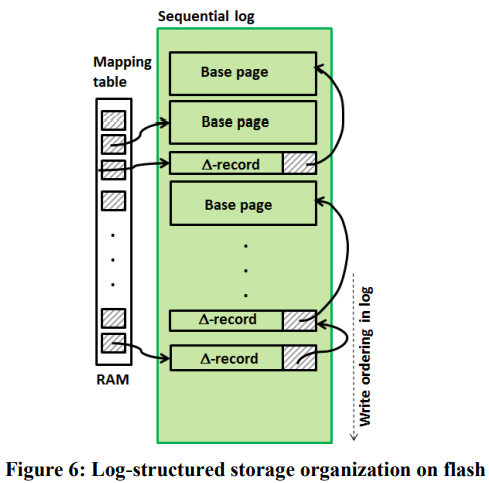
每个写线程都可以执行Flush,将数据拷贝进LSS的buffer,步骤是先预分配空间,再拷贝。如果分配空间时超出了LSS buffer的容量,就会进入seal buffer的流程。
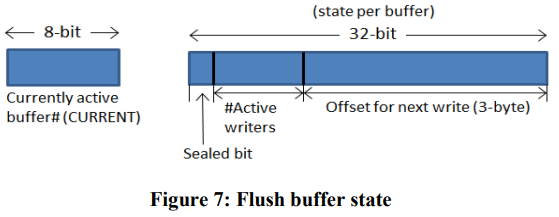
seal buffer的线程先通过CAS将buffer的seal位设置为1,然后等待所有现存的writer都结束(active writers降为0),最后触发一次异步I/O。这次I/O结束后buffer会被重置,继续使用。
LSS可以同时有多个buffer,但只有一个是CURRENT。seal buffer的线程也负责更新CURRENT。
LSS的磁盘存储可以认为是一个环形buffer,定期的cleaning就是从头部(最老的)将仍然在使用的page重新写到尾部。cleaning既可以释放空间,还可以将page不连续的各部分合并起来,I/O更高效。
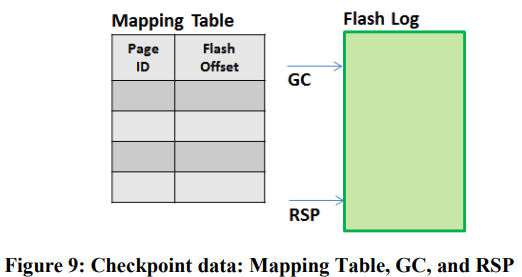
LSS的recovery关键是要定期生成mapping table的checkpoint,过程为:
- 记录当前LSS buffer的addr,称为recovery start position(RSP);当前GC的位置。
- 遍历mapping table,记录每个非空的page对应的不高于RSP的最新addr(只需要记录已经在LSS中的page状态)。