原文:Hyper: A Hybrid OLTP&OLAP Main Memory Database System Based on Virtual Memory Snapshots
年代:2011
TL;DR
HyPer是一种内存数据库,它有以下特点:
- 基于H-Store的设计,串行(因而无锁)执行事务(存储过程)。
- 通过fork子进程方式服务OLAP请求。
通过fork来隔离OLTP与OLAP还挺有创意的,OS的实现显然比自己控制请求间的数据隔离更高效。
目测这仍然是研究大于实用的项目(至少在文章发表时)。
首先HTAP的重要性就不用说了。
HyPer接下来开始认证内存数据库的可行性:
有研究表明关键业务的TP数据量并不大,可以放得进单机内存中。比如Amazon每年营收150B$,假设每笔订单金额是15$,需要54Byte存储(TPC-C就是这样的)则每年的订单数据量只有54GB(还能这么算)。作者认为可以放心预言内存容量的增长速度要超过大客户的业务需求(的增长速度)。
还是上面的例子,Amazon每年1B个订单,则平均每秒32个,峰值也顶多在每秒几千这个量级。
HyPer选择了基于H-Store[1]的无锁架构,即单线程串行处理事务,这样所有数据结构都不需要有锁(锁对传统RDBMS性能的影响见[2])。但H-Store这种架构无法处理交互式事务,因此需要所有事务都写成存储过程预先加载到系统中,业务调用时只能指定存储过程的名字和参数。
为了隔离OLTP与OLAP请求(主要是不想让OLAP请求阻塞OLTP请求运行),HyPer选择了fork子进程来处理OLAP请求。这样由OS和MMU来实现高效的page shadowing。基于磁盘的DB如果使用page shadowing的话会破坏page的连续性,但内存数据库就不用顾虑这点了。SolidDB[3]是另一种内存数据库,使用了tuple shadowing,比page shadowing粒度更细,据说提升了30%吞吐。
HyPer还去掉了传统RDBMS的buffer管理与page结构,所有数据结构都是专门为内存访问优化的。
HyPer中所有事务都需要写成存储过程,这些存储过程最终会被编译为可以直接访问上述数据结构。
这些优化加起来,作者表示处理一个典型的OLTP请求只需要10us。

上图中我们可以看到HyPer中OLTP与OLAP各有一个队列。当收到OLAP请求时,HyPer会fork出一个子进程来处理这个请求。这样就可以在不加锁的前提下隔离OLTP与OLAP的处理。
当然为了保证OLAP请求看到完整的snapshot,fork只能发生在两个事务之间(但后面讲到可以用undo来放宽这个限制)。
注意OLAP请求处理时可以使用磁盘,不需要像OLTP一样严格控制数据量在内存可用范围。
OLAP子进程本身是只读的,不会修改任何数据,因此可以同时有多个子进程存在。HyPer会通过绑核的方式避免这些子进程影响到OLTP的处理。
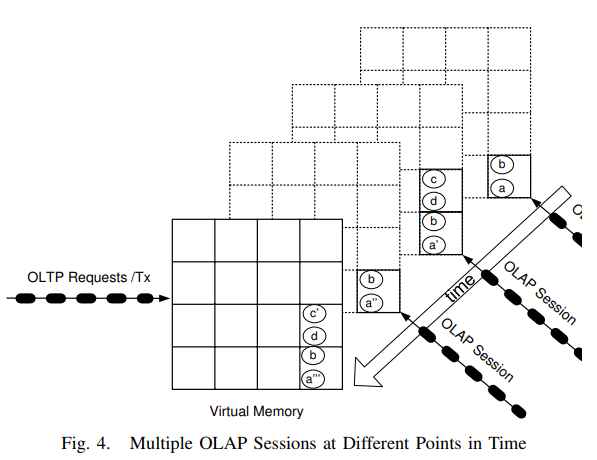
每个OLAP子进程可以服务于一个session,当session结束时退出,OS会自动释放被shadow的内存page。这里不需要担心长时间运行的OLAP请求会占用太多内存,OS的COW机制保证了每个OLAP子进程独自占用的内存量与它和它的下一个OLAP请求之间修改过的数据量相关,而与请求执行时间无关(但内存控制仍然挺难做的,需要在内存吃紧时拒绝请求吗)。
接下来作者开始试图在OLTP处理中用上多线程。首先只读事务是可以并行做的,而且现实世界中只读事务远多于有写的事务。其次有些业务天然支持分区,不同partition的事务是可以并行做的。
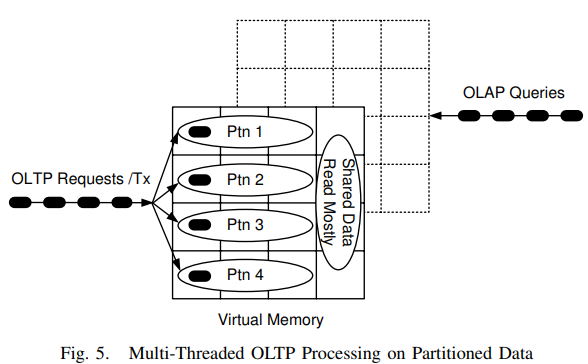
但分区就需要能处理跨分区的事务。VoltDB讨论过两个方案:悲观锁,或是乐观锁(但可能有连锁的rooback)。
HyPer的方案是在partition级别加锁,这样避免了partition内数据加锁。但这种方案只能用在单节点系统中,无法用在分布式系统中(后面有讨论)。
在分布式系统中可以把经常要读的partition复制到多个节点上,从而避免同步开销。
接下来是recovery。HyPer仍然会持久化redo log,但只需要记录logical的log。不需要记录physical log的原因是HyPer保证总能保证checkpoint是事务级别完整的,这样只要保证logical log按执行顺序恢复就行。多线程下只要保证partition级别log有序即可。
undo log不需要持久化,类似于InnoDB,undo log可以用于实现MVCC。有了undo log,OLAP子进程fork就不需要等待当时的事务完成,而是fork完成后使用undo log把所有活跃事务都rollback掉就得到了完整的snapshot。做checkpoint时也是用类似的方法。
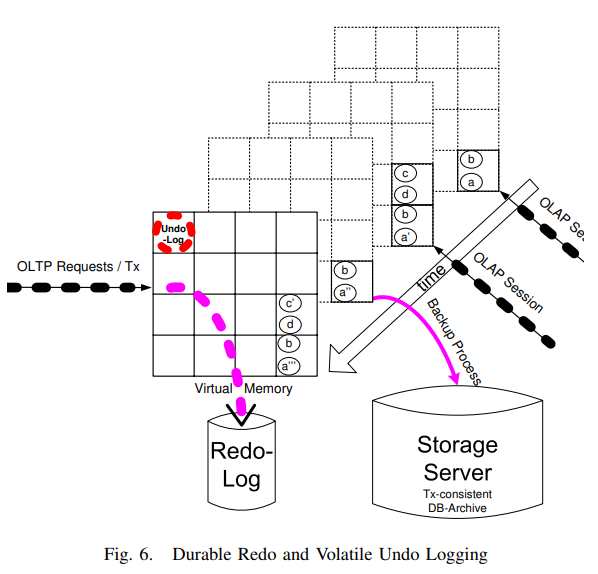
记录redo log可能成为瓶颈(毕竟有I/O),此时可以使用group commit或async commit来优化,但后者可能造成数据丢失。