原文:CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data
Ceph笔记:
- Ceph
- Dynamic Metadata Management
- CRUSH: Data Placement
TL;DR
CRUSH是一种确定性的hash算法,用来计算数据(对象)的存储位置。
Ceph中CRUSH的价值在于MDS和client都通过CRUSH来计算对象位置,这样client可以直接与OSD(Object Storage Device)通信,MDS也不需要维护对象与OSD之间的映射了。
另一方面,相比其它hash算法,CRUSH有以下优势:
- 相比平坦的hash,CRUSH支持层级结构和权重,可以实现复杂的分布策略。
- 在有节点变动时,CRUSH可以最小化数据的迁移(根据分布策略),而简单的hash则会导致大量数据迁移。
- 对failed和overloaded的设备有特殊处理。
CRUSH的策略受到两个变量的控制,一个是cluster map,其中支持多个层级,如root、row、cabinet、disk;另一个是placement rules,控制replica的数量和相应的限制。
CRUSH的输入是一个整数x(比如对象名字的hash值),输出是n个设备的列表。
cluster map中叶子节点称为device,可以有权重,其它内部节点称为bucket,权重是底下所有叶子权重之和。在选择设备时,CRUSH会根据hash一层层递归计算bucket,最终确定需要哪些device。注意:bucket本身有类型(如uniform、list、tree、straw),不同类型的bucket有不同的选择算法。
placement rules里面可以根据物理位置、电源供应、网络拓扑等条件将对象的不同replica分散开,从而降低不可用的风险。每个rule包含一系列操作,如下图。

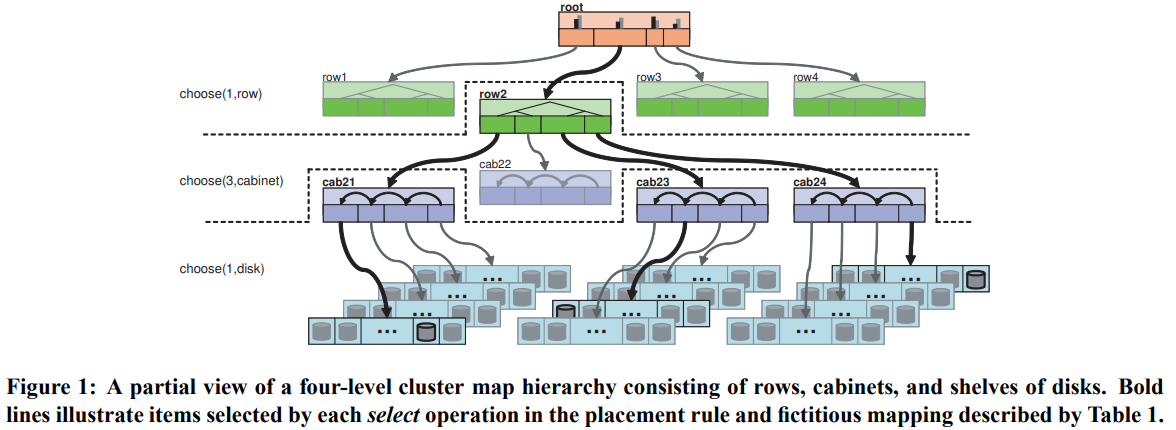
其中take表示选择一个节点加到当前列表中,select会在列表中每个节点上应用,选择n个符合条件的节点出来。
一个rule中有多个take和emit可以从不同的存储池中选择不同设备。
在选择过程中,CRUSH会考虑三种异常:
- failed和overloaded(在cluster map中标记),此时CRUSH会在当前层级重试(见下面算法的11行)。
- 冲突(设备已被选中),此时CRUSH会在下一层重试(见下面算法的14行)。
同层重试时,有两种策略:
- first n,下图中r’ = r + f,b挂了则选择后面的g、h等。这种适合于primary copy这种不同设备存储相同replica的情况。
- r’ = r + frn,b挂了则选择第2 + 1*6个设备h。这种适合于parity、erasure coding等不同设备存储不同内容的情况。
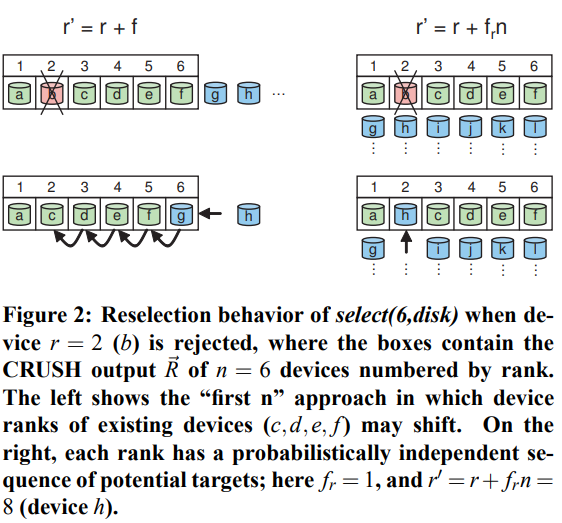

failed和overloaded两种设备都会留在cluster map中,只是有不同的标记。failed设备上的已有对象会被迁移到其它正常设备上,预期迁移比例为Wfailed/W。overloaded设备只是不再接受新对象,已有对象不需要迁移。
当有设备加入或移除时,需要迁移的数据量也与权重有关:权重被降低的子树会有数据迁移到权重被升高的子树上。
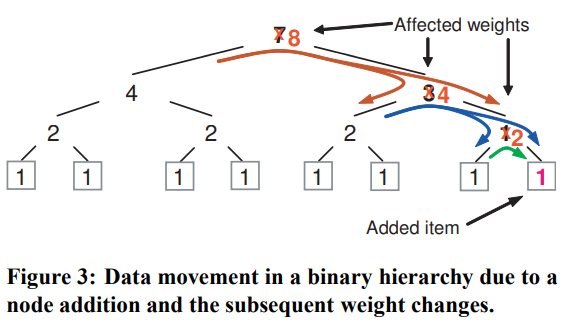
数据迁移量的下界是φ/W,而上界是hφ/W,其中h是树的高度,但达到上界的概率非常小:需要每层数据都映射到一个权重非常小的设备上。
最后是不同的bucket type。
CRUSH支持4种bucket,分别有不同的选择算法:
uniform
所有设备权重相同。公式为:c(r, x) = (hash(x) + rp) % m。其中p是某个大于bucket大小m的质数。
优点是选择的时间复杂度为O(1),缺点是一旦有设备变动,几乎所有数据都需要迁移。适合设备不怎么变动的场景。
list
有点像链表,支持权重,选择时比较head的权重与剩余权重和来决定选择head还是继续。
优点是当新设备加入时迁移量最优(与权重比例相同),缺点是当移除非head节点时会引起大量数据迁移(越接近tail越多)。适合设备几乎不移除的场景。
tree
根据左右子树的权重和选择插入路径。为了避免树扩张或收缩过程中节点的label发生变化,tree bucket使用了一种路径标记的方式(左子树1,右子树0)来生成label。

straw
这种似乎用得比较多?根据item和节点的权重,每个节点生成一个hash值,然后选择其中最大的那个。
c(r, x) = maxi(f(wi)hash(x, r, i))
