原文:Dynamic Metadata Management for Petabyte-scale File Systems
TL;DR
这篇文章介绍了Ceph的Metadata Server(MDS)如何管理metadata,尤其是如何做目录树的动态负载均衡。
(不是很有趣……)
文章首先强调MDS的重要性:
尽管metadata在数据量上只占了非常小的一部分,但操作数上却可以超过50%。
另一方面,metadata又很难scale,因此很容易成为大规模分布式文件系统的瓶颈。
Ceph的解法是:
- client通过CRUSH算法获得数据位置,不需要询问MDS。
- 维护树型的metadata结构,可以动态均衡任意子树。
- 优化常见workload。
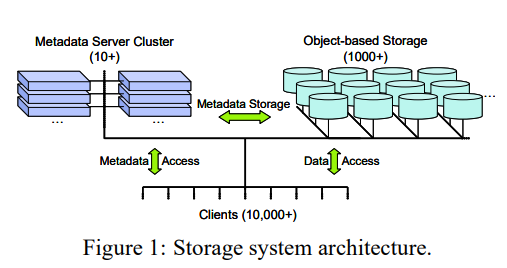
这里第一条很重要,询问数据分布是高频操作,client自己计算就能得到就极大降低了MDS的负担。另一方面MDS只需要为每个文件维护很少的固定长度的meta,可以在内存中维护更多文件的metadata。
MDS需要执行的操作可以分为两类:
- 应用在文件和目录的inode上的操作,如
open、close、setattr。 - 应用在目录项上,可能会改变层级结构的操作,如
rename、unlink。
另外还有一些非常常见的操作序列,如:
open加上close。readdir加上大量stat。
其它系统的常见设计有:
树型结构,但子树到server的映射是静态的,如NFS等。这种设计的优点就是简单,缺点就是难以适应workload的变化。
平坦结构,hash分布。
这种设计优点非常多,但缺点是:
- 无法消除单个文件的热点。GFS使用了shadow server来分担压力。
- 更严重的是,hash消除了层级结构的局部性。比如POSIX语义要求文件的ACL检查需要向上而下遍历所有目录项的ACL,hash会导致这个过程访问多个server。
Lazy Hybrid(LH)在每个文件处维护它前缀目录项的ACL,这种设计将压力从check ACL转移到了update ACL,而后者的频率远低于前者,且可以异步进行。有分析指出update的开销可以分摊到每个文件一次网络trip。但这种设计仍然丧失了局部性,且依赖于对workload的强假设。
Ceph保留了层级结构,但不同子树可以位于不同MDS上:/usr和/usr/local可以位于不同MDS上。这种设计既保留了局部性,又能灵活分散压力。为了降低ACL检查的I/O开销,MDS会保证cache中每个inode的所有前缀inode也在cache中,始终维持层级结构,cache expiration一定从叶子开始。这样在检查ACL时就不需要任何额外I/O了。
MDS之间有主备replication,每个metadata项都有一个leader MDS,所有修改必须由leader进行,leader也有责任保持replica的cache的一致性。比如:
- 如果某个item被载入到replica的cache中,leader就需要将这个item的更新同步给replica。
- 当replica换出某个item时,也需要通知leader。
(听起来挺难维护的)
某些特定操作(如更新mtime和file size)也可以由replica来执行,定期告知leader即可。
当子树需要在MDS之间迁移时,旧leader需要把所有活跃状态和cache都传输给新leader,既是为了保持cache一致,也是为了减少failover的I/O。
(讨论load-balancing策略的部分略)
作者的心得:
- 平衡的workload分布不一定能达到最大的总吞吐。
- 不是所有metadata项都平等重要,离root越近,往往越重要。
接下来为了处理热点文件,可以牺牲一些一致性:非热点文件必须由leader处理,热点文件可以由replica处理只读请求。这里需要MDS与client之间交换信息,让client有足够的信息能路由到replica上。
最后是如何利用局部性。
Ceph利用局部性的方式是尽可能地将直接相关的信息保存在一起,还要做预读。传统的文件系统会有一个全局的inode表,这种设计在单机系统中对性能有明显的好处:访问更集中,更容易缓存,减少磁盘I/O。但在分布式系统中这种设计就不太适合了。Ceph是直接将inode保存在对应的目录项中,这样readdir可以直接返回整个目录的信息。
但缺乏全局inode表也导致了几个问题:
- 需要能分配全局唯一的inode id。
- 只有管理对应目录的MDS才能知道哪些inode在使用,这些MDS需要记住client正在使用的inode(比如文件被逻辑删除后要保留对应inode)。
- hard link很难处理。我们知道通常hard link是非常罕见的,因此Ceph对于hard link做了特殊处理,使用一个global inode table保存所有hard link。