与Percolator和Omid类似,Deuteronomy也是为多个数据节点提供分布式事务能力的。在Deuteronomy中,提供事务能力的中心节点称为transactional component(TC),数据节点称为data component(DC)。
与Percolator和Omid不同的是,Deuteronomy类似于ARIES,提供的是悲观锁,不需要MVCC支持。它的TC和DC更像是传统的单机RDBMS的一种功能拆分,相互功能依赖比较多,而不像Percolator和Omid一样依赖于分布式KV。
目测Deuteronomy性能不会太好(没有MVCC)。
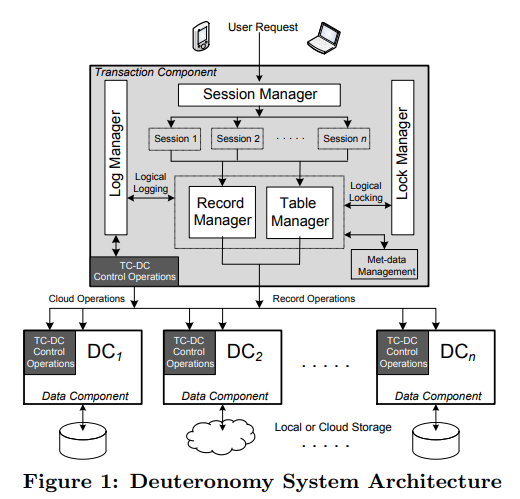
Deuteronomy中TC拥有传统单机DB的除了buffer pool之外的全部组件:
- Session manager
- Record manager
- Table manager
- Lock manager
- Log manager
DC需要维护buffer pool与storage。
无论TC还是DC都需要支持多线程。
Session manager负责维护与client之间的session,保证每个session同时间最多执行一个事务。
Record manager提供record层面的接口,它也需要与table manager、lock manager、log manager交互。
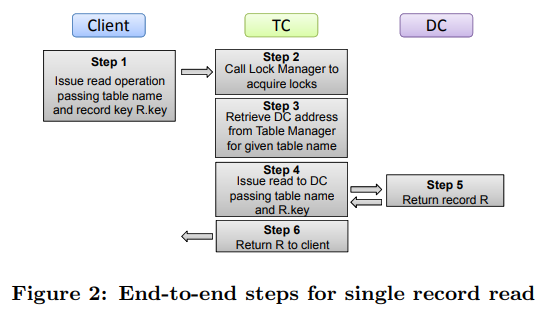
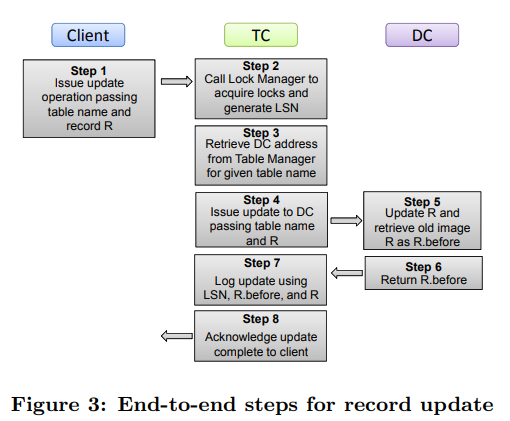
无论读写请求,第一步都是要加锁。之后读请求会直接转发给对应的DC。写请求的流程则是:产生LSN、写请求发给DC、写log、放锁、回复client。
几个需要注意的点:
- Record manager需要先加锁再产生LSN,这样保证相互冲突的事务间LSN顺序与加锁顺序一致。但整体上log中LSN是不保证顺序的。
- 先写DC,拿到response(里面包含before value)再写log,这样看起来违背了WAL(不ahead了),但保证了log只写一次。因为Deuteronomy只提供悲观锁,在这个事务放锁之前DC对应的page不会被其它事务读到,而TC也能保证如果事务最终abort了,DC会收到rollback;TC如果挂了,在recovery阶段可以令DC状态回退到一个一致的状态 。
- DC需要支持幂等写入,且保证完全按照TC的控制指令来刷盘。
Table manager负责两件事:
- 管理table/column的meta,保存到某个特定的DC中。
- 管理table的逻辑partition(按key range),作为介于table与record之间的加锁粒度。这是因为TC不管理数据,无法实现按page加锁。
Lock manager有几点要注意:
- 提供table/partition/record三种粒度的锁。
- partition粒度的锁用来提供range lock。
- 不提供next key lock,原因是TC不管理数据,如果要查询next key就需要访问一次DC,开销太大。
Log manager是ARIES风格的,但有几点区别:
- 只记录logical log(per-record),因为TC不管数据。
- log中LSN不保证顺序(如果保证顺序就需要等待LSN更小但更晚结束的事务)。
Log manager的复杂性来自TC与DC的分离,TC管理log,DC管理buffer pool,这样TC与DC间就需要通信来保证log与cache一致。
具体而言,TC会向DC发送两种指令:
- End Of Stable Log(EOSL):发送eLSN给DC,表示这之前的log都已经刷盘成功,DC可以放心将所有LSN <= eLSN的page刷下去了(可以不刷,但不能越过eLSN刷盘)。
- Redo Scan Start Point(RSSP):发送rLSN给DC,表示DC一定要把这之前的数据刷下去。所有DC的RSSP返回之后,TC就会更新checkpoint,后面recovery时就从RSSP开始。
具体执行EOSL的流程
TC维护一个LSN-V(LSN的数组),从上次的eLSN开始,按LSN排列,每项都是<LSN, LP>(LP即log point,log中的物理位置)。需要发送EOSL时,记当时持久化好的log位置是sLP,则遍历LSN-V,直到找到某项为空(表示这个事务还在执行中)或LP超过了sLP。
具体执行RSSP的流程
值得注意的是rLSN是发送给DC强制刷盘的,但TC自己记录的则是rLP,两者不一定对应,但需要满足:
- 任何LSN <= rLSN的log都应该已经持久化了,暗示着rLSN可以是某个过去的eLSN。
- 任何LSN > rLSN的log,其LP >= rLP,保证recovery阶段不会漏掉这条log。
我们在LSN-V的基础上,每次执行EOSL时记录三个值:eLSN、sLP、maxLSN,其中maxLSN表示当时最大的LSN。这样我们就得到了EOSL-V(前面三元组的数组)。这三个值的关系为:eLSN <= sLP.LSN <= maxLSN,eLSN.LP <= sLP <= maxLSN.LP
我们先确定rLSN。初始的rLP可以是E[0].sLP,对于E[i].eLSN >= E[0].maxLSN,我们知道它的LP也大于E[0].sLP,这样就满足了对rLSN的2个要求。任何这样的eLSN都可以作为rLSN。
在确定了rLSN后,我们再去找最大的满足j,满足rLSN >= E[j].maxLSN,则E[j].sLP就是rLP。
整体流程
优化
两种优化:
- Fast Commit,即log进队列后就放锁,之后等刷盘成功再返回client。因为log是按队列顺序落盘的,这样整体结果是确定的。代价是只读请求也要有空log进队列(这个代价其实有点大)。
- Group Commit。