原文:Taking Omid to the Clouds: Fast, Scalable Transactions for Real-Time Cloud Analytics
Omid三部曲:
- Omid: Lock-free transactional support for distributed data stores
- Omid, Reloaded: Scalable and Highly-Available Transaction Processing
- Taking Omid to the Clouds: Fast, Scalable Transactions for Real-Time Cloud Analytics
这是Omid的第三篇(2018年),主要改进是提出了两种降低延时的新协议,从而满足新的实时事务的需求(作为Phoenix的后端)。
两种新协议分别是:
- Omid Low Latency(Omid LL),将Omid中写CT的工作由TM转交给client,从而分散了负载,降低了延时。
- Omid Fast Path(Omid FP),处理单key事务时绕开TM,从而达到原生HBase操作的延时(代价是隔离级别从snapshot isolation(SI)降低到了generalized snapshot isolation(GSI)[1])。
Omid再改进就要考虑分散冲突检测了。
Omid LL中TM有两个角色,一个是TSO,通常不会是瓶颈;另一个是全局冲突检测。我们知道Omid中冲突检测是per bucket进行的,每个bucket独立判断。假如bucket足够小,小到只有一个key,就相当于每个key独立判断一下冲不冲突。此时TM的必要性就不存在了,client可以直接与data server通信判断。
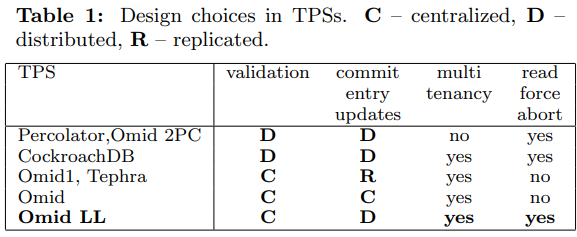
此时Omid就变成了Percolator的变种,即将commit meta放到了单独的commit table中,而不是与数据在一起。
Omid LL
Omid 14中TM在内存中维护事务meta,还需要与client保持meta replication,负担比较重,成为了全局吞吐的瓶颈。
Omid 17因此增加了commit table(CT),将事务meta信息下放到表中,这样client不需要meta replication,直接查询表就可以得到事务信息。但Omid 17中的CT只由TM更新,又成为了新的全局瓶颈。
Omid LL的主要改进就是由client来写CT,从而极大降低了TM的负载,后者主要工作只剩下TSO和冲突检测。
Omid LL中TM的Commit只会返回一个timestamp:

主要工作都转交给了client:

注意READ中有几个race condition需要考虑:
- 如果rec中的commit为空,对应的事务可能pending,也可能在post-writing,client需要通过一次get or abort来判断。
- 如果CT中没有对应事务,client需要再读一次rec,如果发现又有commit了,就说明刚刚对应事务已经完成了post-writing和清理CT,client需要把自己插入CT的abort再删掉(如果没删掉也没关系,后面清理任务会做的)。
在COMMIT的post-writing阶段,Omid 17需要读出修改过的每一行再执行清理或写入commit,Omid LL则改成了blind write。这里没有正确性问题,因为每个事务的write set只有一个writer,client实际拥有所有需要的信息,不需要每行再读一次。
Omid FP
Omid FP提供了几个针对单key的事务API,将事务的BEGIN和COMMIT并入后续的一次读写操作中,从而降低延时。
几个API为:
brc(key):BEGIN,读key,COMMIT。bwc(key, val):BEGIN,写key,ts大于已有版本,COMMIT。br(key):BEGIN,读key,返回value和对应版本,不COMMIT。wc(ver, key, val):检测key没有大于ver的写入,写key,ts大于已有版本,COMMIT。
注意br和wc要配套使用。
Omid FP的实现分为两部分,分别由client和HBase server(通过coprocessor)提供:

可以看到brc和br实际就是HBase的get。
bwc需要看key的当前版本是否已经提交了,如果遇到了未提交的版本就直接abort。这里为了降低延时,没有像client的READ一样尝试abort掉对应的事务。
bwc和wc需要产生一个新的version,需要保证以下性质
- 新version大于所有旧version,但小于未来TM产生的version。
- 能检测出与普通事务的冲突。
这就与TM作为全局TSO冲突了。为此Omid FP引入了HLC,TM的timestamp作为physical ts,在putVersion中只增加logical ts。如果非常罕见地logical ts满了,这个FP的事务会被abort掉,client可以使用普通路径重试。
如果普通事务早于FP事务写入,前面提到了FP事务会abort。但如果FP事务在某个普通事务的读和提交之间完成了:

因为FP事务不在CT中记录,旧的检测机制失效了。为了能让T1提交时检测出冲突,Omid FP做了以下改动:
- 每个key对应一个maxVersion,保证不小于这个key的任何已提交版本。
putVersion提升maxVersion。- 普通事务的读会提升maxVersion到不小于事务ts。
- 普通事务的写会检查maxVersion不大于事务ts。
这个改动增加了普通路径的开销。为了降低内存使用,Omid FP在每个HBase的region server上维护了一个local version clock(LVC),即整个server的maxVersion。这个优化增加了false abortion,但降低了维护代价。
LVC不会持久化,每个region server在第一次请求处理中会访问TM获得physical ts。