原文:An Integrated Approach to Recovery and High Availability in an Updatable, Distributed Data Warehouse
TL;DR
这篇文章介绍了HARBOR,一种针对高可用数仓的新的恢复与高可用机制。相比传统的基于ARIES的系统,HARBOR不依赖log,而是利用冗余replica,在恢复时query其它replica来恢复数据。
总的来说不太适合作为生产系统,错误处理与恢复流程需要考虑非常多的corner case。K-safety机制似乎是database社区对distributed system社区的一种反抗(我偏不用Paxos)。
ARIES的瓶颈在于必须同步写的log
-> 宕机怎么处理:可以query其它active的replica来恢复数据。
-> 怎么知道要恢复哪些数据:通过monotonic timestamp。
-> 如何减少需要恢复的数据量:定期做checkpoint。
不同replica之间只通过SQL query传递数据,这种松耦合的关系允许不同replica有不同的数据组织方式,如行/列格式、列排序、压缩编码、视图等都不需要相同(受到了C-Store的启发)。这样每个query可以由最适合的replica服务,进一步提升了性能。
HARBOR也使用了MVCC,每个replica会维护一个时间T,保证所有活跃的transaction都不早于T,这样读T之前数据的query(historical query)就不需要锁机制保护了。这种机制也是源自C-Store。
具体到实现上,每个tuple有insertion和deletion两个timestamp,T时间可见的tuple需要满足insertion ts <= T < deletion ts。
HARBOR的容错机制也源自C-Store,称为K-safety,即最多允许K个replica同时宕机,最小需要K+1台机器。K-safety的前提是至少有一个replica是完整的,这就对恢复速度有要求。如果上一轮宕机还没恢复完,其余replica又宕机了,或者有超过K个replica宕机,则此时需要依赖checkpoint或冷备数据来恢复。
值得一提的是,HARBOR假设所有错误都是fail-stop错误,不处理拜占庭问题、网络分区(network partition)、数据损坏(HARBOR的恢复机制处理不了部分损坏)、磁盘页不完整等。(容错机制制约了HARBOR的实用性)
恢复过程:
- 每个checkpoint对应一个safe timestamp T,小于等于它的所有commited修改都保证已落盘。实现上是在做snapshot的时候会强制刷dirty page。
- 将本地状态恢复到T:
- 执行DELETE删除所有insertion ts大于T或未提交(为特殊值)的数据。
- 执行UPDATE恢复所有deletion ts大于T的数据。
- 使用T去其它active replica上执行historical query,因为historical query不需要加锁,这个操作不会影响被读的active replica上的事务执行。
- query所有insertion ts <= T且deletion ts > T的数据,并本地执行删除。
- query所有insertion ts > T且小于等于historical水位的数据,并本地执行插入。
- 从其它active replica上获得最新数据,需要加读锁,但因为数据量不多,影响会比较小。在这一阶段coordinator会重新将请求发往正在恢复的节点,包括它宕机期间coordinator上缓存的请求。
如果节点在最后一个阶段又宕机了,此时它还拿着其它节点的读锁。HARBOR的解法是通过某种错误检测机制,如外部检测并抢占,或通过lease自动放锁。
coordinator会有一个内存队列,里面是所有未执行完的transaction。coordinator负责为transaction分配insertion和deletion timestamp,因此HARBOR需要各节点间有某种时间同步机制(此时HLC还未问世)。另外HARBOR中会有一个coordinator定期提升所有节点的epoch,同时也提升了historical query可读的范围。
HARBOR中未提交的transaction不会落盘或生成timestamp,worker会在内存中hold这些未提交的transaction的修改,同时作为undo log。如果buffer pool支持STEAL(dirty page不需要等到所有相关的transaction都提交就可以刷下去),则这些修改的insertion ts会是一个特殊值,在恢复时会被忽略掉。
为了支持高效的query by timestamp,HARBOR会将数据按insertion ts切分为若干个segment,每个segment中数据按primary index排序,另外还会分别维护其它index。每个segment会维护最小的insertion ts和最大的deletion ts,如果query的T不在此范围,会直接跳过这个segment。
这种基于timestamp切分segment的方式还有两个好处:
- Bulkload可以直接写新segment,不需要走一遍加锁流程。
- 时间序列属性的业务可以直接丢弃旧的segment。
正常的2PC流程中需要三次同步写log:
- prepare阶段每个worker要在回复OK前写盘。
- coordinator在准备COMMIT或ABORT前要写盘。
- worker在COMMIT或ABORT时要写盘。
常见的group-commit优化只针对吞吐,对延时没有帮助。但注意到worker的两次同步写实际上都是为了恢复:COMMIT或ABORT可以本地判断事务状态,PREPARE则需要询问其它节点。
HARBOR的K-safety机制下,worker不需要这两次同步写,原因是它可以通过识别特殊值来跳过未提交的修改(从而不需要PREPARE或ABORT),并通过historical query获得其它节点的已提交修改(从而不需要COMMIT)。

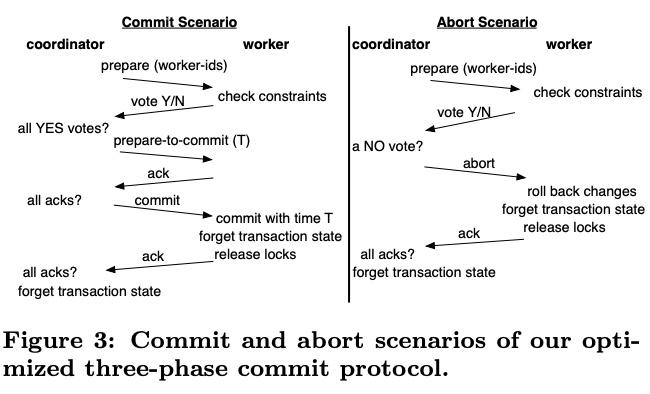
HARBOR的优化版本的2PC中coordinator仍然有一次同步写,而在对3PC进行改进后,HARBOR可以省掉所有同步写,移除所有需要落盘的log,从而进一步提升事务性能。
改进的3PC的关键是coordinator宕机后,backup会根据自身状态判断后续操作:
- 如果backup在PREPARE阶段没有投票或在任意阶段投了反对票或有ABORT记录,则直接ABORT当前事务。
- 如果backup处于PREPARED状态且投了YES,它要先要求其它参与者到达PREPARED状态,再发送ABORT(为什么不推进事务?)。
- 如果backup处于PREPARED-TO-COMMIT状态,它会用之前确定的commit ts重复3PC的前述流程。
- 如果backup处于COMMITTED状态,它会直接发送COMMIT给各个参与者。
(如果backup没有参与这次事务呢?这套机制似乎不允许coordinator并发处理请求。)
benchmark就略过了。