TL;DR
我们都知道数据库开销的大头是I/O,但在现代机器架构下,CPU与内存的交互成本也不容忽视。这篇文章比较了四种商用数据库在三种典型场景下的性能分解,得出结论:
- 一半的执行时间实际是在停顿(stall)。
- 90%的停顿是因为L1指令cache miss与L2数据cache miss导致的,而L2指令cache miss与L1数据cache miss则不重要。
- 20%的停顿是因为实现细节(如分支预测失败等)。
- 内存访问延时对性能的影响大于内存带宽的影响。
- 更快的CPU与缓存、内存的延时差距越来越大,以上因素会更加明显。
这篇文章是1999年的,机器是PⅡ,在当前(2021年)的系统中本文的结论仍然有效,且可能有更大的影响。
现代CPU执行模型
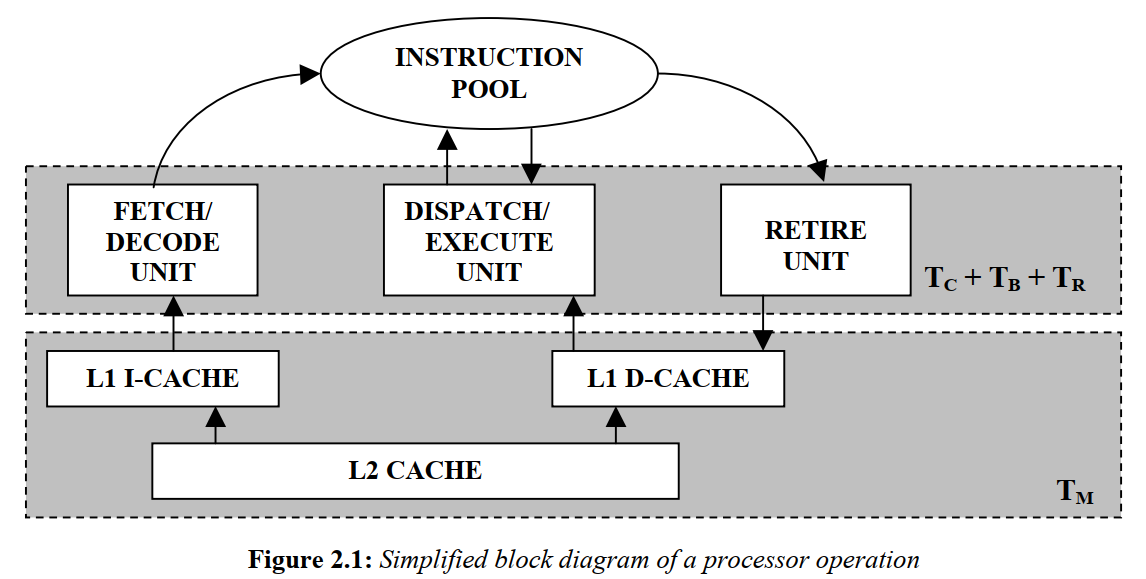
上图是简略的PⅡ执行过程:
- FETCH/DECODE模块将用户指令翻译为微码并放到池子里;
- DISPATCH/EXECUTE模块根据指令依赖关系与资源可用性来调度可运行的指令,并缓存指令结果;
- RETIRE模块决定何时提交或丢弃指令结果。
当有指令无法继续(停顿)时,CPU会尽量降低它的影响:
- cache miss时会将请求转发给下一层(L1->L2,L2->内存),之后cache可以继续服务其它请求。
- 乱序执行:指令X停顿时,可以执行与它没有依赖关系的指令Y。
- 分支预测:遇到分支时,CPU不会在那等分支结果,而是会预测一个分支开始执行,如果预测对了就提交指令结果,否则需要清空流水线、丢弃临时结果、重新从池子中取指令。因此分支预测失败同时会有计算与停顿的开销。
以上方法会使得一些步骤的时间有重叠,因此处理时间TQ = TC + TM + TB + TR - TOVL,其中TC是纯计算时间,TM是内存引起的停顿时间,TB是分支预测失败引起的停顿时间,TR是资源不可用引起的停顿时间,TOVL是各步骤的重叠时间。

上表是更细的分解,其中LxD代表数据cache,LxI代表指令cache,DTLB代表数据TLB,ITLB代表指令TLB。
当L1D cache miss不太高时,TL1D是可以与其它步骤完全重叠的,此时CPU可以处理其它指令,等待L2D返回。L1D cache miss越多,隐藏它需要执行的其它指令数越多。当有足够多的请求同时访问内存时,L2D cache miss就可以相互重叠从而隐藏停顿。TDTLB也可以与其它指令的执行重叠在一起。
相比之下指令cache的停顿则比较难隐藏,因为当没有指令可以执行时CPU只能等待。分支预测失败也会产生类似的瓶颈。指令预取可以缓解指令cache的停顿,但有时反而会增加分支预测失败的代价(为什么)。
尽管与指令执行有关,TR还是要比TITLB和指令cache miss更容易隐藏。程序的指令并行度越高,TDEP越容易隐藏;功能单元竞争越小,TFU越容易隐藏。
测试相关
Query
表模型:
1 | CREATE TABLE R (a1 INTEGER NOT NULL, |
Query 1:Sequential range selection。
1 | SELECT AVG(a3) |
Query 2:Indexed range selection,与Q1的区别只在于a2上有non-clustered index。
Query 3:Sequential join。
1 | SELECT AVG(a3) |
其中S与R结构相同,S中每条记录对于R中30条记录。
软硬件
- CPU:PⅡ Xeon 400MHz;
- 内存:512MB;
- OS:Windows NT 4.0 SP4;
- DBMS:四个匿名的商业数据库A/B/C/D。
- 测试工具:Intel提供的emon,可以测量多达74种事件。


结果
执行时间分解
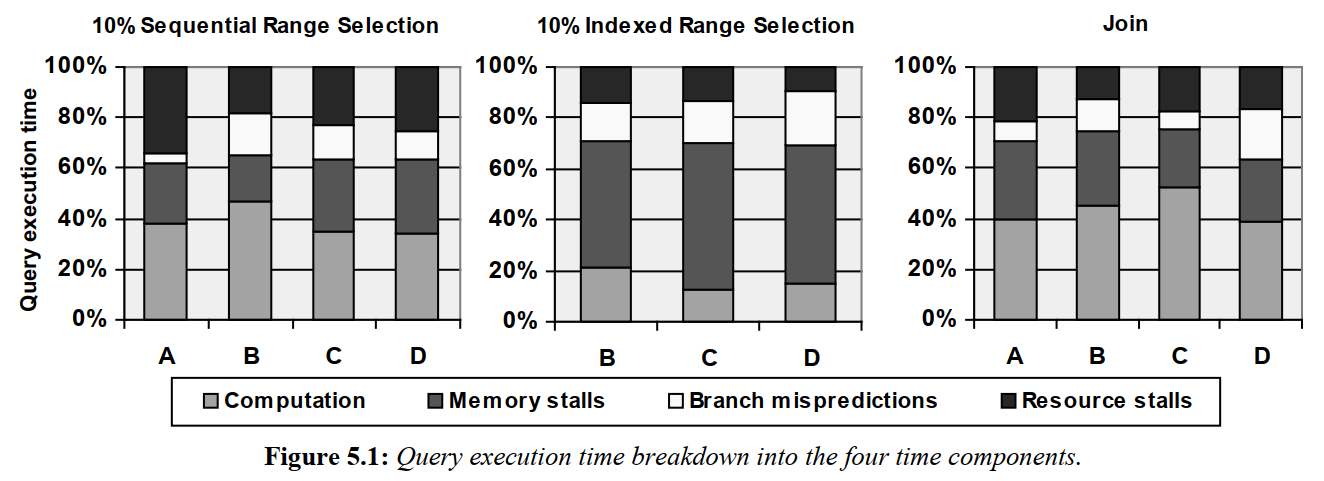
A的Q2结果无效,因为它执行时不走索引。
可以看到所有系统的纯计算时间都少于50%,其中Q2的内存停顿影响最大(non-clustered index导致的cache miss)。除了内存停顿外,分支预测失败与资源不可用导致的停顿也对性能有着巨大的影响。观察A的表现,它的TM+TB往往好于其它系统,但TR则更高,说明优化完两种停顿后,瓶颈跑到了第三种停顿上。
内存停顿

将内存停顿时间分解后,我们发现,L1D miss的影响非常小,且因为测试中没有去掉L1D miss被重叠的部分,它的实际影响要更小。进一步的分析发现DBMS访问内部结构的次数远多于访问用户数据,L1D足够装下这部分数据,因此L1D miss主要是在访问冷的用户数据,不是瓶颈。
L2I miss和ITLB miss的影响也非常小,因为L1I与ITLB足够装下指令与相关的页表记录。
L2D miss则造成了巨大的影响(除了B,它对此有优化),且当记录变大时(访问的数据比例变低)L2D miss也变多起来。L2D miss的影响如此之大是因为内存延时高达60-70个周期(现在可能达到100+),即使测试结果中没有去除并行的内存访问的相互重叠,TL2D也不会太低。
随着cache与内存的速度差距越来越大,L2D miss的影响也会越来越大。cache没办法无限增加,更大的cache意味着更高的成本,往往还有更高的延时。
有了L3 cache后,瓶颈会转移到L3 cache miss上。
L1I也造成了巨大的影响,如前面所述,指令的cache miss会导致CPU无法工作。有些技术可以降低指令cache的停顿时间、提升指令cache的使用效率(参见CSAPP),但因为L1 cache大小有限(太大的L1 cache的延时会降低和拖慢CPU时钟)。DBMS可以将常用指令与不常用指令分开,如将错误处理的代码从正常代码逻辑中剥离出来到单独的位置。
一个意想不到的发现是记录越大L1I miss越多。我们知道记录越大,L1D和L2D的miss越多,而因为指令与数据共享L2,L2I的miss也会随之增加。但为什么会影响到L1I?一种解释是有些CPU有一种机制,当L2 cache被替换时,对应的L1 cache也会被强制替换掉。但PⅡ Xeon没有这种机制。另一种解释是OS会定期中断DBMS,并将L1I替换为OS自己的指令,在DBMS恢复后再重新载入它自己的指令。记录越大,执行单个记录的时间越长,中断次数越多,L1I被替换次数越多。第三种解释是记录越大,跨page的记录比例越高,buffer pool相关代码的执行次数越多,这部分指令相对较冷,其它热指令被替换的次数越多。
分支预测失败
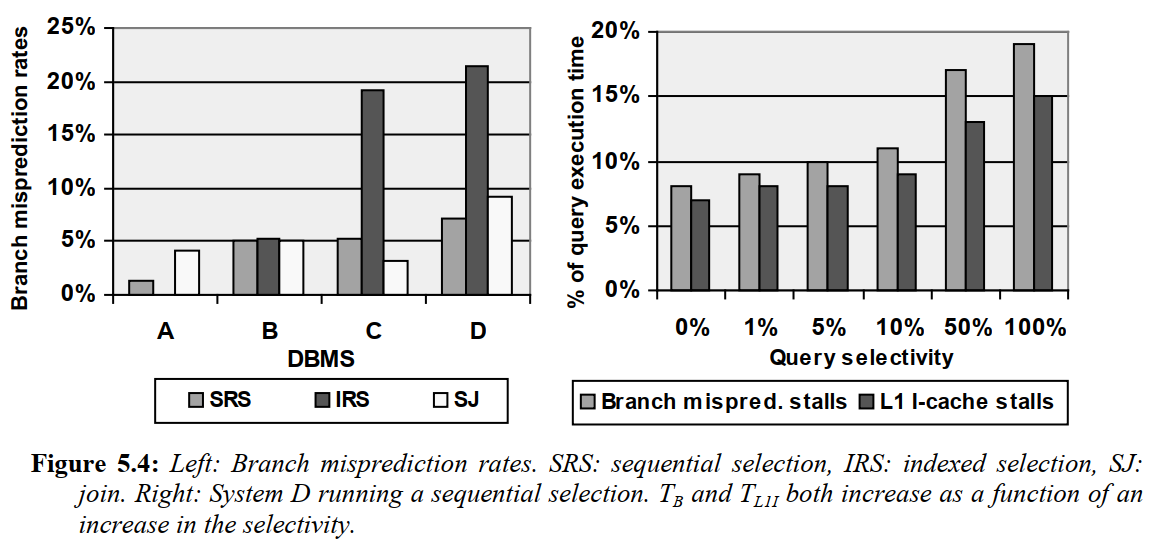
- 分支预测失败率与记录大小或选择率基本无关。
- 更大的Branch Target Buffer(BTB)可以提升OLTP场景的分支预测成功率。
资源停顿

资源不可用是因为:
- 指令相互依赖,指令并行度低;
- 大量指令同时争抢功能单元。
X86下机器指令会被翻译为微指令再执行,因此编译器没有简单的手段来发现跨机器指令的依赖关系并在微指令层面上优化。
TPC-D与TPC-C


TPC-D的停顿主要由L1I引起,这方面的优化能很大程度上提升复杂query的性能。
TPC-C的停顿主要由L2D与L2I引起,且资源停顿比其它几个场景都高。