Amazon Aurora目前有两篇文章:
- 2017年的Amazon aurora: Design considerations for high throughput cloud-native relational databases。
- 2018年的Amazon aurora: On avoiding distributed consensus for i/os, commits, and membership changes。
其中第一篇内容比较多,重点讲架构与实现;第二篇重点讲的是细节,比如一致性、优化、恢复过程、成员变更。
Deep Dive on Amazon Aurora这个slide还介绍了很多paper中没提到的特性,比如cache在DB进程之外、锁优化、索引构建优化等。
背景
在Aurora之前,云数据库有两个思路:
- RDS,单机的MySQL/PostgreSQL几乎原封不动地移到VM上运行,底下是云存储(EBS),我们称这种为shared-disk,属于计算存储分离的架构。扩展计算节点需要分库分表。
- Spanner,将数据水平切分为若干个shard,由多个节点服务,相互不共享数据,涉及到不同节点的事务需要使用两阶段提交(2PC),我们称这种为shared-nothing。
shared-disk的优点是最大限度保证兼容(MySQL/PostgreSQL),通常只需要动存储层,不需要改上面的query解析、plan生成等,另外不涉及分布式事务,性能比较稳定;缺点就是规模上不去。
shared-nothing的优点是架构更scalable,缺点就是很难保证与已有应用的完全兼容,另外单shard事务与多shard事务性能会有区别,分布式事务开销比较大。
Aurora仍然是顺着RDS的shard-disk的思路演进。它要解决的最大问题是RDS的网络吞吐问题。
写放大
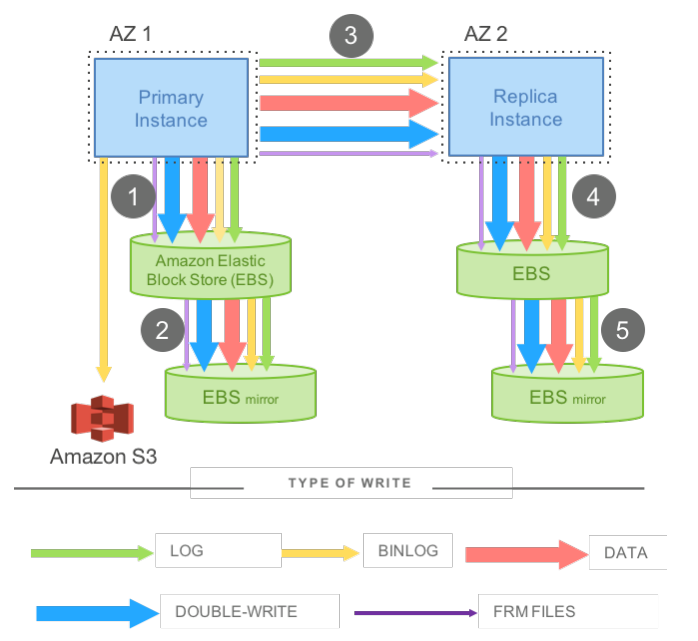
如上图,一个MySQL进程会产生如下写流量:
- redolog
- binlog
- data block
- double-write
- frm文件
而为了实现高可用,通常用户会将主备实例分别放到两个AZ,每个AZ再分别有两份存储。两个AZ的实例之间会采用block级别的replication。这样的架构有两个问题,一是写放大非常严重,会产生非常多的网络流量,考虑到计算节点是单点,它的网络带宽就成为了瓶颈。二是上图中的1、3、4是串行同步的,多几跳网络会增加延时,还会显著增加延时抖动的概率(OLTP场景非常在乎延时抖动)。
这几种写流量里,binlog和frm可以放到一边(可以单独存储),对于redolog、data、double-write,Aurora的解法就是只写redolog,将其它的page管理全都offload到存储层,也就是“THE LOG IS THE DATABASE”。
架构
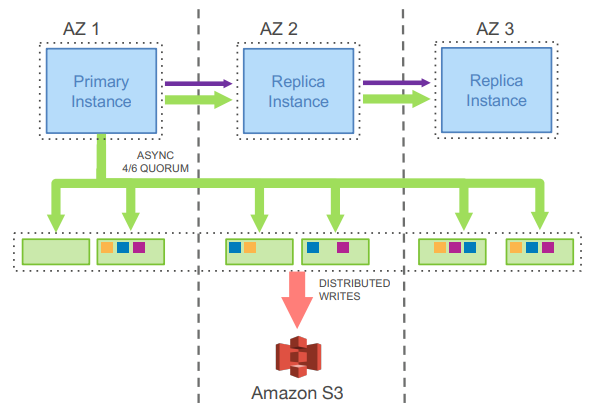
Aurora默认会部署到三个AZ中,可以有一个可写的主实例与多个只读实例。
每个DB的数据会切为若干个10GB大小的Protection Group(PG),10GB这个大小可以保证单个PG副本的MTTR不会太长(在10Gbps的网络下10秒内可以恢复一个副本),从而提升可用性。整个DB最大是64TB。
每个PG在每个AZ会写两份数据,这样一共是6份存储,每份称为一个Segment。一致性协议上Aurora仍然延续了Amazon的传统,使用了6/4/3的quorum协议,即6份存储、写至少要4份、读至少要3份。
使用quorum协议而不是MultiPaxos/Raft有两个好处,一是网络少一跳(不需要经leader转发),二是quorum能容忍单个Segment的写出现空洞,可用性更高。
采用这种配置的目的是能在1个AZ整个挂掉的情况下继续服务写,在1个AZ加1份存储挂掉的情况下继续服务读。
情况一:不考虑机房整体失效的情况下,如果只有一个副本损坏,由于写请求至少写入4个副本,4-1=3,那么读请求仍然可以读到3个相同的副本,因此读写请求仍然可以成功。
情况二:假设一个机房整体失败了,Aurora设计的巧妙之处就在于,它会把读写的Quorum模式改为“总共4副本、写入最少3副本、读出最少2副本”这种模式,即4/3/2模式。
情况三:假设失败的机房又恢复了,那么系统再把它的Quorum模式改回“总共6副本、写入最少4副本、读出最少3副本”模式,即6/4/3模式,然后开始慢慢的修复数据。
综上所述,Aurora最美妙的设计在于通过变换Quorum模式来解决单个机房长期失败的问题。
存储层
Aurora最大的创新就是将复杂的page管理放到了存储层。
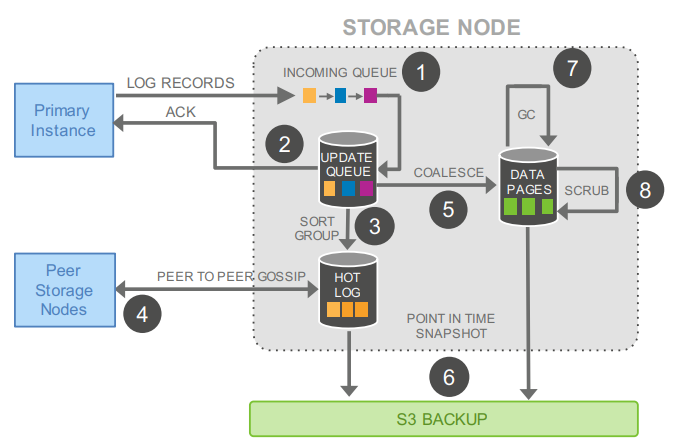
DB将redolog写进存储层的UPDATE QUEUE之后就返回了,之后存储层内部完成log补齐(quorum协议会导致每个Segment的log不全,相同PG的不同Segment之间会通过gossip协议交换log record)、page管理(应用log、多版本管理、垃圾回收)、备份到S3等操作。
存储层每个节点有本地的SSD盘,同时数据定期会备份到S3上(没有使用EBS)。
实现
一致性保证
Aurora的一致性保证的前提是单写多读(实际支持多写,但论文中没提,似乎多写也不保证全局唯一顺序,这里不讨论),由唯一的写实例来控制存储的整体推进,从而在quorum协议(通常被认为只能保证最终一致性)基础上实现了DB需要的各种一致性。整个过程中PG的各个副本(Segment)之间不会有任何的信息同步,保证了低开销。
第二篇paper中有一句话:“Storage nodes do not have a vote in determining whether to accept a write, they must do so”。
DB负责为每个log record分配一个单调增的Log Sequence Number(LSN)。
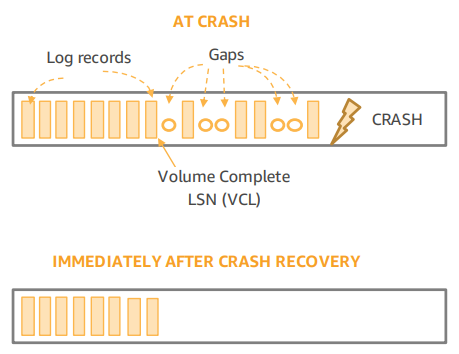
每个Segment收到的log可能是有空洞的,其中Segment Complete LSN(SCL)表示最大的保证完整的LSN,即这个Segment在SCL之前是完整、没有空洞的。
DB可以根据每个Segment的SCL生成Protection Group Complete LSN(PGCL,即PG的最大完整LSN)和Volume Complete LSN(VCL,即Volumn的最大完整LSN)。
下图说明了PGCL和VCL的区别。PG1只保存奇数LSN,PG2只保存偶数LSN,则PGCL1为103,PGCL2为104,VCL为104。

每个DB事务在存储引擎这里可能会分为若干个mini-transaction(MTR),如页面的分裂合并等,每个MTR可能包含多个log record,在恢复时要保证MTR的完整性。因此Aurora会标记每个MTR的最后一条log为Consistency Point LSN(CPL),在恢复数据时只能恢复到VCL之前最大的一个CPL,称为Volume Durable LSN(VDL)。
假设DB目前看见三个CPL分别是900、1000、1100,此时VCL为1007(大于1007的log不完整),则VDL为1000,大于1000的log都会被截断。
log chain
不同的log record会发送给它修改的block所在的PG,因此每个PG/Segment只能看到部分log record。为了避免Segment之间的同步,每个log record会包含有:
- 整个Volume中它的上一个LSN。
- 这个Segment中它的上一个LSN。
- 它修改的block的上一个LSN。
这样Segment根据log chain就可以知道自己当前的log是否完整了。
写入
Aurora的DB在执行写操作时是全异步I/O,在将log record发给对应的Segment后就会将当前请求放到等待队列中继续处理下一个请求。每当有请求执行完,DB会判断是否要提升VDL,之后将等待队列中所有LSN小于等于VDL的请求标记为提交完成。为了避免太多请求等待,DB在分配LSN时会保证LSN与VDL之间的gap不会太大(LSN Allocation Limit,LAL,默认为1000万)。
恢复
可以看到client的commit在超前于VDL时是不返回的,因此Aurora可以在failover时将大于VDL(不完整)的所有log都截断掉而不影响一致性。
Aurora中DB初始化与故障恢复走相同流程:
- DB确认可连接的PG达到read quorum。
- DB收集各Segment的SCL,本地计算得到PGCL、VCL、VDL。
- DB向各个Segment发送truncate,将大于VDL的log删掉,避免故障前的请求飘到Segment上。后续新生成LSN时会将截断这段(VDL+1到VDL+LAL)跳过去。
- 修复那些达不到write quorum的PG(仍然使用gossip协议)。
- 提升所有达到write quorum的PG的epoch,避免旧的DB实例连上来。采用epoch比lease好的地方在于它不需要等待lease过期。
在PG都恢复之后,DB自己可以慢慢做undo,不影响服务。
第二篇paper中称这种复杂的恢复流程是一种tradeoff,用这种复杂度换取了正常流程的简单、低开销:“The time we save in the normal forward processing of commits using local transient state must be paid back by re-establishing consistency upon crash recovery”。
读取
Aurora的DB只需要写redolog,不需要写data page,因此也不需要刷脏页(dirty page),但仍然需要决定如何将脏页从buffer pool中踢掉。Aurora需要保证client永远能看到最新的页。定义页的LSN就是它的最后一笔写的LSN,如果page LSN > VDL,说明此时page要比存储更新,就不能踢掉。只有page LSN <= VDL的页才可以踢掉(第一篇paper这里写反了),后面如果需要读的话再从存储层load上来。
Aurora的读需要固定在某个CPL上以保证read view一致,默认是读请求到达时的VDL。注意DB是有存储层各PG的全部信息的,它可以选择一个足够新的Segment来服务这次读,避免使用read quorum。
DB也会追踪目前所有活跃的读事务(包括只读replica在处理的读事务)在各个PG上的最小的LSN,记为Protection Group Minimum Read Point LSN(PGMRPL),PGMRPL会发送给各个Segment,Segment可以把低于它的log record与过期的data page都清理掉。
与正常的MySQL类似,读出来的页可能比想要的版本更新,需要本地应用undo record。因此本地的undo record也必须在PGMRPL提升之后才能清理掉。
只读实例不能太多,否则主实例的出口流量放大会比较严重,另外落后的只读实例会影响整个DB的GC。
只读实例
Aurora中每个DB最多可以有15个只读实例,它们与主实例共享存储层,理论上可以定期从各个Segment上拉取数据来保持与主实例同步。但为了降低主实例与只读实例的可见延时,主实例在写存储层的同时也会把log流发送给只读实例。注意log流中也包含了VDL的提升与主实例上的事务状态变化,这样只读实例可以正确地维护活跃事务列表。
只读实例会将主实例发过来的log record应用到自己buffer pool中的page上,规则是:
- 如果log record修改的page不在buffer pool中,直接丢掉。
- 只应用那些不大于VDL的log record,这些数据可能在failover后截断掉,不能被client看到。
- 相同MTR的log record要原子应用到page上。
主实例到只读实例的replication是异步的,只会增加主实例的网络流量,不会对延时有明显的影响。如果主实例挂了,会有一个只读实例升级为主实例,此时它只需要走一遍恢复流程重建内存状态。
成员变更
这里指PG的Segment变更。
quorum协议的成员变更通常是比较复杂的,比如I/O要停,变更过程中不能有failover等。Aurora使用了quorum set的概念,将一次成员变更分成至少两次操作,每次都会提升membership epoch,从而解决了上面这两个问题。
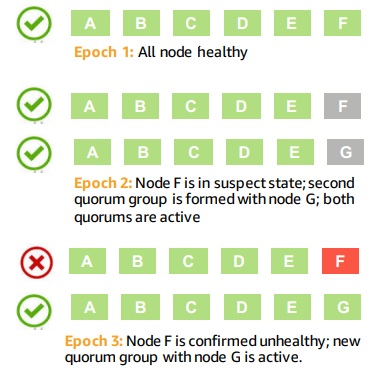
假设我们要将ABCDEF变更为ABCDEG,第一步是将write quorum变为4/6 of ABCDEF AND 4/6 of ABCDEG,read quorum则是3/6 of ABCDEF OR 3/6 of ABCDEG。此时如果F恢复了,我们可以再将成员列表变回ABCDEF。如果F一直没有恢复,当G追上其它成员后,做第二步变更,将成员列表改为ABCDEG。
如果过程中E也挂了,需要替换为H,则write quorum变为4/6 of ABCDEF AND 4/6 of ABCDEG AND 4/6 of ABCDFH AND 4/6 of ABCDGH(不会更复杂了,4/6的quorum只允许同时最多挂2份)。整个过程中I/O是不需要停的。
当整个AZ挂掉时,quorum需要从6/4/3退化为4/3/2,也是通过上面的机制实现的。
降低存储成本
Aurora中每个PG的6个Segment是不对等的,分为3个完整的大Segment(包含log与data)与3个log-only的小Segment。因为log通常远小于data,这样整体存储成本更接近于3份拷贝,而不是6份。
这种设计同时也影响了读写的quorum。write quorum是4/6的任意Segment,或3/3的大Segment,而read quorum则是3/6的任意Segment,且1/3的大Segment(注意read quorum不用于常规读请求)。
修复一个小Segment的过程与前面一样,但修复一个大Segment就有点复杂了,因为它可能是唯一有完整数据的大Segment(注意4/6的quorum中可能有3份是小Segment)。但回顾Aurora的口号:“THE LOG IS THE DATABASE”,只要有足够的log,仍然可以修复这样的大Segment。
可以看到quorum协议有着足够的灵活性,可以用来实现非对等的成员。