TL;DR
Snowflake是一个云原生的数据仓库。它的价值在于:
- 展示了云平台与分布式系统的差别,如何利用好云上的基础设施。
- 如何真正以用户体验为导向去设计一个系统。
- 做系统的startup如何赚钱。
前2条参见最后一小节“Lessons Learnd and Outlook”。
第3条很有价值。(以下一堆马后炮)
之前做系统的startup的商业模式是做开源系统,然后卖license、技术支持。但云时代了,这条路不太好走,前途一眼可见。问题在哪:
- 你的开源系统要有竞争力,这就过滤掉了很多小用户了,他们用开源系统已经可以满足需求了,为什么要花钱?
- 大客户不需要买你的服务,首先小公司的技术能力不一定能解决大公司特有的问题,其次大公司也有足够的人和资源,可以自己解决。
- 最后剩下一些中等客户,他们往往要的是解决方案,而不是某个产品。但“基于开源”这个原则限制住了对应的闭源系统:要么小打小闹,只能解决局部问题而没办法提供好的方案;要么需要大改,甚至还要把周边系统一起改掉,没办法兼容开源生态。
国内做系统的startup很多也有这方面的问题,而且更严重,大客户要资质,小客户不花钱。估值上就能看出来,想达到独角兽要比做业务的公司难得多。
Snowflake选择了基于现成的云平台做第三方云服务商,做附加值。这个思路初看上去不太可行,云平台为什么不抄你的方案?但实际上云平台不是整体,它是由一个个独立的团队组成,互相有着说不清道不明的既合作又竞争的关系。而第三方相当于是每个团队的客户,是可以合作的。而且大公司人虽然多,但不养闲人,分摊到每个方向的人其实很少,尤其是这种要整合资源、探索新模式的工作,更是人嫌狗厌。这就是细分市场、垂直领域、小而精的团队的机会。
可以看到这几年各种startup都开始搞第三方服务了,这是Snowflake的最大的价值:让工程师先富起来。
这种模式国内的公司不太好学,因为国内的云平台通常没那么友善,有着足够多的焦虑的工程师,会抢走任何赚钱不赚钱的业务。那么要出海吗?问题在于出海的话你的优势在哪,国外的客户为什么要买一个中国公司的服务?甚至国内出海的客户也不见得更倾向中国公司提供的服务。
然而2020告诉我们的就是,一切都会变的。
Introduction
云时代来临了,但传统的数仓方案还是在云时代之前的,只能跑在小型的、静态的、指定机器的集群上,而没办法真正利用云设施。
除了平台在改变,数据也在改变。过去数仓要处理的数据都来自相同组织内部,它们的结构、容量、产生速度都是可以预期和规划的。但云数仓的数据来自不容易控制的外部,而且经常是没有schema的半结构化数据。面对这些数据时,传统数仓力不从心,它们严重依赖ETL pipeline和根据已知的数据特点来手动调优。
后续产生的Hadoop、Spark、Stinger Initiative等方案仍然无法满足云时代对数仓的需求,尤其是它们都需要花费大量人力做运维和调优。
Snowflake与这些方案的区别在于它是真正利用云设施的经济、弹性、服务化等优点的数仓产品。它的关键特性如下:
- 纯正的SaaS体验。用户不需要关心机器、运维、调优、扩容,只要数据上传到Snowflake,立即就可以开始分析。
- 支持SQL和ACID的事务。
- 支持JSON和Avro之类的半结构化数据,可以遍历、摊平、嵌套,利益于自动的schema发现和列存格式,操作半结构化数据的效率与结构化数据一样高。
- 弹性的存储与计算资源。
- 高可用。
- 数据可靠性。
- 费用合理,用户只需要为存储(压缩后)和使用的计算资源付费。
- 安全性,所有数据和网络都是端到端加密的,用户还可以基于role来做细粒度访问控制(SQL级别)。
这篇文章中Snowflake使用的是AWS的资源,目前它也已经支持了Azure和GCP。
Storage Versus Compute
shared-nothing架构在高性能数仓领域占据了主导地位,它的优点是规模与硬件便宜。这种设计很适合星型query,在join一个小的维表(broadcast)和一个大的事实表(partition)时只需要很小的带宽。
但这种shard-nothing架构有个严重缺陷:计算与存储耦合。以下场景会有问题:
- 异构负载。一种系统配置很难同时满足批量导入(高I/O带宽,低运算)和复杂query处理(低I/O带宽,高运算),最终可能两种都不高效。
- 扩缩容时会有大量数据需要搬迁,过程中现存节点也会受影响。
- 在线升级。想要完全不影响服务,理论上可以,但实际很难,尤其是各种资源耦合在一起,又有着同质化假设时。
云环境下这些场景都会出现。
因此Snowflake选择了计算存储分离的架构,其中计算使用了AWS EC2,存储则使用AWS S3。每台机器上还会在本地盘上缓存数据。如果cache是热的,这种架构的性能可以达到甚至超过shared-nothing系统。
Architecture
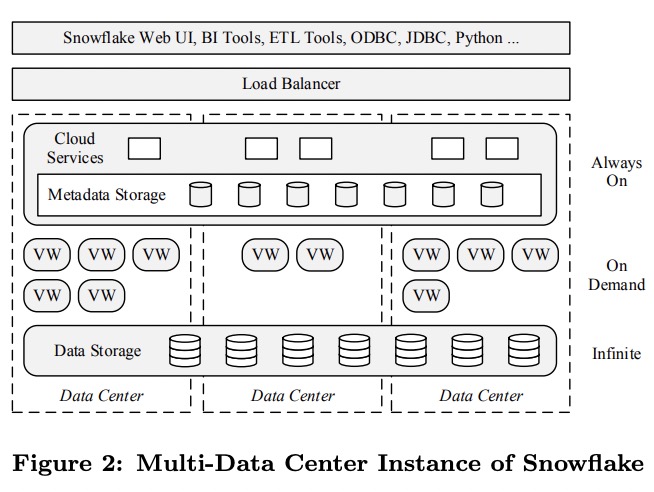
Snowflake的目标是成为企业级的服务,除了易用性和相互操作性之外,还需要有高可用性。整个Snowflake分为三层:
- 存储层是AWS的S3.
- 虚拟数仓层(virtual warehouse)负责在vm集群上执行query。
- 云服务层,包括了管理VW、query、事务的服务,以及管理元数据的服务。

Data Storage
Snowflake选用AWS的原因是:AWS是最成熟的云平台;AWS有着最多的潜在客户。
在S3与自建HDFS的选择中,Snowflake发现S3虽然性能不太稳定,但它的易用性、高可用、强数据可靠性都是很难被替代的。因此Snowflake转而将精力花在了VW层的本地cache和弹性处理倾斜的技术上了。
S3有以下特点:
- 单次访问延时高,CPU消耗大,尤其是使用HTTPS时;
- 文件只能覆盖写,不能追加;
- GET支持只读部分文件;
这些特点严重影响了Snowflake的文件格式和并发控制策略的设计。表被水平分为若干个大的、不可变的文件,每个文件内部使用PAX风格的结构,分为若干个row group,row group内部各列单独存为block。每个文件有一个header,包含了各列的偏移。query只需要读走header和想要的列就可以了。
S3不止用来保存表文件,还会在本地盘用满时保存query算子产生的临时文件。这种设计还增加了一种client间的互动方式,并且简化了query处理,因为不再需要像传统数据库那样在server端维护query的游标了。
元数据则保存在一个可伸缩的事务性的kv store中,属于云服务层的一部分。
Virtual Warehouses
VW层由若干个EC2集群组成,每个EC2集群称为一个VW,但Snowflake没有直接暴露EC2的信息,而是用抽象的“T-Shirt大小”来代表每个节点的规格,从XS到XXL。这种抽象允许Snowflake独立演进服务和定价,而不会与具体的云服务绑定。
Elasticity and Isolation
VW是纯粹的计算层,创建或销毁一个VW对整个DB状态不会有任何影响。用户甚至可以在没有query时停掉所有VW。
一个query只会在一个VW上执行,VW间不共享节点,从而保证了query间的强隔离性(但VW间共享节点是Snowflake的未来目标)。
VW在处理query时会在每个参与的节点上创建一个新worker进程,这个进程会在query结束后就停止。因为表文件都是不可变的,worker进程不会破坏DB状态,挂掉后直接重试即可。目前Snowflake还没有实现部分重试,而是有节点挂掉则整个query重试。
每个用户可能同时有多个VW在运行,每个VW可能同时在处理多个query,这些VW可以看到用户的所有表,而不需要物理拷贝数据。
数据共享意味着用户可以共享/集成自己的所有数据,而计算私有则意味着不同负载和组织之间不会有相互影响,这也是数据集市的意义之一。对于Snowflake的用户来说为不同目的的query准备多个VW是很正常的,偶尔还会按需创建VW来执行批量导入数据之类的任务。
Snowflake的弹性还使得同样的价格下用户可以享受到好很多的性能。比如同样的导数据任务,4个节点的系统可能要15小时,而32个节点的系统只要2小时,两者的价格差不多,但后者的体验好很多。弹性VW就是Snowflake最大的优势和差异点之一。
Local Caching and File Stealing
每个节点的本地盘会作为表文件的cache,保存访问过的S3对象,包含header和访问过的列,使用LRU策略淘汰数据。
cache的生命期与节点相同,被这个节点上的所有进程和所有query共享。
为了提升命中率,减少不必要的cache,query优化器会使用一致性哈希,根据表文件名将文件分配给各个节点,后续需要读这些文件的query会被优先发给对应节点。但Snowflake的一致性哈希是惰性的,当有节点变化时数据不会立即洗牌,而是继续依靠LRU淘汰数据。(能这么做是因为它是cache,不涉及正确性)
此外倾斜也是一个重要课题,Snowflake的做法是当一个worker进程A处理完所有文件后,它会从其它进程那里偷一个文件过来,目标进程B如果此时有多个文件待处理,就会同意这次请求,之后进程A会直接从S3上下载这个文件,而不是从进程B那里,避免使B更慢。
Execution Engine
Snowflake自己实现了一个全新的列存、向量化、基于push的执行引擎:
- 列存在分析场景的优势是更高效地使用CPU cache、SIMD,有更多机会使用(轻量)压缩。
- Snowflake不会物化中间结果,而是流水线处理,每次批量处理列存格式的数千行数据,节省了I/O,还显著提升了cache效率。
- 上游算子会将它的结果直接推给下游,而不是等着下游来拉(传统的Volcano模型)。这种方式能提升cache效率(从密集循环中移除了控制流逻辑),也允许更高效地处理DAG形状的plan。
同时Snowflake中也没有传统引擎会有的一些开销,如query过程面对的是一组固定的不可变文件,因此不需要事务管理,也不需要buffer pool。大多数query都要处理大量数据,过于限制使用内存没有什么好处,相反Snowflake允许所有主要算子(join/group by/sort)反复将多余数据写到磁盘上。
Cloud Services
与VW层不同,云服务层是多租户的,负责所有VW的元数据与控制。其中的每个服务都使用多副本来实现高可用与伸缩性。
Query Management and Optimization
所有用户发起的query都会先经过云服务层,在这里做完早期处理:解析、对象解析、访问控制、plan优化。
Snowflake的query优化器基于典型的Cascades风格,采用了自上而下、基于cost的优化。所有优化需要的统计信息都是在数据加载和更新时维护的。因为Snowflake不支持索引,优化器要搜索的空间比其它系统要小,再加上很多决策会被推迟到运行期(如join的数据分布类型),搜索空间就更小了。这种设计减少了优化器生成错误决策的机会,增加了稳健性,只是损失了一点峰值性能。
优化完成后plan会发给所有参与的节点。在query执行过程中,云服务层会持续追踪query的状态,一方面收集性能指标,一方面检测节点错误。
Concurrency Control
并发控制完全由云服务层来实现。Snowflake提供了snapshot isolation的ACID事务。因为S3的文件只能整个重写,Snowflake每笔写都会生成新的文件(Snowflake没有undo/redo log),并通过元数据的MVCC来实现数据本身的MVCC。
Pruning
传统的DBMS是通过索引来跳过不需要的数据的,但在Snowflake这样的系统中,索引会带来以下问题:
- 索引会带来大量随机读,与Snowflake的远端存储和压缩格式有冲突。
- 维护索引显著增加了存储空间和数据加载时间。
- 用户需要显式创建索引,这与Snowflake的纯粹服务的宗旨不符——增加了用户的使用难度。
Snowflake使用了另一种近期很流行的方案,使用min/max剪枝。这种方案很好地契合了Snowflake的设计原则:不依赖用户输入;伸缩性好;易于维护。这种方案在顺序大块数据时效果很好,对数据载入、query优化、query执行的影响也非常小。
Snowflake对半结构化的列也会生成min/max。
除了静态剪枝,Snowflake还会运行期动态剪枝。例如在hash join时,Snowflake会在构建端统计join key的分布,再传到探测端用来过滤数据,甚至有机会跳过整个文件。
Feature Highlights
Pure Software-as-a-Service Experience
用户可以通过web页面访问和管理Snowflake。
Continuous Availability
Fault Resilience
S3本身是多AZ的,保证了99.99%的可用性和99.999999999%(9个9)的可靠性。Snowflake的元数据本身也是多副本、多AZ的。云服务层的其它stateless的服务也是跨AZ的,保证了一个节点到一个zone宕机都不会造成严重后果。
相对地,出于性能原因,VW不是跨AZ的。如果query过程中有节点出错,整个query会无感知地重试。如果节点没有马上恢复,Snowflake还有一个备用节点池。
如果整个zone宕机,用户需要在别的zone再创建一个VW。
Online Upgrade
Snowflake被设计为允许系统中同时存在多种版本的服务,这主要得益于所有服务都相当于stateless的,且所有状态都维护在一个事务性的KV store中,通过一个感知元数据版本和schema演化的映射层来访问。每次元数据schema版本变化都会保证向后兼容。
在软件升级时,Snowflake会保留旧服务的同时部署新服务,用户请求按账号迁移到新服务上,但已经进行中的query会在旧服务上完成。一旦所有用户都迁移完了,旧服务就会停止下线。
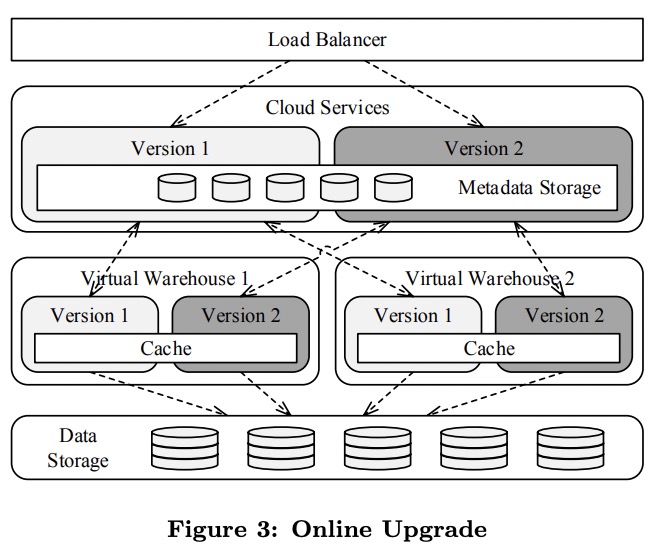
所有版本的云服务层都会共享相同的元数据。更进一步,不同版本的VW可以共享相同的节点和上面的cache,这样升级后cache仍然保持有效,不会有任何性能损失。
写这篇文章时Snowflake每周会升级一次所有服务。
Semi-Structured and Schema-Less Data
Snowflake支持三种半结构化数据:VARIANT、ARRAY、OBJECT。VARIANT可以是任何原生SQL类型(DATE、VARCHAR等),OBJECT类似于JavaScript中的object。这三种类型本质都是VARIANT,有着相同的内部形式:自描述的紧凑的二进制,支持快速kv查询、高效的类型测试、比较、hash。
VARIANT允许用户使用一种ETL(Extract-Load-Transform)风格来处理数据,而不是传统的ETL(Extract-Transform-Load)(个人理解是可以保留原始格式,为未来的使用保留更多可能性,类似于数据湖的用法)。
另外Snowflake可以在任何SQL语句中做转换,而不需要单独的转换步骤。
Post-relational Operations
Snowflake能高效处理OBJECT和ARRAY的子对象提取,因为子对象是单独存放的,父对象中只是一个指针,因此提取过程中不需要拷贝。
Columnar Storage and Processing
Snowflake在收集统计信息之后,如果发现VARIANT中有某条路径经常被访问,这一列就会被单独使用类似原生类型的压缩列存格式保存,甚至会生成物化的聚合值用来剪枝。这种优化是在各个文件中单独做的,每个文件会有bloom filter来判断某个路径是否单独保存,这样只有做了这个优化的文件才会下推算子,而其它文件则回退到未优化的处理路径上。
Optimistic Conversion
半结构化数据的一个问题是没有类型信息,需要在读的时候做类型转换,对性能有影响,也缺少剪枝需要的元数据。
Snowflake可以在写的时候自动推断类型信息,做写时类型转换,避免上述问题。原始列也会被一同保留下来,这样在读的时候如果发现自动推断的类型不对,还可以回退。
Performance
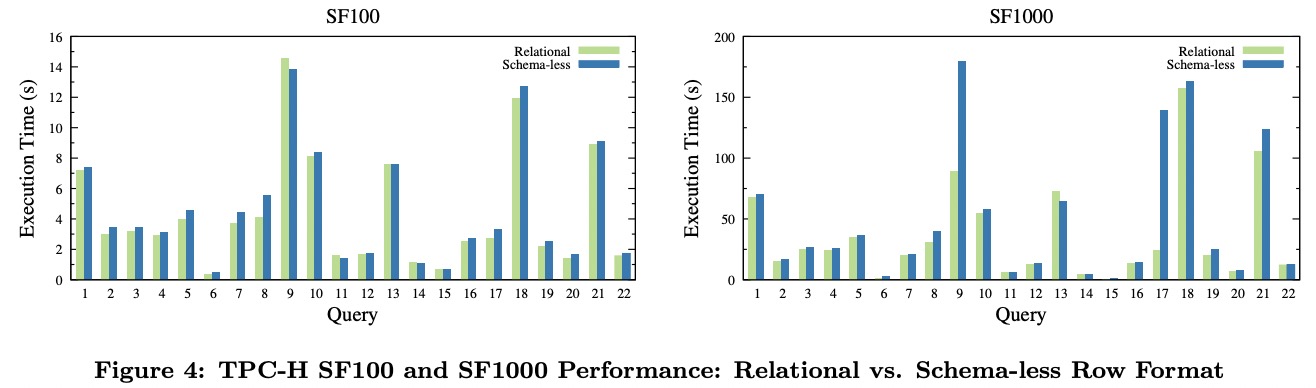
图中可以看出schema-less的存储和处理只有10%的额外开销(除了Q9和Q17因为bug)。
Time Travel and Cloning
文件不可变,加上元数据的MVCC,使得Snowflake可以实现时间漫游:
1 | SELECT * FROM my_table AT(TIMESTAMP => |
可以在同一个query中访问同一张表的不同版本:
1 | SELECT new.key, new.value, old.value FROM my_table new |
还可以使用UNDROP命令恢复表、schema、甚至整个DB:
1 | DROP DATABASE important_db; -- whoops! |
Snowflake还支持高效的clone操作,两张表共享底下的文件,而不需要物理拷贝。clone也可以用来做snapshot:
1 | CREATE DATABASE recovered_db CLONE important_db BEFORE( |
Security
Snowflake中,数据会在两个地方加密,一个是client发送前,一个是写入本地盘或S3前。
Key Hierarchy

Snowflake中有4层key:root key、account key、table key、file key。每层key的保护范围都会包括下面的child key。
Key Life Cycle
每个key的生命期有四阶段:
- 生效前的创建阶段。
- 生效阶段,用来加解密数据。
- 失效阶段,key不再使用。
- 销毁阶段。
一个key只有在没有文件使用它之后才会从阶段2变到阶段3。
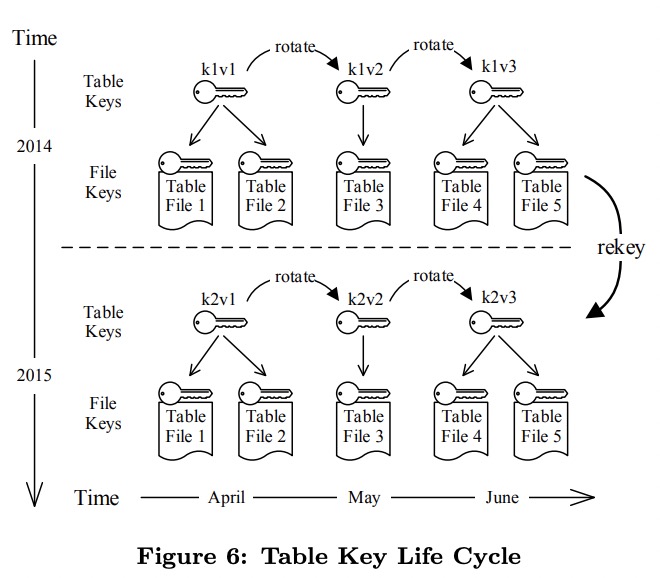
Snowflake使用了key rotation来限制加密阶段key的使用,rekeying来限制解密阶段key的使用。
key rotation会定期(如一个月)创建新的key,之后旧的key只用来解密,不用来加密。
rekeying是定期用新key重新加密旧数据的过程。当一个key已经被淘汰一段时间(如一年)之后,仍然用它来解密的文件就需要重新加密。
同样的操作也发生在root key与account key、account key与table key之间,它们的rekeying只需要重新加密child key,不需要重新加密文件。
table key与file key的关系与这些都不同。file key不是直接由table key管理的,而是用table key与file name组合来的,因此一旦table key变化了,所有file key都跟着变化,文件也都需要重新加密。这种开销换来的是不再创建、管理、销毁file key了,否则Snowflake的文件数量是十亿量级,需要管理的file key将达到GB级别。
Related Work
vs Redshift:Redshift使用了经典的shared-nothing架构,导致了因计算资源而扩缩容时需要搬数据。而Snowflake的计算完全独立于存储。另外Snowflake不需要用户来调优、整理数据、手动收集统计信息、淘汰失效数据。尽管Redshift也可以将JSON等半结构化数据导入为VARCHAR,Snowflake可以对半结构化数据做优化和列存。
vs BigQuery:BigQuery的SQL方言与ANSI SQL有一些本质区别。另外BigQuery只支持追加写,必须要有schema。相比之下Snowflake支持完整的DML与ACID的事务,且不需要为半结构化数据准备schema。
vs Azure SQL DW:尽管Azure SQL DW可以以data warehouse unit为单位扩容计算资源,但并发度是受限的。Snowflake则没有这种限制。且Azure SQL DW没有内建的对半结构化数据的支持。
Lessons Learnd and Outlook
2012年,在Snowflake刚创建时,整个数据库世界都在关注SQL on Hadoop,短短时间出现了超过一打的新系统。在那个时候,决定要走一条不同的路,构建一个云上的“经典”数据仓库,看起来是个逆潮流的冒险决定。3年的开发之后,我们确信这个决定是对的。Hadoop没有替代关系型数据库,而是成为了后者的补充。人们仍然需要一个关系型数据库,但要更高效、更灵活、更适合云平台。
Snowflake满足了我们的期望:一个构建在云上的系统能为它的用户和作者提供什么。多集群加上共享存储架构的弹性改变了用户对待数据处理任务的方式。SaaS模型不仅简化了用户尝试和适应系统的过程,也戏剧性地帮助了我们开发和测试。生产环境单版本和在线升级允许我们比传统的开发模型更快地发布新版本、做改进、修复问题。
我们曾经希望半结构化扩展能证明是有用的,但仍然震惊于它被接受的速度。我们发现了一个非常流行的模型,那就是很多用户会用Hadoop做两件事:保存JSON数据、将JSON转换为能载入关系型数据库的格式。通过提供能保存和处理半结构化数据的系统——并提供强大的SQL支持——我们发现Snowflake不仅可以取代传统的数据库,还可以取代Hadoop。
当然过程不会一帆风顺。尽管整个团队加起来有超过100年的数据库开发经验,我们仍然犯了一些可以避免的错误,包括一些关系操作的早期实现过度简化了,没有早点在引擎中支持所有数据类型,对资源管理的关注不够早,推迟了日期与时间函数上的工作等。同样地,我们在避免调优参数上的持续关注也带来了一系统工程上的挑战,最终变成了许多令人激动的技术方案。作为结果,今天的Snowflake只有一个调优参数:用户想要(以及愿意花钱买)多少性能。
尽管Snowflake的性能已经很有竞争力了(尤其是考虑到它还不需要调优),我们仍然有很多已知的优化清官没有时间做。但有些令人意外的是,Snowflake的核心性能几乎没有给用户带来过困扰。原因是通过VW提供的弹性计算可以提供用户偶尔需要的性能提升。这允许我们将注意力转移到系统的其它开发上。
我们的最大的技术挑战与SasS和多租户有关。构建一个可以支持数百个用户并发访问的元数据层,这是很有挑战、很复杂的任务。这是永无止境的战斗:处理多种类型的宕机、网络问题,并提供服务。安全一直是一个很大的主题:保护系统和用户数据免于外部攻击。想要维护一个活跃的、有数百个节点、每天处理数百万个query的系统,且令人满意,需要有能将开发、运维、支持高度整合起来的方案。
Snowflake的用户一直在抛出越来越大、越来越复杂的问题,也在影响着系统的演进。我们目前正在致力于提供额外的元数据架构和数据重组任务——尽量减少用户交互——来提升数据访问性能。我们持续改进和扩展着标准SQL和半结构化数据的核心query处理功能。我们计划进一步改进倾斜处理和负载均衡策略,随着用户workload的规模增大,这两方面愈发重要。我们也在努力简化用户的workload管理,使系统更有弹性;与外部系统集成,包括高频的数据加载。
Snowflake未来最大的挑战是向完全自服务模型的转变,到那时候不需要我们介入,用户自己就可以注册与体验系统。它会带来很多安全、性能、支持上的挑战。我们很期待这一天。