TL;DR
TiDB是一个HTAP系统,目标是同时服务TP和AP服务,且能保证隔离性和数据新鲜度。它的架构受到了Spanner和F1的影响:计算层类似于F1,无状态;存储层类似于Spanner,支持分布式事务。
它的存储层分为了行存的TiKV和列存的TiFlash,其中TiKV各个replica之间通过Raft保持一致,TiFlash则作为Raft的learner保证看到最新的数据。相比Kudu,TiDB物理上分离了TP和AP,隔离性更好;相比F1-Lightning的基于CDC的replay,TiDB的新鲜度更好。
一些看法:
- TiKV底下使用了RocksDB,但LSM的compaction会导致性能不稳定,在高并发的TP场景可能会有问题,如何解决?
- TiFlash是绑在TiKV上的:
- 数据一定要先进TiKV再进TiFlash,对于没有强事务需求的场景而言有些浪费,是否能提供更低开销的ingestion?
- 列存和行存的key order是一样的,是否能有列存格式的索引?
- 与Kudu等系统类似,TiKV的Raft与多副本是绑定的,对支持erasure coding有阻碍,对上云也有阻碍(使用云存储)。
Introduction
(前面阐述HTAP的意义)HTAP除了像NewSQL系统一样要实现可伸缩、高可用、事务一致性,还有两个重要属性:新鲜度(freshness)和隔离性(isolation)。
新鲜度指OLAP能看到多新的数据。基于ETL的HTAP方案保证不了实时新鲜度,甚至经常要延迟几小时以上。将ETL换成流计算能极大改善新鲜度,但这种方案涉及多个模块(OLTP、流计算、OLAP),维护代价高。
隔离性指OLTP和OLAP的请求互不影响。一些内存数据库(如HyPer)允许一个server内的AP请求访问到最新的TP数据,但这就存在相互影响,没办法让TP和AP吞吐都达到最高(实际上有相当明显的影响)。
让TP和AP使用不同的硬件资源(如不同server)能解决隔离问题,但问题在于如何保证用于AP的replica有着和用于TP的replica一样新的数据。注意到保证replica数据一致与高可用一样,都需要用到共识协议,如Paxos和Raft。
TiDB的idea就来自这里,它使用了Raft来同步replica,其中AP replica身份为learner,只接受数据,不参与投票,且在收到数据后将行存格式转为列存格式。通过Raft保证了AP replica能看到最新的数据;通过引入learner,保证了AP replica对TP replica只有最小的影响(每多一个AP replica,多一次RPC的吞吐,但基本不增加延时)。
Raft-based HTAP
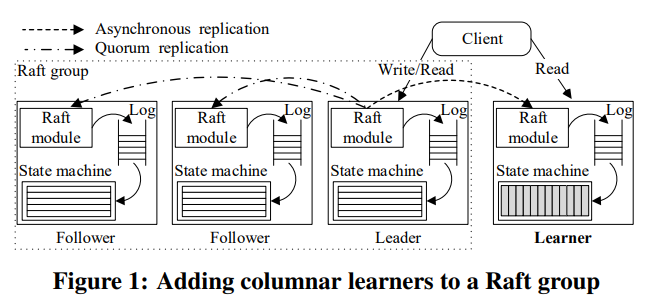
从high level来看,数据保存在若干个Raft group中,其中每个leader和follower的数据是行存的,用来服务TP请求,learner数据是列存的,用来服务AP请求。query优化器会考虑两种引擎来生成query plan。
以下是TiDB解决的几个工程问题:
- 如何构建一个可伸缩的支持高并发读写的Raft存储系统?如果数据量超过了Raft各节点的可用空间,需要有办法将数据分片分散到各个server上。另外在基本的Raft协议中,请求是串行执行的,在回复client前必须要得到多数Raft节点的确认。这个过程引入了网络和磁盘操作,会导致leader成为系统的瓶颈。
- 如何以低延时将数据同步给leaner?正在执行的事务可能产生很大的log,这些log需要快速在learner上重放、持久化。将log转换到列存的过程中可能因schema不匹配而出错,导致log同步延迟。
- 如何同时高效处理TP和AP query且保证性能?大的TP query需要读写位于多个server上的大量数据,而AP query也会消耗大量资源,不应该影响到TP请求。需要能综合考虑行存和列存store来生成最优化的plan。
Architecture

TiDB支持MySQL协议,分为三层:分布式存储层、Placement Driver(PD)、计算层。
分布式存储层有两种store:row store(TiKV)和columnar store(TiFlash)。TiKV中每个key-value pair对应一行数据,其中key使用tableID和rowID编码,value则是这行真正的数据:
1 | Key: {table{tableID}_record{rowID}} |
数据按key range分为若干个region,每个region对应一个Raft group。
PD负责管理region,同时也是timestamp oracle,生成全局单调增的timestamp。PD可以有多个节点,本身是stateless的,每个节点在启动时会从其它节点和TiKV处收集信息。
计算层也是stateless的,可以弹性伸缩。它有一个基于cost的优化器,和一个分布式query执行器。它使用了Percolator风格的2PC以支持分布式事务。
此外TiDB还集成了Spark,从而允许将TiDB的数据与Spark生态连接起来。
Multi-Raft Storage
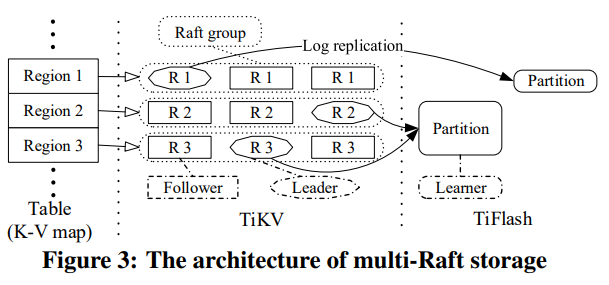
TiKV的多个region可能会对应TiFlash的一个partition,从而提高扫描的效率。
Row-based Storage (TiKV)
每个TiKV server会服务若干个region,每个region的状态机使用了RocksDB。默认每个region最大为96MB。
基本的Raft协议执行过程如下:
- leader接收到请求。
- leader将数据追加到log中。
- leader将新的log entry发给follower,后者将数据追加到log中。
- leader等待多数follower确认后commit,并应用到本地状态机中。
- leader回复client。
这个过程中数据在不同节点间的通信是串行的,还可能引入额外的I/O开销(网络和磁盘),存在性能瓶颈。
Optimization between Leaders and Followers
上面的第2步和第3步是相互独立的,leader在本地追加log的同时就可以将数据发送给follower了,如果leader自己追加失败了,但follower已经达到多数了,这次请求仍然可以commit(leader自己重试,如果重试成功前发生leader切换,则之前写成功的某个follower会成为新leader,数据本身不会丢)。
第3步中leader可以buffer未commit的log entry,在前一个log entry发给follower之后,不需要等待多数follower回应就可以开始处理下个log entry。如果其中某个log entry出错,leader可以回调log index,并重新发送log entry(与pangu1的pipeline类似)。
第4步中leader应用log entry和回复response可以同时进行,到了这步请求的状态已经确定了。
新的Raft执行过程如下:
- leader接收到请求。
- leader将log entry发送给follower并并行本地追加。
- leader继续接收请求,并重复第2步。
- leader收到多数回应后commit log entry(应该需要前缀都确认),并在另一个线程中应用。
- leader回复client。
Accelerating Read Requests from Clients
TiKV的leader需要支持可线性化的读语义,即当时间t一个请求从leader处读到了某个值,所有晚于t的请求从leader处不能再读到更旧的值。基本的Raft协议需要leader写一个新的log entry以确保自己仍然是leader,从而确认自己的数据是最新的。但这就引入了一次I/O,性能上无法接受。
TiKV实现了两种Raft论文中的优化。
优化一称为read index。当leader收到一个读请求时,它用自己的commit index作为read index,然后发送RPC给follower以确认自己仍然是leader,之后它就可以在read index被应用到本地状态机之后返回对应的值。这种优化节省了磁盘I/O,但仍然有网络开销。
优化二称为lease read,即leader和follower约定一个lease长度,follower保证在lease未过期前不会发起选举,这样leader在lease期间可以直接回复读请求,无需任何网络或磁盘I/O。这种优化依赖于各个节点的时钟没有太大的偏差(但failover时间会变长)。
follower也可以服务读请求。当它收到读请求时,它会请求leader获取当前最新的read index(leader的commit index),然后等到本地应用的index大于等于read index后返回。
Managing Massive Regions
大量的region会带来负载不均衡的问题(磁盘使用和访问),PD会从心跳中收集各个TiKV server的信息来移动region的replica。
另一个问题是Raft group的心跳开销。一个没有请求的Raft group可以省略掉心跳,另外根据负载情况,不同Raft group可以有不同的心跳频率。
Dynamic Region Split and Merge
TiKV支持将一个region分裂为多个region,其中key range最大的新region会继承旧region的Raft group,而其它新region则使用新的Raft group。整个分裂过程:
- PD向region的leader发送split。
- leader将split转化为一个log entry并发送给所有follower。
- 一旦多数确认,leader会commit这个log entry并应用到各个节点上。应用过程包括了更新旧region的key range和epoch,创建新region。整个应用过程是原子且持久化的。
- 每个新region的replica开始工作,组成新的Raft group。leader将split结果回复给PD,整个过程结束。
merge操作与split不同:PD将两个region的replica两两移动到相同server上,开始本地merge。本地merge分为两步:先停掉一个region的服务,再将它与另一个合并。merge与split的不同点在于它不能复用Raft的log机制。
Column-based Storage (TiFlash)
用户可以用以下SQL语句设置列存格式的replica:
1 | ALTER TABLE x SET TiFLASH REPLICA n; |
TiFlash中每张表分为若干个partition,每个partition对应若干个TiKV的region。
TiFlash的初始化过程分为两阶段:阶段一leader会把自己的一个snapshot发给TiFlash的replica;阶段二TiFlash的replica开始接收增量数据。
Log Replayer
learner在收到log之后会以FIFO方式将行存的数据重放为列存数据,整个过程分为三步:
- compaction:事务log有三种状态:prewritten/commited/rollbacked。其中rollbacked的log不需要重放,因此第一步是基于rollback的log来删掉prewritten中的无效log,并将有效的log写到buffer中。
- 解码:buffer中的log被解码为行格式,去掉事务相关的无用信息,写到row buffer中。
- 转换:row buffer的大小达到阈值,或时间达到阈值后,整个row buffer中的行都会被转为列存格式,并写到本地的数据池中。转换会使用本地cache的schema,schema会定期与TiKV同步。
(如何保证rollback对应的prewritten log一定在buffer中呢?)

转换生成的列存数据会写到DeltaTree中。
Schema Synchronization
每张表最新的schema保存在TiKV里,每个TiFlash的节点会在本地缓存一份schema。当转换数据时,可能遇到schema不匹配,需要重新请求一份schema并重新转换数据。为了平衡schema同步的开销与schema不匹配的开销,TiFlash使用了两阶段的策略:
- 定期同步schema。
- 在不匹配时同步schema。
Columnar Delta Tree
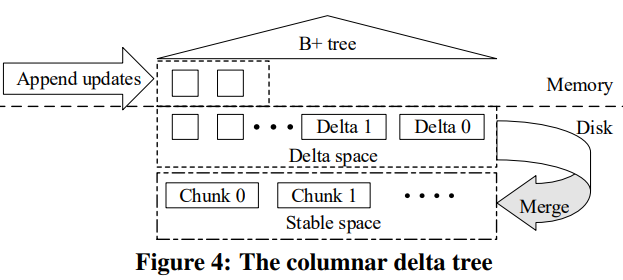
TiFlash的数据分为两部分,base数据是列存的,按key-range分为若干个chunk。列存格式类似于Parquet,区别在于它的row group的meta是单独保存为一个文件,另外压缩格式上目前只支持LZ4。
delta数据则是按写入顺序保存的(用作WAL),也会持久化到磁盘上和compaction。delta数据之上有一个B+树索引用来加速查找(compaction时如何更新索引?)。
当读最新数据时要合并所有delta和对应的base数据,读放大系数很高,因此要定期将delta和base合并到一起。
整个DeltaTree与LSM的性能对比:
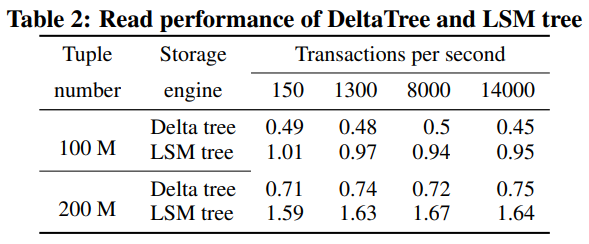
DeltaTree的用时只有LSM(Tiered Compaction)的一半,主要归功于它的读放大会比较小(相当于只有L0和L1),缺点是写放大比较大,但可以接受。
HTAP Engines
在TiKV和TiFlash之上是计算层TiDB,它支持基于rule和cost的优化器、index、计算下推,使用Percolator风格的2PC来实现分布式事务,还实现了TiSpark作为Spark的connector。
Transactional Processing
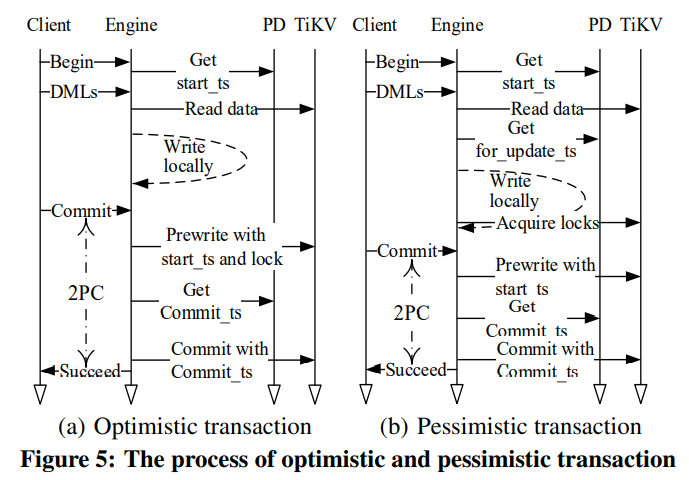
TiDB同时支持乐观锁和悲观锁,其中乐观锁参考了Percolator。
TiDB支持snapshot-isolation(SI)和repeatable-read(RR)两种语义。悲观锁使用RR语义,在加锁时会申请一个for_update_ts的时间戳,加锁失败可以只重试加锁,而不用回滚重试整个事务,且用for_update_ts来读数据。用户也可以指定悲观事务中使用read-committed(RC)语义,这样能减少冲突,但隔离性会下降。
PD生成时间戳的方式类似于HLC,各个节点会批量申请时间戳,目前单机房内不是瓶颈(但geo的话延时会太高)。
Analytical Processing
Query Optimization in SQL Engine
TiDB的优化过程分为两阶段:先用RBO生成逻辑plan,再用CBO生成物理plan。
TiDB支持异步构建和移除索引。索引也保存在TiKV中。有唯一key的index编码为:
1 | Key: {table{tableID}_index{indexID}_indexedColValue} |
没有唯一key的index编码为:
1 | Key: {table{tableID}_index{indexID}_indexedColValue_rowID} |
在生成物理plan时,TiDB会使用skyline pruning算法裁剪掉不用需要的index。如果有多个index分别匹配不同的条件,TiDB会合并这些部分结果。
执行时存储层通过coprocessor来执行某个叶子子树。
TiSpark
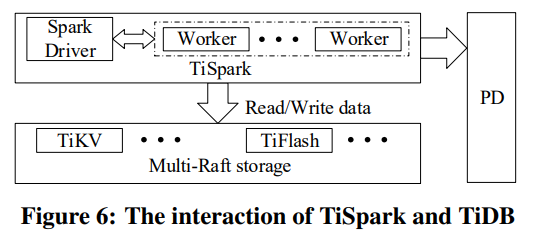
TiSpark相比于普通的connector有两方面区别:
- 可以同时读取多个region。
- 可以并发读取index。
Isolation and Coordination
TiDB中有三种读取数据的路径:扫描TiKV、扫描索引、扫描TiFlash。这三种路径有着不同的开销和key order。TiKV和TiFlash都是按primary key排序,索引则可以有多种排序。三种路径的开销如下:

其中Stuple/col/index代表平均大小,Ntuple/reg代表记录数或region数。fscan代表扫描的I/O开销,fseek代表seek的I/O开销。
考虑select T.*, S.a from T join S on T.b=S.b where T.a between 1 and 100,其中T和S在a列有索引,则优化器会选择使用T的索引和S的列存。