原文:Dremel: a decade of interactive SQL analysis at web scale
TL;DR
这篇文章主要讲Dremel的核心思想和架构原则(参考2010年的paper),包括这些年Dremel的演进(作为BigQuery的后端),以及这些思想在同领域的其它系统中的异同。
在The Seattle Report on Database Research中提到了当前AP系统的若干发展趋势,其中本文重点提到的有:
- SQL:大家都开始用SQL作为查询接口了。
- 计算存储分离。
- 原地分析:数据湖(Data Lake)越来越流行了,同一份数据可以由不同的计算引擎使用,结果再存回数据湖中,而不需要为了不同引擎反复转换数据。
- Serverless计算:提供on-demand方式,用时分配资源,按使用量计费,而不是传统的预留资源。
- 列存:Dremel对嵌套结构的列存处理方式启发了许多后来者。
拥抱SQL
无论是Google还是开源世界都在重复着一个循环:放弃SQL——重新拥抱SQL。
Google在00年代认为SQL无法支持大规模(SQL doesn’t scale),因此MapReduce、BigTable等系统完全不支持SQL。但SQL这种交互方式远比手写job方便,后来大家都开始试探着把SQL加回来。
Dremel是最早回归SQL的Google系统之一。它的一个重要创新是将Protocol Buffer作为一等公民,支持query嵌套或重复字段。这种创新后来被GoogleSQL(开源为ZetaSQL)所继承。
传统的SQL schema设计是要把层级结构拆成多张表,query时再join,有着巨大的运行期开销。在Dremel之前Google的数据集经常要把嵌套记录拍平,产生了很大的转换开销。有了对嵌套和重复字段的支持后就可以避免这两类开销了。
现在GoogleSQL已经成为了Google产品的公共接口,如Dremel、F1、Spanner、PowerDrill、Procella、Tenzing等都支持GoogleSQL,这样它们可以共享以下特性:
- 统一的遵从ANSI SQL标准的方言。
- 统一的parser、编译前端、关系代数解析器。
- 共享的SQL函数库。
- 简单的参考实现,用于展示正确的行为。
- 共享的测试库,包括服从性测试(compliance test)以保证不同实现都遵从规定的行为。
- 其它基础工具,如随机query生成器和SQL格式化工具。
开源世界也是这样的,Hadoop之后大家都在尝试在Hadoop上增加对SQL的支持。到今天主流大数据系统大多支持了SQL,比如HiveSQL、SparkSQL、PrestoSQL等。
重新拥抱SQL并不意味着这些产品在走回头路。“SQL doesn’t scale”的论据是前分布式时代的数据库(包括当时的并行数据库)与数据仓库的架构不适应web规模的数据量,要么依赖中心节点,要么不够容错。而新产品是在从架构层面解决了规模上的问题之后才又加回了对SQL的支持,它们的上层API长得像不代表底下实现也类似。
但现在的一个问题是大家的SQL仍然不统一:ANSI SQL标准在实践上有很多局限性,如缺少很多关键功能,每个系统都要自己加一些扩展。但这使得SQL语法变得碎片化了,学习成本高,还有“lock-in”的风险。
解耦
存储解耦
Dremel一开始完全是shard-nothing(每台机器用本地磁盘管理数据),计算存储耦合,可能都没有考虑容错性。
2009年计算层迁移到Borg上,开始考虑容错,存储切换到了本地多副本上。但此时计算存储耦合带来了很多问题:所有新特性都要考虑replication;不搬数据就没办法更改集群大小、存储扩容同时也意味着CPU扩容、数据只能被Dremel访问等。
之后Dremel将存储迁移到GFS上,一开始遇到了延时问题:GFS引入了高一数量级的延时退步,比如打开数十万个文件要花好几秒。而且Dremel的元数据格式一开始是为磁盘访问优化的,而不是为网络往返。
大量的优化后,使用GFS、计算存储分离的Dremel性能超过了原来的使用本地磁盘的版本,无论是吞吐还是延时。
计算存储分离还有着其它明显的好处:
- GFS本身是完全托管的服务,有助于Dremel保持SLO和稳定。
- 不再需要将GFS上的共享表加载到Dremel的本地磁盘上了。
- 不加载数据就不需要扩容,其它团队就更容易接入Dremel了。
而当Google的分布式文件系统从单master的GFS升级到多master的Colossus后,Dremel也跟着享受到了服务规模与稳健性上的升级。
内存解耦
shuffle是query执行性能的瓶颈之一。Dremel一开始参照MapReduce的实现,使用计算节点的本地内存和磁盘来存储排序好的中间结果,但带来了很多问题:
- shuffle次数随着参与者数量的平方增长(M×N)。
- 资源碎片化、任意一端停顿会导致另一端跟着停顿、多租户隔离性差。
2012年Dremel实现了基于Colossus的shuffle,2014年又扩展到了支持全内存query执行的shuffle架构。新架构中混合使用了内存和磁盘。
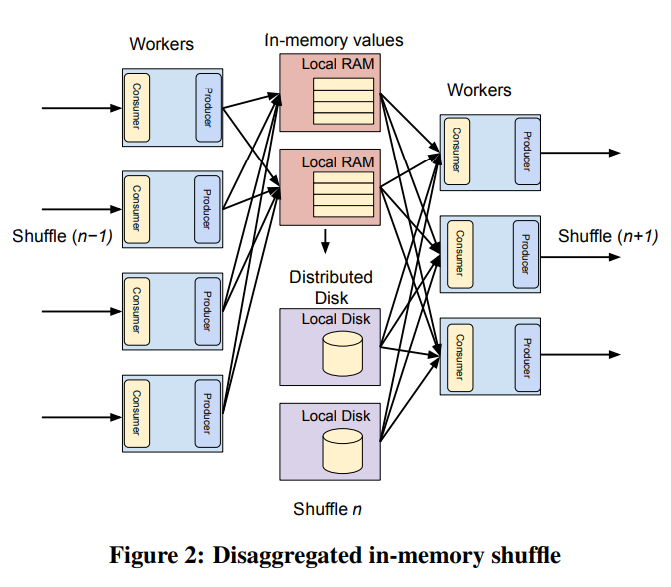
新架构的效果:
- shuffle的延时减少了一个数量级。
- shuffle支持的数据量增加了一个数量级。
- shuffle的资源消耗减少了超过20%。
这种解耦内存的方式与shuffle的实现显著影响了后续的Flume和Google Cloud Dataflow等产品的架构。
观察
解耦是数据系统的一种潮流,能提供更好的性价比和弹性。解耦突出体现在以下几方面:
- 规模效应,存储的解耦路径从RAID、SAN、分布式文件系统,一直到了数据仓库级别的运算。
- 普适性,无论是OLAP还是OLTP系统都在朝着解耦的方向,如Spanner、AWS Aurora、Snowflake、Azure SQL Hyperscale。
- 更上层的API,一些数据访问的API还自带了filter和aggregation支持,而实现上可能一路下推到硬件层。
- 将资源封装为服务增加了价值,例如Dremel的shuffle服务。
原地数据分析
在2005年Jim Gray等人的paper中设想了一种科学计算用到的数据管理方式,将DB和文件系统结合起来,实现秒级查询PB级别的数据。
事实上整个社区正在从传统的数据仓库向着数据湖分析架构转变中。其中的三种核心转变是:
- 从多个数据源消费数据。
- 避免了将OLTP数据导入数据仓库的ETL流程。
- 允许多种计算引擎操作数据。
Dremel的演进
Dremel的初始设计还残留着传统DBMS的影子:
- 需要先载入数据;
- 数据要存成指定格式;
- 数据对其它工具不可见。
Dremel在迁移到GFS的过程内部公开了它的文件格式(列存+自描述),这样其它工具(如MapReduce)也能直接生成Dremel需要的文件,或直接读取Dremel文件。这样Dremel可以和很多工具结合起来,不再需要反复转换数据格式,数据与执行引擎也解耦了。Google的很多后续产品(如Tenzing、PowerDrill、F1、Procella等)都采用了类似风格。
随后Dremel从两方面完善了这种“原地分析”的方式:
- 增加更多的格式。尽管这样带来了运行期读取和解析的开销,但用户愿意多点延时而不要转换数据格式。
- 联合查询(federation query)。Dremel可以分析来自不同引擎——包括Google Drive——的数据。这样能充分利用不同引擎的优点(体现了‘One Size Fits All’: An Idea Whose Time Has Come and Gone的思想)。
原地分析的缺点
- 很多用户(尤其是Google外的)不愿意自己管理文件,或不能保证安全可靠。
- 原地分析意味着没有优化存储格式或增加统计信息的优化空间了,进而导致许多常用的优化手段都没办法用。
- 修改、删除数据或变更schema都变得不现实。
这些需求催生了BigQuery Managed Storage。托管数据和自行管理的数据需要被同等对待。
这种混合了原地分析和托管存储的模型也可见于NoDB和Delta Lake。
Serverless计算
Dremel的这种弹性、多租户、按需的服务,现在被称为Serverless。
Serverless的开始
传统的DBMS需要部署在特定机器上;后来的MapReduce等大数据系统只支持单租户。而Dremel一开始就选择了Serverless以满足其功能需求。Dremel主要通过三个方面来实现Serverless:
- 解耦。计算、内存、存储解耦可以降低成本。
- 容错性和可重启性。这也对query的执行和分发提出了要求:
- 每个子任务都要是确定性的、可重复的,从而允许最小化出错时的重试范围。
- 任务的分发器要能支持重复发同一个任务。
- 虚拟调度单元。这种资源单位比传统的多种类型的物理资源更适合于Borg这样的容器环境,也能将调度和用户看到的资源分配与实际的容器机器资源分配解耦。
这三种思想启发了后面的很多系统。解耦已经被广泛接受了,Snowflake也使用了虚拟调度单元的概念,而各种云产品要么支持按需使用,要么把自动扩缩容作为卖点。
Serverless架构的演进
以下是Dremel近年来在Serverless方面的新思路:
- Dremel在2012年用集中式调度取代了旧paper中的dispatcher。新的调度器能根据全集群的状态来做决策,达到更好的利用率和隔离效果。
- 前面介绍过的shuffle层可以用来解耦调度与不同阶段的query执行。shuffle结果可以作为一种checkpoint,因此调度器可以放心地抢占worker,将资源交给其它job。
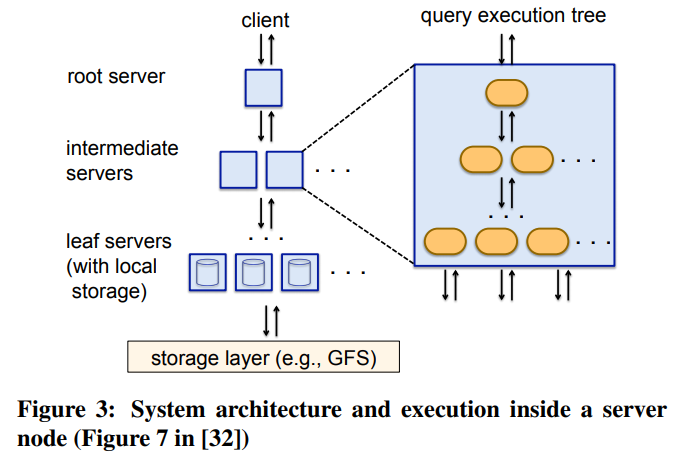
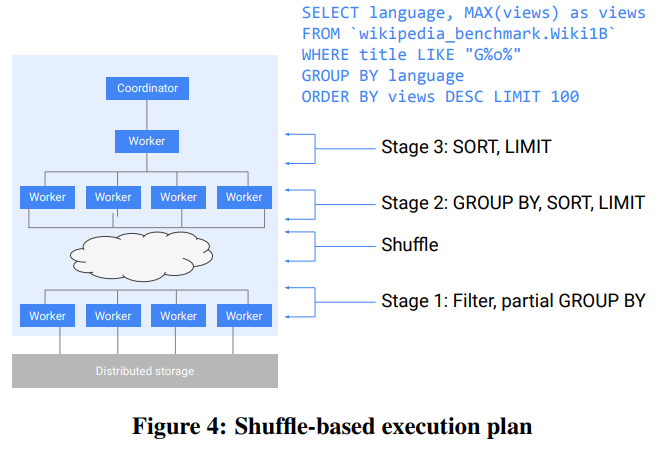
- 旧paper的执行模型如图3,是一种固定的树型结构。之后Dremel演进到了图4的DAG结构,更加灵活,也能支持更大的规模。
- Dremel会在运行期收集统计信息,用于动态修改执行plan,比如用哪种join(broadcast还是hash)。这要归功于新的shuffle和集中式调度。在broadcast和hash的例子中,Dremel会先选择hash join,同时shuffle两侧,但如果其中一侧结束得很快,size小于broadcast的阈值,Dremel会取消另一侧的shuffle,转而执行broadcast join。
针对嵌套数据的列存
Dremel支持嵌套结构(Protocol Buffers)的原因很简单,Google内的数据几乎都是存成这种格式的。 Dremel的paper之后,很多系统都开始支持这种针对嵌套数据的列存格式了:Parquet直接源于Dremel paper、ORC、Apache Arrow。
这些格式都支持嵌套和重复数据,但方式不同。Dremel和Parquet使用了repetition level和definition level。
ORC记录了重复字段的长度和标记optional字段是否存在的boolean。
Arrow的做法类似于ORC,但它记录了重复字段的offset,这样有助于内存中直接访问数组元素。而ORC的做法更适合压缩,因此适合用于文件中。
这些方法各有取舍。repetition/definition level的思路是将与一列有关的schema信息都封装到这列里面,这样访问一列不需要先读它的祖先。但这会导致多余的存储,因为每个child都重复着祖先的结构信息。数据结构越深和越宽,冗余信息越多。
下图是Dremel用Google内部的数据集做的统计,如果将RL/DL换成ORC的方案,这些数据集平均大小能减少13%。
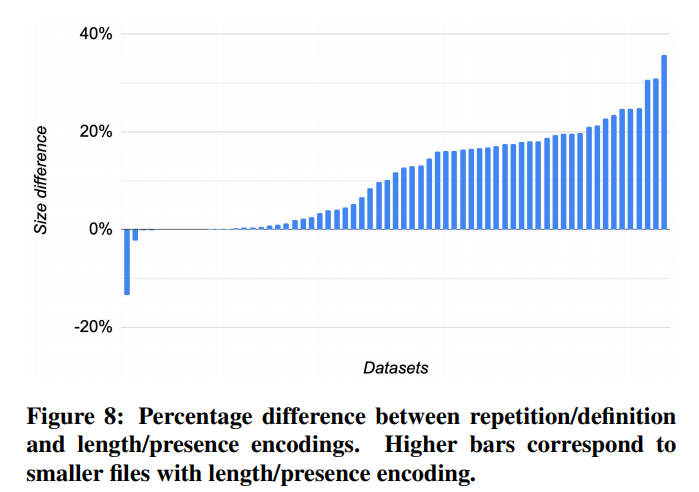
但RL/DL在读的时候有一定优势:不需要读祖先。而使用ORC的方案就要读祖先,会多一些I/O。
2014年Dremel公布了它用于在嵌套数据上做计算、过滤、聚合的算法,同年Dremel开始使用新的列存格式Capacitor。
内嵌求值
Capacitor的接口直接内嵌了filter功能,可以解析SQL谓词。这一功能被所有使用Capacitor的Google系统所使用——Dremel、F1、Procella、Flume、MapReduce等。
Capacitor使用了以下技术来高效过滤数据:
- 使用统计信息来裁剪掉不必要的partition和简化谓词。如
EXTRACT(YEAR FORM date) = 2020先被改写为date BETWEEN '2020-01-01' AND '2020-12-31',再将不在这个时间段的partition去掉。另一个例子是ST_DISTANCE(geo, constant_geo) < 100,会根据统计信息算出constant_geo覆盖的区域,再将位于这些区域的值合并起来。 - 向量化。
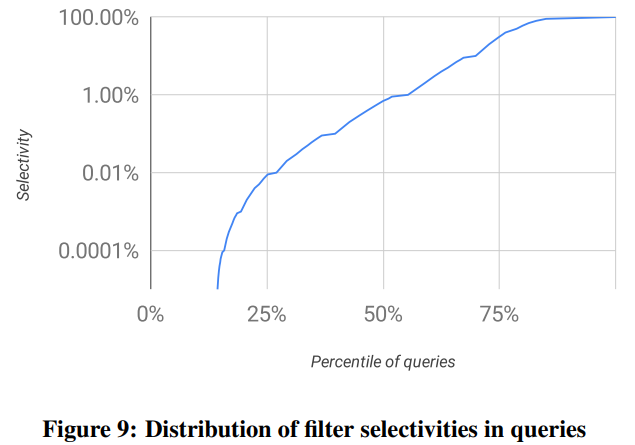
- skip索引。经观察,Dremel/BigQuery中使用的filter的选择性通常都非常强(见图9),需要有快速跳过一片记录的能力。Capacitor在写的时候会把每列的数据分为多个segment,再分别压缩。在扫描时可以直接排除掉不需要的segment,不需要解压缩。
- 谓词重排序。重排序filter中谓词的最优算法是已知的(link),需要的输入是每个谓词的选择率和开销。Capacitor会使用多种启发式方法,根据是否使用字典、cardinality、NULL的密度、表达式的复杂度来决定如何排序。例如,考虑
p(x) AND q(y),其中x没有字典,cardinality很大,而y有字典,cardinality很小,那么最好先求值q(y),即使它表达式更复杂。
行重排序
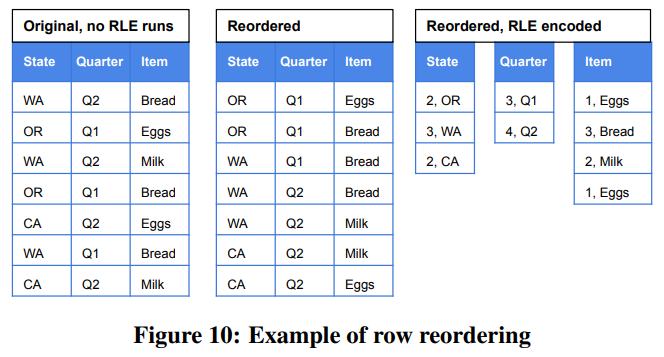
通常分析引擎中行序都不太重要,因此Capacitor可以自由重新排列行以达到更好的RLE效果,如图10。
但这里最优解是个NP完全问题。而且不是每列效果都一样——长字符串上短的RLE长度也要比短的INTEGER上很长的RLE效果更好。最后我们还要考虑到不同列的使用场景不同:有些列常被用在SELECT中,而另一些列常被用在WHERE中。Capacitor使用了一种基于抽样和启发式规则的近似模型。
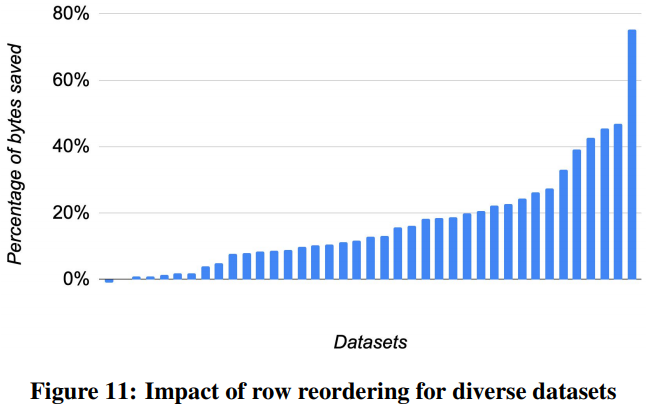
实践中行重排序的效果好得惊人。下图中一共有40个数据集,重排序行之后体积平均减少了17%,有些达到了40%,最好的达到了75%。
更复杂的schema
Protocol Buffers支持递归,可以用于表达树等结构:
1 | message Node { |
但这样递归深度是没办法先验知道的。Dremel一开始不支持递归结构,但在Capacitor中增加了对递归的支持。
另一种挑战来自存储JSON或XML这样的没有严格schema的数据,可以使用proto3中的Any来支持这样的数据。这种挑战还来自同一列的数据类型可能不同。这个问题Capacitor只是部分解决了。
在大数据上的交互式查询延时
前面介绍的设计原则(解耦、原地分析、Serverless)与实现交互级别的延时是冲突的。传统的计算下推优化与解耦冲突;存储格式优化与原地分析冲突;定制机器优化与Serverless冲突。
Dremel使用了以下优化从而在不违反上述设计原则的同时使延时达到了交互式分析的要求:
- stand-by机器池,请求来了立即可服务,减少了冷启动时间。
- 探测执行,类似于MapReduce的做法。Dremel会将query分成大量小任务,这样机器间执行时间更均匀,同时对慢任务的backup执行代价也更小。
- 多级执行树。
- Dremel内部的schema也是列存的,避免了解析完整schema的开销。
- 使用轻量压缩算法来平均CPU和I/O开销。
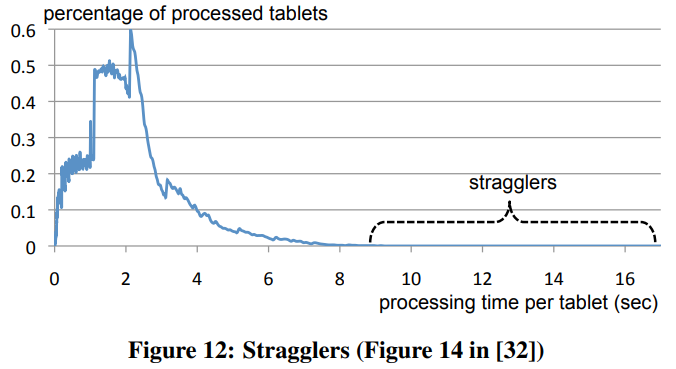
- 近似结果。Dremel在处理top-k和distinct时会使用一轮的近似算法。另外用户可以指定返回结果需要扫描的数据量的阈值,比如只扫描98%的数据就可以返回,同时还能避免长尾对整个query延时的影响。图12显示这种优化可以减少1/2到2/3的延时。
- query延时分层。Dremel在调度器层面保证了快query不会被慢query阻塞,允许按query类型和优先级抢占已经运行的task。
- Dremel的root server会批量获取Colossus的文件元数据,随后跟着query一起发给底下的server。另一种优化是增大单个文件的体积,减少一张表的文件数,从而减少文件操作的数量。
- 用户可以预留一些资源只用于处理延时敏感的任务。这些资源在空闲时也可以给别人用,但Dremel保证了在需要时会立即将资源还给预留用户使用。
- 自适应调整query规模。Dremel可以根据query的特点来调整DAG,如
COUNT和SUM只需要最多两层,而top-k则可以增加一层预聚合。