原文:Large-scale incremental processing using distributed transactions and notifications
TL;DR
Percolator是Google用于构建增量web索引的数据系统。它的价值在于提出了一种基于NoSQL(BigTable)的两阶段提交(2PC)实现。
Percolator的2PC实现有以下特点:
- 部分去中心化:依赖中心化的Timestamp Oracle(TSO),但不依赖集中式的锁管理节点。
- 乐观锁:不能阻塞,检测到冲突需要abort。
- Snapshot Isolation:读比较旧的ts时不会被写block;但为了避免违反SI,读比较新的ts时可能会被写block。
- 惰性清理:client失败导致的状态不一致不会立即被清理(没有中心节点)。client之间有种协作关系,如果发起事务的client挂了,根据事务进度,其它client既可能帮它abort,也可能帮它commit。
以上很多特点都是源于Percolator没有中心节点,也导致了它的2PC延时偏高(尤其是失败时),但优点是能适应巨大的规模。这也是Google系产品的一个特点,可以不那么快,但一定要支持巨大的规模。
Google系产品的第二个特点是很积极地使用已有产品来构建新系统,这里Percolator选择了基于BigTable来做,就体现了这一点。
这篇文章实际讲了Percolator的两块内容,一个是2PC,另一个是observer,一种可级联的触发器,但后者似乎没有太多关注。
Introduction
Google的web索引构建的规模非常巨大,MapReduce一开始就是为此设计的,Google使用了若干个MR任务定期计算全量的web索引。但这个系统没办法快速响应增量修改,新网页被收录的时间要以天为单位。
面对这个需求,Google有两个选择,一个是使用DBMS,一个是使用NoSQL。前者的问题是规模上不去(Google当时还在用分库分表的MySQL),后者可以支持这么大的规模,但问题是不支持分布式事务。
最终Google选择了用BigTable来构建Percolator,在此基础上实现了支持ACID的分布式事务、Snapshot Isolation(SI)、以及一种触发器机制(observer)。
Design
Percolator的架构上与2PC相关的有:
- 1个TSO,提供全局单调增的timestamp。
- 若干个client。
- 一套BigTable。
另外为了实现触发器,Percolator还单独有worker进程和一个轻量的锁服务。
Transactions
Percolator的数据模型是二维的,行×列确定一个cell。一个事务可以包含若干个cell,支持跨表、行。
Percolator没有引入中心节点,而是将所有与2PC相关的元数据都保存在了对应的BigTable行中。
具体来说,Percolator每行对应BigTable中一行,每列对应BigTable中5列,每次修改都使用BigTable的单行事务。
对于列c,它会对应BigTable中以下5列:
c:lock,未提交的事务会在其中记录primary的位置,commit或abort后被清除。c:write,保存最大的已提交版本。c:data,保存多版本的数据,可能包含未提交的数据。c:notify,给触发器用的提示。c:ack_O,触发器运行记录。
这里关注前3列。
每个事务都有一个primary,是这个事务中任意一个cell,它的write列会用于标识整个事务是否可abort,或必须commit。其它所有参与的cell都称为secondary。
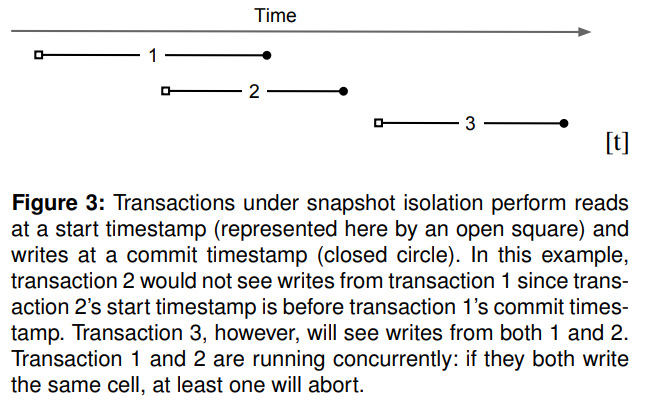
Percolator使用BigTable的版本来做MVCC并实现了SI。每个事务对应一个时间范围[startTS, commitTS],读操作对应[0, startTS]。SI会阻止以下几种情况(参考图3):
- 写写冲突:两个时间范围有重叠的事务同时修改一个cell,只会有一个成功。
- 写读冲突:同一个cell上的读操作与未提交的写冲突。
但SI没办法避免write skew。
以下是一个使用Percolator的例子:
1 | bool UpdateDocument(Document doc) { |
Percolator的Get()会检测要读的cell的lock列的[0, startTS]有没有数据,如果有,说明当前snapshot有未提交的事务,可能修改当前snapshot的状态。为了保证SI,Get()需要退避重试,等待当前snapshot状态确定了(没有未提交事务)才能读出数据。如果当前没有冲突,Get()会根据write列在当前snapshot的最后一次提交版本,返回data列对应的数据。
具体实现为:
1 | bool Get(Row row, Column c, string* value) { |
Percolator的写分为两阶段,第一阶段是Prewrite(),对要写的每行,它先会检测是否有与之冲突的写(大于它的startTS的已提交事务或活跃的未提交事务)。如果没有,则将数据写入data列,primary信息写入lock列,版本都使用startTS。
具体实现为:
1 | // Prewrite tries to lock cell w, returning false in case of conflict. |
第二阶段是Commit(),它会再次检查所有行是否有与之冲突的写(复用Prewrite())。然后先提交primary,更新write列并删除lock列对应内容。注意lock列可能被其它client清理掉,此时当前事务只能abort(不需要做其它清理)。提交primary成功后依次提交每个secondary,也是更新write列并删除lock列对应内容。
当primary提交成功后,整个事务就提交成功了,即使client在提交secondary过程中挂了,其它client也会后续协助这个事务将其完成。如果primary提交失败,其它client会协助做完所有清理。
具体实现为:
1 | bool Commit() { |
primary是Percolator实现的精髓,它将多行的原子操作(事务提交成功与否)转化为了单行的原子操作(primary提交成功与否)。
所有的事务实现本质上都体现了这种downscale的思想,将某个原子操作降级为对更小scope(或临界区)的原子操作:
- 分布式事务可以利用中心节点,降级为中心节点状态的单机事务;
- 单机事务可以降级为某个
mutex的原子操作;mutex的原子操作可以降级为一次CAS操作。
考虑到client挂掉的情况,当其它client看到一个已经开始了很久的事务时,会开始做清理。清理的第一步是确认事务状态:
- 如果对应的primary cell的write列已经有这个事务的记录时,说明这个事务已经提交成功了,接下来依次提交各个secondary。
- 否则说明事务未提交成功,应该rollback。
rollback过程:
- 尝试清除primary cell的lock列与data列,如果失败则说明可能有其它client在并行,就结束rollback。
- 依次清除各个secondary。
为了避免自己在做的事务被其它client给rollback掉,client可以将自己的状态记在Chubby中,并定期更新自己的wall time,这样只有它真正挂了,或很久没有工作时,它的事务才会被rollback掉。
Timestamps
TSO是Percolator中唯一的单点服务,它的性能要足够好才能不成为整个系统的瓶颈。Percolator的解法是batch:
- TSO每次持久化都提前分配好一段时间的timestamp,减少持久化次数,后续分配只走内存。
- client在申请timestamp时会批量申请多个timestamp,供后续若干个事务使用。
优化之后的TSO单机可以每秒分配两百万个timestamp。
Notifications
略
Discussion
Percolator的性能瓶颈之一就是单个事务访问BigTable次数过多(初始版本差不多50次RPC)。Percolator的优化包括:
- 帮助BigTable实现了read-modify-write的单行事务(通过conditional update实现)。
- client在开始事务前会等待几秒(Percolator的目标场景对延时不那么敏感),将发往相同BigTable tablet的请求聚合成一个batch操作。理论上这个优化会增加冲突的概率,但Percolator场景中冲突本来就很少,因此影响不大。
- 每个读请求也会等待几秒以增加聚合的概率。
- 每次读个别列的时候,把整行都预读出来,因为大概率后面就会读这行的其它列。
Percolator的目标场景:
- 巨大的规模;
- 冲突概率很小;
- 更重视整体吞吐,而不是单次请求的延时(因为是离线任务)。
近年有很多NewSQL系统使用了Percolator作为其事务模型,但从Percolator本来针对的场景来看,它只适用于冲突很小的情况,对于冲突很多的OLTP场景,它的rollback开销会非常大。后面开发的Spanner就采用了不同的2PC实现方式。