原文:AnalyticDB: Real-time OLAP Database System at Alibaba Cloud
TL;DR
AnalyticDB(以下简称ADB)是一种支持复杂ad-hoc查询的实时分析系统。
ADB的主要特点:
- 读写节点分离,之间通过pangu异步交换数据,或通过RPC同步交换数据。优点是可以避免相互影响,缺点是高数据可见性就会有一定的性能损失。
- 索引功能强大:
- 全量数据中所有列都有索引,增量数据也有简单的索引。
- 运行期可以基于选择率跳过部分索引,不会因过度使用索引而导致性能下降。
- 索引类型丰富,string、int、JSON、向量等类型的列都可以建索引,还可以创建全文搜索索引。
- 仔细设计过的列存格式。
- 使用MapReduce做全量数据的compaction。
这篇文章中有些细节看得不是很明白,以下内容部分来自脑补。
总体感觉ADB的性能确实好。缺点是可能成本会比较高,索引的构建过程的计算开销与所有列的索引对应的存储开销都挺高的。存储开销可以通过更好的编码和压缩来控制,但会导致计算开销更高,这样base compaction时间会更长,常规路径的数据可见性会受到一些影响。
如果将compaction分成更多级别,一步步提高优化等级,优点是数据可见性比较好,缺点是第一次compaction时如果还是要为每列都建索引,则优化不够的话存储开销大,或者读开销也会大。而通常query都会更倾向于读近期的数据,相当于大多数query都只享受到了低优化等级。
本质上数据可见性与优化就是矛盾的,没有万能药,只能靠工程上的tradeoff。
相关工作
这部分对比了ADB与其它产品。
- OLTP,如MySQL、PostgreSQL,使用行存、B+树、写路径更新索引,这些是不利于分析的特性。
- OLAP。Vertica是列存,但不支持传统的索引,只记录Min/Max值等信息,剪枝不顺利时查询延时高。Teradata和Greenplum是列存,支持用户指定要建索引的列,但有两点不足:写路径更新索引;列存格式点查性能不够。
- 批处理系统,像Hive、SparkSQL这样的系统一次查询时间太长;Impala使用列存和pipeline,将查询延时减少到了秒级,但只有列的统计信息,没有索引,不善于处理复杂查询。
- 实时OLAP。Druid和Pinot都使用列存和基于bitmap的倒排索引。Pinot在全部列上都有索引。Druid只在维度列上有索引,因此遇到非维度列上的条件时就很慢。两个系统都在写路径上更新索引,欠缺对JOIN、UPDATE、DELETE的支持,点查性能都不好。
- 云产品。Redshift使用了列存和MPP架构,ADB的优点是读写节点分离。BigQuerry是列存加树形执行,没有索引,而ADB有丰富的索引,DAG执行。
建表与分区
ADB支持标准的DDL:
1 | CREATE TABLE db_name.table_name ( |
每张表可以有两级分区,其中primary partition只支持哈希。subpartition通常是有时间属性的列,用于做数据自动淘汰——一旦subpartition数量超过配置值,最老的会被整个淘汰掉。
(看起来每张表的分区是静态分区的,这篇文章没有提到如何做resharding和schema change)
架构
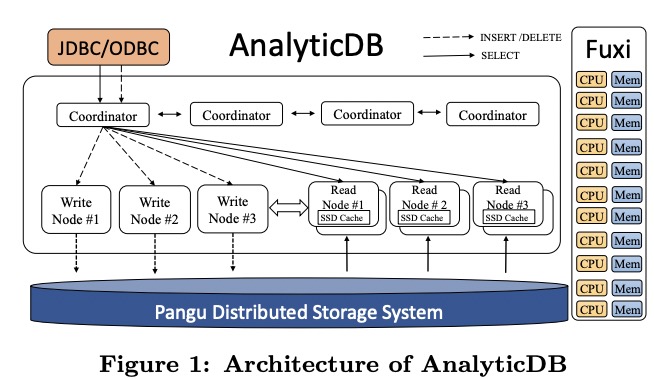
ADB的构架底座是标准的阿里云飞天三件套,即Fuxi用于调度,Pangu用于分布式存储,Nuwa用于分布式锁(图里没有,猜测后面出现的ZK实际指的是Nuwa)。在其上是ADB的三类节点:coordinators、write nodes、read nodes。其中读写节点是物理分离的。
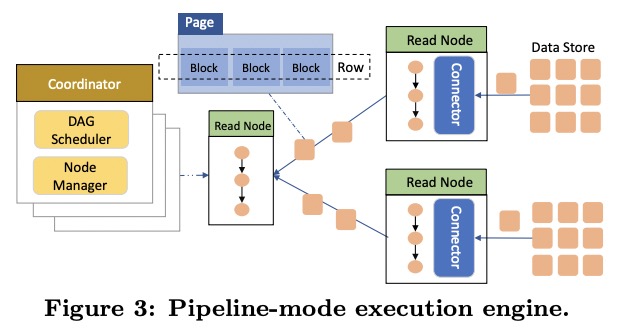
ADB中数据是以page(column block)为单位流动的,整个处理过程是pipeline的。
写节点
写节点中会选出一个master负责调度分区。coordinator接到请求后会转发给对应的写节点。写节点会先将数据写进memory buffer,再批量刷到pangu上,然后将对应的version(log sequence number)返回给coordinator。这个过程产生的pangu file是log file。
一旦log file变多,ADB会启动base compaction,将所有log file和原本的data file、index、 file合并变成新的data file和index file。
读节点
每个读节点会被coordinator按哈希值分配若干个partition(疑问1:哪个coordinator,是每个DB有自己的coordinator,还是所有读节点也有一个leader?疑问2:普通哈希还是一致性哈希?有coordinator的话可能更像是普通哈希,那如何解决节点加入离开的扰动?)

这种分配方式避免了equi join时的数据重分布(ADB表示超过80%)。
同一个partition可能会被分配给多个读节点,从而保证了可靠性。
读节点会从pangu加载全量数据,之后从写节点定期拉增量数据,再更新到本地SSDCache中。这么做的好处是不需要与写节点同步(compaction后会重新载入全量和增量数据吗?)。
读节点支持两种数据可见性:real-time会去写节点拉数据,保证写完立即可读,但开销大;bounded-staleness只读本地数据,开销低,但看不见新写的数据,其数据延时最大为拉取增量数据的间隔。
为了不影响读延时,ADB中写节点可以主动将数据推给对应的读节点。如果读节点拉数据失败,它可以直接从pangu上读取log file并应用到本地cache上。

集群管理
在Fuxi之上,ADB构建了一个管理模块,称为Gallardo,负责分配节点给物理机器。(看起来每当有新DB创建时,就会有新节点,因此这三类节点是在DB间隔离的)
存储
ADB中数据文件分为若干个row group(每3万行),每个row group内每列数据是一个data block,这样兼顾了列存的扫描效率与行存的点查效率。

复杂类型(如JSON和向量)的每个值可能很长,ADB采用了另一种方式。每个复杂类型列的数据会单独写进一个文件,里面分为若干个32KB的FBlock,这样data block中只需要记FBlock的索引和行范围,就把变长数据转为定长了。一行可能特别大,可能跨FBlock。

数据文件的元数据也被保存为了单独的文件,且默认缓存在内存中,如Figure 6。
元数据文件包含了列的统计信息,如MIN/MAX、NULL数量、cardinality、SUM、字典、block map等。
读节点会为增量数据生成简单的sorted index,即按数据值排序的row_id数组(目测row_id是每个分区自己产生的自增ID)。
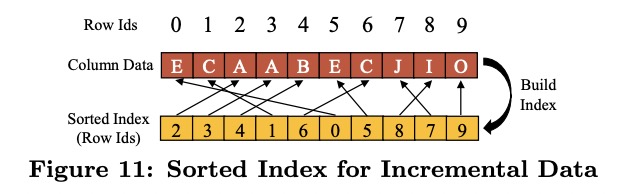
每个data block有3万行,每个row_id占2B(short),则每个sorted index block占60KB。sorted index block会和增量数据一起写进读节点的cache,而不进pangu。
另外读节点还会维护一个bitmap,记录哪些row_id被删除了。这个bitmap是分段copy on write的,因此读不需要加锁。
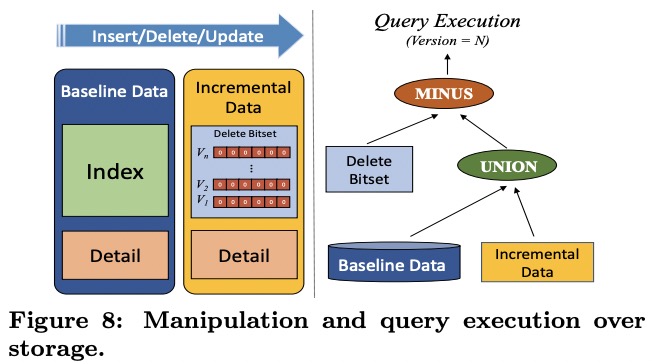
在做全量compaction时,当前的增量数据会被freeze,与全量数据一起由MapReduce任务转换为新的全量数据。

索引管理
ADB中所有索引都是局部索引。每列都有倒排索引,索引值为row_id数组。每个索引单独保存为一个文件。在查询的时候从存储层出去的就只是row_id了。

为了避免过度使用索引导致的性能损失,ADB会在查询时按每个索引的选择率从低到高排序,依次执行。如果应用了某个索引后,整个节点的选择率已经低过阈值了,后面的索引就会被跳过,直接根据当前已经拿到的row_id的原始值进行过滤。
在处理JSON类型的值时,ADB会把JSON整个拍平,如{id, product_name, properties {color, size}}会被分为id、product_name、properties.color、properties.size四列保存。这个JSON列的所有子列索引会被保存在一个文件中。(但没说怎么处理JSON数组,猜测要么按Dremel的方式,要么不为数组建索引)
ADB也支持全文索引和向量索引(不太懂,跳过)。
在实际保存索引时,ADB会自适应使用bitmap或int数组。用户也可以显式关闭某些列的索引以节省空间。
读节点上除了会缓存索引数据外,还会缓存query条件。通常开销大的query会被反复执行,命中率高,而命中率低的query通常比较轻量,或对延时敏感低,因此不命中也没关系。
优化器
ADB中的优化策略分为CBO(基于开销)和RBO(基于规则)。规则包括:
- 基础优化:
- 剪枝
- 下推/合并算子
- 去重
- 常量折叠
- 谓词推导
- 针对不同join(broadcast hash join、redistributed hash join、index join等)、聚合、join重排列、groupby下推、excahnge下推、sort下推等的探测优化
- 高级优化(如公共表表达式Common Table Expression)
除了这些,ADB还有两种优化技术,存储感知优化(storage-aware optimization),以及实时采样。
存储感知优化
在下推谓词时,主要工作在于判断哪些是要下推到存储层,哪些留在计算层。其它系统通常只能下推单列的AND的谓词,而没办法下推函数和join。
ADB引入了STARs框架来做谓词下推,它可以把存储引擎的能力抽象为一种关系代数能处理的概念,从而可以将计算层和存储层的开销统一起来做下推优化。

在下推join时,前文介绍了ADB将相同哈希值的partition分配给同一个读节点,这样equi join就不需要传输数据了。对于不满足这一条件的join,ADB会从存储层获取到两张表的大小,以决定最高效的传输方式。
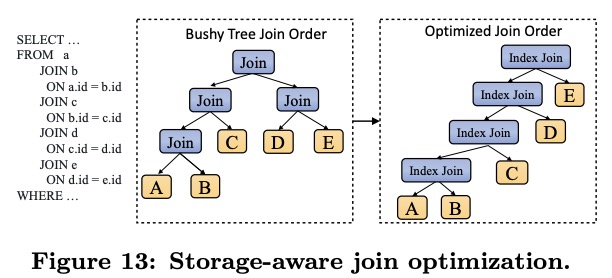
如果参与join的列大多数都是partition列且有索引,那么ADB会将hash join转为LeftDeepTree形状的lookup join。ADB还会将很多算子下推到索引中,如count等。
实时采样
传统的实时收集统计信息的方式不适合ADB的低延时需求。ADB会根据多种规则,定期发送采样请求给存储层来计算cardinality等统计信息。
执行器
ADB的执行器是面向列的(不会过早组装行),以DAG形式执行,执行过程是向量化的。
ADB使用了ANTLR ASM来做代码生成,不同机器可以生成不同的代码,如是否使用SIMD指令(包括AVX512)。
计算层和存储层之间的协议使用不需要反序列化的二进制格式。
评估
(只是一些摘要)
ADB和Greenplum的索引构建对比。ADB时间更长,但存储空间更小,且不影响在线请求。
Greenplum的索引不支持ORDER BY,遇到了会变成full scan。
Druid可以根据时间排除掉不要的partition,但剩余的partition仍然会遇到非维度列没有索引的问题。且Druid只对字符串建索引。
Greenplum会使用hash join,有构造HashMap的开销,因此比ADB慢。
ADB的查询性能不怎么受到表大小的影响,严重受到索引计算和参与的行数的影响。