TL;DR
Druid是一种实时分析系统,它主要面向时序数据的复杂分析。Druid使用了lambda架构,使用实时节点来服务新数据,历史节点来服务历史数据,从而同时保证了查询效率、空间效率、数据可见性。Druid是存储计算分离架构,支持多种存储引擎,如HDFS、AWS S3等。
Druid比较有价值的点是它的lambda架构、列存、倒排索引、良好的可伸缩性和高可用性。
架构
Druid服务的典型时序场景,数据模式如下图:

一个Druid集群包含多种角色,如下图:
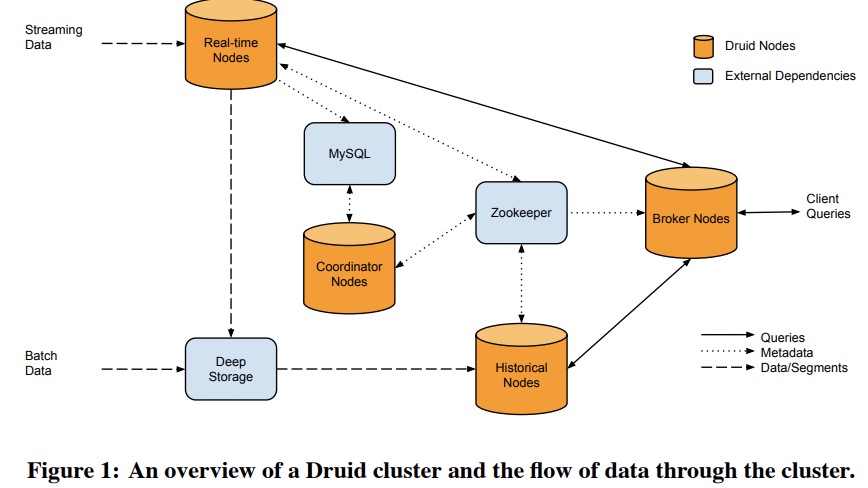
实时节点(Real-time Nodes)
实时节点负责服务实时读写请求,新写下去的数据立即可读。这些节点只负责最近很短时间段的数据,且定期会把这些数据发给历史节点。Druid有一个Zookeeper集群来管理所有实时节点,每个节点会将它们的状态和服务的数据范围写到ZK上。
实时节点针对新写的数据有一个内存中的行格式index,定期会转换为列存格式写进本地磁盘中,再load上来,从而避免JVM堆溢出。所有磁盘文件都是不可变的。
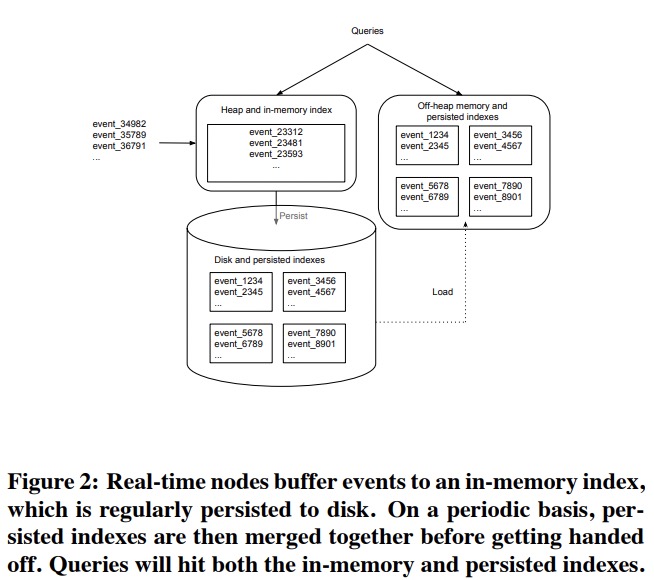
每隔一段时间实时节点会有背景任务将所有本地文件compact成一个大文件,称为segment,这个segment会包含当前节点一个时间段内的所有数据。之后实时节点会将segment上传到存储引擎。
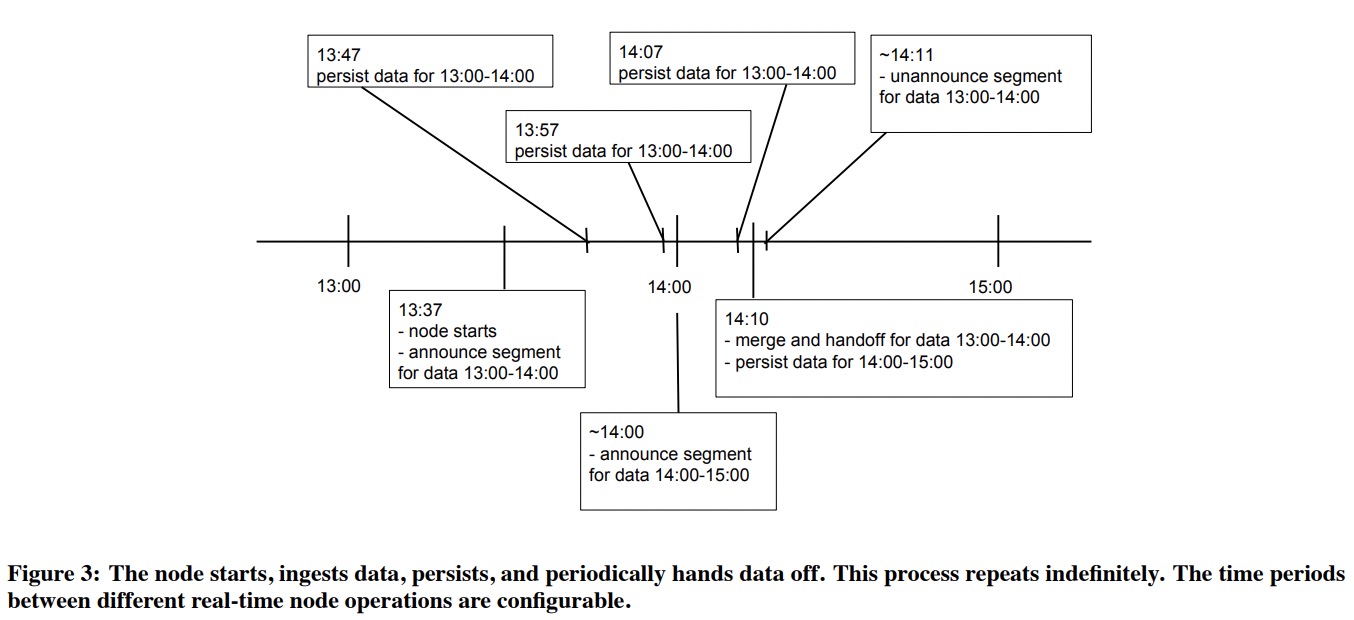
一开始实时节点在ZK上记录它服务13:00-14:00的数据。在到达14:00后,它会声明自己同时还服务于14:00-15:00的数据,再等一会前一小时的晚到数据,不立即持久化。等到持久化完egment并上传成功后,实时节点会在ZK上将13:00-14:00从自己的服务范围去掉。
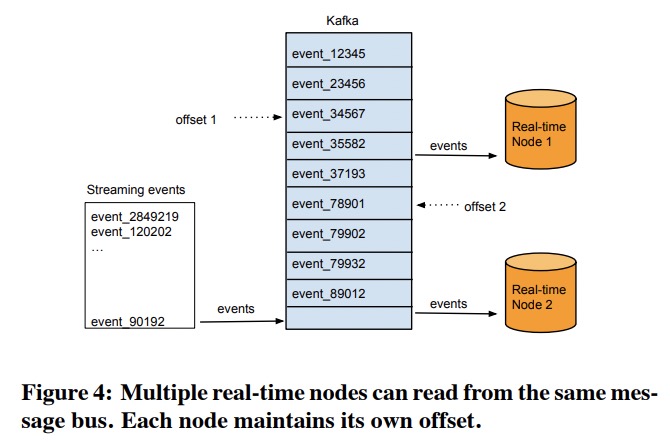
实时节点的上游可能是像Kafka这样的系统,实时节点会在每次写磁盘文件时把从Kafka中读到的offset记录下来。不同的实时节点可能会对应相同的Kafka流,相当于创建了数据备份;也可以一个实时节点对应一个Kafka分片,这样能最大化处理能力。
历史节点(Historical Nodes)
历史节点是shared-nothing架构,相互不知道对方存在,只需要支持非常简单的操作:如何载入、丢弃、服务不可变的segment。
类似于实时节点,Zookeeper也服务于所有历史节点。载入和丢弃segment的请求就是通过ZK发送的,里面会包含这个segment的位置和解压、处理方式。每个历史节点有一个本地的cache进程。历史节点在载入segment前,会先看cache中有没有segment。引入本地cache允许历史节点快速更新和重启,而不需要担心预热。
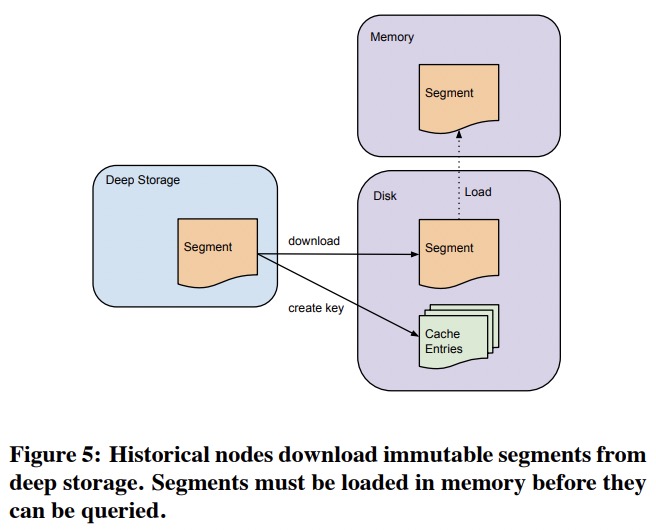
因为只服务不可变的数据,历史节点可以做无阻塞的一致性读、并发scan和聚合。
Druid可以将历史节点分为多层,每层单独配置性能和容错等参数,目的是区分不同segment的优先级。
路由节点(Broker Nodes)
路由节点通过读取ZK上的数据来获得segment的列表和位置,之后将请求转给相应的实时节点或历史节点,最后再将不同节点返回的结果数据合并返回给用户。
路由节点本地维护了一个LRU cache存放segment信息,这样处理请求的时候路由节点只需要去ZK中读那些未命中的segment就可以了。

实时节点的数据无法缓存,因此请求总是会被发给实时节点。
如果ZK不可用,路由节点会假设集群结构不会改变,一直使用cache中的数据。
协调节点(Coordinator Nodes)
协调节点负责历史节点上的数据管理和分布,它会告诉历史节点去载入、丢弃、复制数据,还会在历史节点之间做负载均衡。为了维护一个稳定的视图,Druid会用MVCC交换协议来管理segment(听起来像是复制或compaction),被新的segment完全覆盖的旧segment会被移除掉。
协调节点内部会选举leader,leader以外的节点作为热备,不操作。
协调节点会定期对比当前集群状态和期望的集群状态,再做出决策。这些信息主要保存在ZK上,另外一些配置信息则在MySQL上。MySQL上会有一张表保存所有应该被历史节点服务的segment。所有能创建segment的节点都可以写这张表,如实时节点。MySQL上也有一张表保存segment的创建、销毁、复制规则。
针对每个segment,协调节点会用它匹配到的第一个规则来决定如何管理这个segment。
协调节点在做负载均匀的时候要考虑到查询模式。Druid中的典型查询会覆盖来自一个数据源的近期的连续时间段的segment,且通常segment越小访问越快。
因此Druid会以较快的速度复制最新的segment,从而打散大的segment,分摊压力。Druid有一套基于开销的优化器,会考虑segment的数据源、时间段、大小,来决定这个segment的分布。
通过复制segment,Druid可以避免单个历史节点挂掉影响服务。
如果ZK挂掉了,协调节点就没办法管理历史节点了,但不影响数据安全性。如果MySQL挂掉了,协调节点就停止新segment的指派(交给哪个历史节点)和旧segment的清理,但不会影响其它节点的查询。
存储格式
TODO:Druid中每个数据源会被分为若干个segment,每个负责一个时间段。
Druid要求数据中一定要有一列时间戳,以简化数据管理和加速查询。Druid中数据会先按时间(如一小时或一天)分成若干个segment,每个segment还可以再用其它列分区,从而控制大小。
每个segment的命名包括了数据源、时间段、单调增的version。查询的时候对于每个时间段的数据,只会读最新的segment。
Druid中数据是按列存储的,根据每列的类型选择不同的压缩方式。字符串可以用字典编码,从而将这列转换为一个int数组,如Table 1中的Page列编码为[0, 0, 1, 1]。 这个int数组本身非常适合再次编码。Druid中使用LZF编码这样的int数组。
数字类型的列可以用类似的方式编码。
用于过滤数据的索引
Druid会使用bitmap为string列创建倒排索引。如Table 1中的”Justin Bieber”对应[1, 1, 0, 0],而”Ke$ha”则对应[0, 0, 1, 1]。bitmap经常会使用RLE进一步编码。Druid中使用了Concise算法。下图是Concise算法对于整数数组的压缩效果。
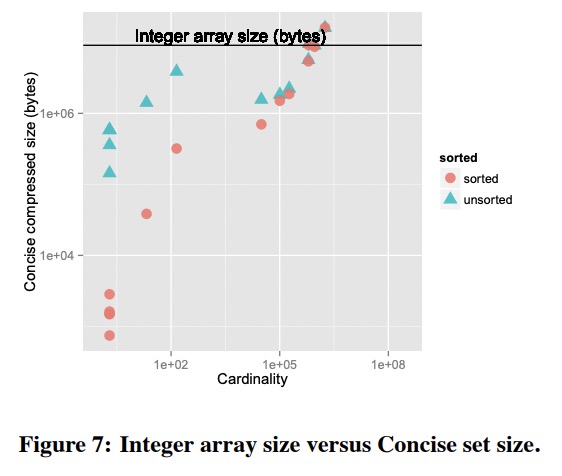
有意思的是图中排序只换来了很小的收益。
存储引擎
Druid可以使用多种存储引擎,类似于Dynamo(这就是它称自己为Dynamo-style的原因?)。
查询API
Druid支持JSON格式的查询API(这篇文章没提到SQL),支持复杂的过滤条件。
1 | { |
聚合的结果可以被其它聚合的表达式所引用。
截止到这篇文章发表,Druid还不支持join,认为join的收益小于代价,原因:「」
- 分布式数据库中join是制约可伸缩性的一大瓶颈。
- 相比对高并发重度使用join的场景的支持开销,join功能上的收益还不够大。
常见的join主要是hash join和merge join,但都需要物化一些中间结果。当数据量非常大时,这种物化会带来非常复杂的分布式内存管理。