Introduction
- 一个巨大规模的多租户系统 vs 多个专用的小系统。
- EB 规模。
之前 Facebook 有很多个规模不大的专属存储系统,导致的问题:
- 开发、优化、管理复杂
- 资源利用率不足:不同服务的资源使用特点不同,有的瓶颈是 IOPS,有的是 CPU,分成多个系统导致了每个系统的资源利用率都达不到最优。
Tectonic 希望用一个巨大的多租户系统替代这些分散的小集群,但有以下挑战:
- 扩展性
- 租户间性能隔离
- 租户级别的优化
扩展性:
- 对于 fs 而言主要挑战在于 meta 管理。Tectonic 的解法是将 meta 分解为多个可扩展的独立层次,同时用 hash 分区(而不是 range 分区)来避免热点。
性能隔离:
- 将有类似流量特点和延时需求的应用分到一组
- 按应用组隔离,从而极大降低了管理难度
租户级别优化:
- client 端驱动,用一种微服务架构来控制租户与 Tectonic 之间的交互。
- 对于数仓:使用 Reed-Solomon(RS)编码来减少空间占用、IOPS、网络流量。
- 对于 blob:先以多副本形式写入,降低写延时;再转换为 RS编码,降低空间占用。
Facebook’s Previous Storage Infrastructure
Blob Storage
Facebook 之前混合使用了 Haystack 和 f4,前者以多副本形式存储热数据,待数据不那么热之后再移到 f4 转换为 RS 编码。
但这种温热分离导致了资源利用率低下。
HDD 的存储密度提升的同时,IOPS 却停滞不前,导致每 TB 对应的 IOPS 越来越少。结果就是 Haystack 瓶颈成了 IOPS,需要额外的磁盘来提供足够的 IOPS,使得它的有效副本数上升到了 5.3(对比 f4 的有效副本数是 2.8)。
此外 blob 生命期也在变短,经常在移到 f4 之前就删掉了,进一步加大了 Haystack 的有效副本数。
最后,它们两个是不同的系统。
非常有趣的历史
Data Warehouse
数仓类的应用更重视读写的吞吐而不是延时,通常会发起比 blob 更大的读写请示。
HDFS 集群规模受到了 meta server 单点的限制,因此 Facebook 被迫搞出几十个 HDFS 集群来满足数仓应用。这就成了一个二维背包问题:将哪些应用分配到哪些集群可以使整体利用率最高。
意思是非常复杂,难以优化。
Architecture and Implementation
Tectonic: A Bird’s-Eye View
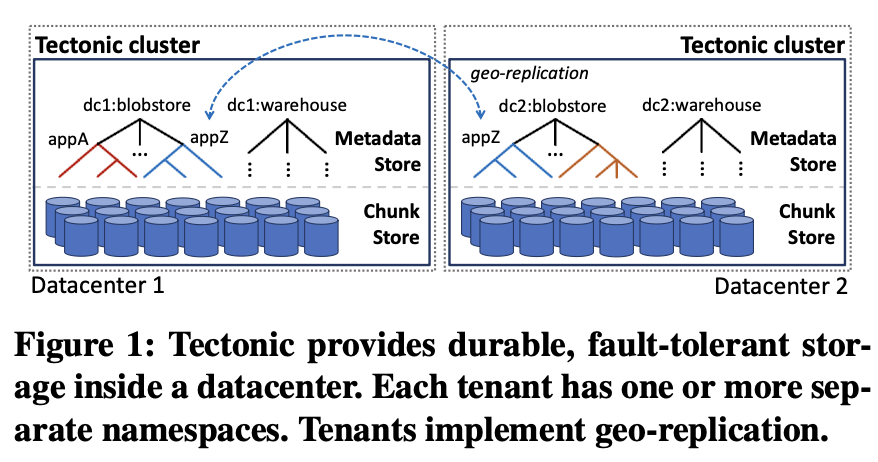
Tectonic 集群只面向单个 datacenter,租户可在其上自行构建 geo-replication。
租户之间不会共享任何数据。
Tectonic 集群在同一套存储和 metadata 组件之上支持任意个 namespace(或 filesystem 目录树)。
应用通过一套 append-only 的层级式的 filesystem API 与 Tectonic 交互。
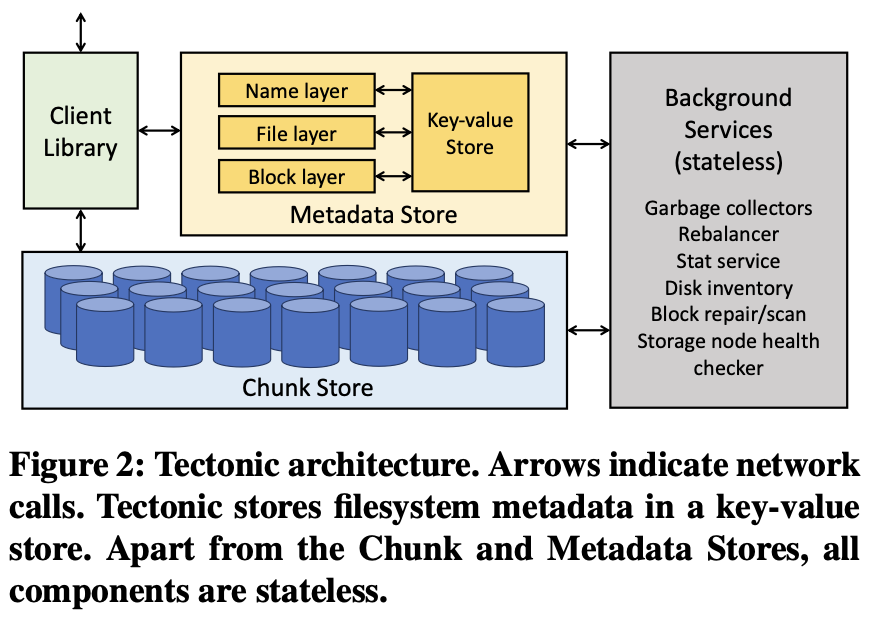
- Chunk Store
- Metadata Store
- bckground services
Chunk Store: Exabyte-Scale Storage
Chunk Store 是面向 chunk 的分布式对象存储,chunk 组成 block,block 再组成 file。
针对扩展性和多租户的两个功能:
- Chunk Store 结构上是平坦的(不受 filesystem 目录树的影响),可线性扩容。
- 不感知上层的 block 或文件语义,与 metadata 解耦,从而简化这一层的管理并提高性能。
Storing chunks efficiently
每个 chunk 被存储为一个 XFS 上的本地文件。存储节点为 chunk 提供的 API 有 get、put、append、delete、list、scan。
存储节点需要负责本地资源在多租户间的公平分配。
每个存储节点有 36 块 HDD,另有 1TB SSD 存储 XFS metadata 和缓存热的 chunk。
Blocks as the unit of durable storage
在上层看来 block 只是一个字节数组。实际上 block 是由若干个 chunk 组成,共同保证了持久性。
Block 既可能是 RS 编码的,也可能是多副本存储。Block 中的不同 chunk 会分布在不同的 fault domain(如不同的 rack)来提高容错性。
看来 chunk 既可能是一个 strip 也可能是一个 replica。
Metadata Store: Naming Exabytes of Data
Metadata store 将所有 filesystem 的 metadata 细粒度分区以简化操作、提升扩展性。不同 layer 的 metadata 逻辑上是分开的,各自再 hash 分区。

Storing metadata in a key-value store for scalability and operational simplicity
Tectonic 使用 ZippyDB 存储 metadata,其内部用到了 RocksDB,shard 间用 Paxos 保证一致性。每个副本都可以处理读请求,但只有 primary 可以提供强一致读。这一层只提供 shard 级别的事务。
Filesystem metadata layers
Name layer 提供了目录到目录项的映射。File layer 将每个文件映射为一组 block。Block layer 将每个 block 映射为一组 chunk(实际是磁盘上的位置),它还有个 disk 到 block 的倒排索引用于运维操作。
Fine-grained metadata partitioning to avoid hotspots
Tectonic 这种分 layer 的管理方式将目录项操作(name layer)与文件操作(file 和 block layer)分离开,天然避免了两者干扰导致的热点。这与 Azure Data Lake Service(ADLS)做法很像,但 ADSL 是 range 分区,相比 Tectonic 的 hash 分区,前者更容易产生热点。
Caching sealed object metadata to reduce read load
Tectonic 支持『封存』(seal)block、file、dir,其中 dir 的封存不会递归,只是不再允许添加直接的目录项。封存后的对象就不再理发了,因此可以放心缓存在各种地方而不用担心一致性受损。这里的例外是 block 到 chunk 的映射:封存后的 chunk 仍然可以在磁盘间迁移,令 block layer 的 cache 失效。但这种失效会在读的过程中被检测出来并自动刷新。
Providing consistent metadata operations
Tectonic 依赖底层 kv-store 提供的强一致操作和 shard 内原子的 read-modify-write 事务支持来实现目录内的强一致操作。
mark,什么叫『强一致操作』?
Tectonic 保证针对单个对象的操作(如 file 的 append、read,以及 dir 的 create、list 等)、以及不跨目录的 move 操作具有 read-after-write 一致性。
kv-store 不支持跨 shard 的事务,因此 Tectonic 也没办法支持原子的跨目录 move。这种 move 需要两阶段:首先在新目录创建一个 link(dir entry 吧我猜),再从旧目录删掉 link。
注意被移走的目录会维护一个指向旧的 parent 的指针,表明它的 move 还没有完成。
类似地,file 的跨目录移动是在新目录下复制一个新文件,再把老文件删掉。注意这里的复制只是 file 对象本身,底下的 block 仍然是复用的,不会有数据移动。
因为缺乏跨 shard 的事务,上述操作很容易产生 race。
想象目录 d 的名为 f1 的文件被 rename 为 f2。同时有人又在 d 下面创建了新的 f1 文件。
这里 rename 的操作顺序为:
- R1:在 name layer 的 shard(d) 获得 f1 的 fid
- R2:在 file layer 的 shard(fid) 将 f2 添加为 fid 的另一个 owner
- R3:在 name layer 的 shard(d) 创建 f2->fid 的映射,并删除 f1->fid 的映射。
create 的操作顺序为:
- C1:在 file layer 的 shard(fid_new) 创建新文件
- C2:在 name layer 的 shard(d) 创建 f1->fid_new 的映射,并删除 f1->fid 的映射。
假设执行顺序为 R1-C1-C2-R3,R3 就容易把新创建的 f1->fid_new 的映射给误删除。因此这里一定要用单 shard 事务,确保 R3 只会在 f1->fid 时执行。
Client Library
Client lib 可以直接与 metadata server 和 chunk store 通信,以 chunk 为粒度读写数据,这也是 Tectonic 支持的最小粒度。
另外 client lib 直接负责 replication 和 RS-encode。
Single-writer semantics for simple, optimizable writes
Tectonic 限制每个文件同时只能有一个 writer,从而省掉了同步多个 writer 的负担。client 也因此可以并行写多个 chunk 以完成 replication。需要多 writer 语义的 tenant 可以在 Tectonic 之上自行实现同步。
Tectonic 通过 write token 来保证单 writer。每次 append open file 时会生成一个 token 记在 file metadata 中,之后每次 append block 都要带上正确的 token 才能修改 file metadata。如果有人再次 append open 这个 file,它的 token 会覆盖旧的 token,旧 writer 因此就会 append fail,保证了单 writer。新的 writer 会封存所有上个 writer 打开的 block,避免旧 writer 继续修改这些 block。
Background Services
Background service 负责维护不同 layer 间的一致性、修复数据丢失、平衡节点间的数据分布、处理 rack 空间满等问题,以及生成 filesystem 的各种统计信息。
Copysets at scale
Copyset 是包含一份数据的所有 copy 的磁盘的 set,比如 RS(10, 4) 的 copyset 就是 14 块磁盘。如果任意选择磁盘组成 copyset,当集群规模变大时,集群抵御数据丢失的能力就会非常差:3 副本下同时挂 3 块盘几乎必然有 block 丢失全部 chunk。
因此通常大规模集群都会显式将磁盘/节点分成若干个 copyset 来避免数据丢失。但反过来,copyset 太少的话,每块磁盘对应的 peer 比较少,磁盘损坏就会给 peer 造成过大的重建压力。
Tectonic 的 block layer 和 rebalancer 会维护一个固定数量的 copyset,从而在维护成本和数据丢失风险上达到平衡。具体来说,它会在内存中维护 100 个所有磁盘的排列。每当有新 block 时,Tectonic 会根据 block id 选择一个排列,再从中选择连续的若干块磁盘组成一个 copyset。
rebalancer 会尽量保证某个 block 的 chunk 位于它所属的排列中(因为 copyset 可能随着磁盘加减而改变)。
Multitenancy
挑战:
- 将共享资源公平地分配给每个租户。
- 能像在专属系统中一样优化租户的性能。
Sharing Resources Effectively
- 提供近似(加权)公平的资源共享与性能隔离。
- 应用间弹性迁移资源,从而保持高资源利用率。
- 识别延时敏感的请求并避免这类请求被大请求阻塞。
Types of resources
- 非临时的
- 临时的
Storage capacity is non-ephemeral. Most importantly, once allocated to a tenant, it cannot be given to another tenant. Each tenant gets a predefined capacity quota with strict isolation.
存储容量是非临时的,一旦分配给一个租户,就不能再分配给另一个租户,从而保证严格的隔离。
需求时刻在变,且资源分配也可以实时改变的资源就是临时资源:
- IOPS
- metadata 的查询 quota
Distributing ephemeral resources among and within tenants
租户作为临时资源管理的粒度太粗了,但应用又太细了。
Tectonic 中因此使用了应用组作为资源管理的单位,称为 TrafficGroup。相同 TrafficGroup 中的应用有着类似的资源和延时要求。Tectonic 支持每个集群有约 50 个 TrafficGroup。每个 TrafficGroup 从属于一个 TrafficClass,后者可以是金、银、铜,分别对应延时敏感、普通、后台应用。空闲资源会在租户内以 TrafficClass 作为优先级分配。
Tectonic 会按份额将资源分配给租户,租户内资源再按 TrafficGroup 和 TrafficClass 分配。空闲资源会先分配给同租户的其它 TrafficGroup,再考虑分配给其它租户。当一个 TrafficGroup 申请来自另一个 TrafficGroup 的资源时,这次分配对应的 TrafficClass 取两者中优先级低的那个。
Enforcing global resource sharing
client 端的流控使用了一种高性能、准实时的分布式 counter 来记录最近一个很短的时间窗口内每个租户和 TrafficGroup 中每种资源的需求量。这里用到了一种漏斗算法的变种。将流控做到 client 端好处是可以避免 client 发出多余的请求。
Enforcing local resource sharing
metadata 和 storage 节点本地会使用加权的循环调度器(weighted-round-robin scheduler),它会在某个 TrafficGroup 资源用超之后跳过这个 TrafficGroup 的请求。
storage 节点需要保证小 IO 请求不会受到大 IO 请求的影响而导致延时增加:
- WRR 调度器提供了一种贪心优化:低优先级的 TrafficClass 的请求可能会抢占高优先级的 TrafficClass 的请求,前提是后者离 deadline 还很远。
- 控制每块磁盘上发出的非最高优先级的 IO 请求数量。只要有最高优先级的 IO 请求在,超过阈值的非最优先请求就会被挡住。
- 如果有最高优先级 IO 请求排队时间过长,后续所有非最高优先的请求都会被挡住。
CloudJump 有类似上面 2、3 的调度算法
Multitenant Access Control
Tectonic 使用基于 token 的鉴权方式,有一个 authorization service 为每个顶层请求(如 open file)生成一个 token,用于请求下一层。这样每层都需要生成一个 token 来通过下一层的鉴权。整个鉴权过程是全内存的,只消耗若干个微秒。
Tenant-Specific Optimizations
Tectonic 支持约十个租户共享使用一个文件系统,两种机制使租户级别的优化成为可能:
- client 可以控制绝大多数应用与 Tectonic 的交互。
- client 端每个请求都可以单独配置。
Data Warehouse Write Optimizations
数仓中文件只有在写完之后才对用户可见,且整个生命期不可修改。于是应用就可以在本地按 block buffer 写。
Full-block, RS-encoded asynchronous writes for space, IO, and network efficiency
这种方式也允许 block 直接以 RS-encode 方式写入,从而节省存储空间、网络带宽和磁盘 IO。这种『一次写成多次读』的模式也允许应用并行写一个文件的不同 block。
Hedged quorum writes to improve tail latency
与常见的将 chunk 发送给 N 个节点不同,Tectonic 会两阶段写:先发送 reservation 请求给各个节点,申请资源,再将 chunk 发给前 N 个节点。这样能避免将数据发给肯定会拒绝的节点。
例如在写 RS(9, 6) 数据时,Tectonic 会发送 reservation 请求给 19 个节点,再将数据真正发给响应的前 15 个节点。
这种方式在集群负载高时尤其有用。
Blob Storage Optimizations
Tectonic 会将多个 blob 以 log-structured 形式写到一个文件中,从而降低管理 blob metadata 的压力。通常 blob 会远小于一个 block 大小,为了保证低延时,blob 会使用多副本形式写入(相比 RS 编码需要写完一个完整 block),从而能支持 read-after-write 语义。缺点是空间占用多于 RS 编码。
Consistent partial block appends for low latency.
Tectonic 多副本写入 blob 时只需要达到 quorum 即可返回,这会短时间内降低持久可靠性但问题不大:block 很快就会再被 RS 编码,而且 blob 还会再写到另一个 datacenter。
block 只能由创建它的 writer 进行 append。Tectonic 会在每笔 append 完成后将新的 block size 和 checksum commit 到 block metadata 中,再返回给调用者。
这种设计保证了 read-after-write 级别的一致性:write 返回之后 read 就可以读到最新的 size S。单一 appender 则极大降低了保持一致性的难度。
Reencoding blocks for storage efficiency.
client 会在每个 block seal 之后再将其转写为 RS 编码。相比在 append 时直接以 RS 编码写入,这种设计 IO 效率更高,每个 block 只需要在多个节点上分别写一笔。
Tectonic in Production
优化:
- 不同租户共享一个集群使得 Tectonic 可以在租户间共享资源,如 blob 富余的磁盘带宽可以用于承接数仓存储负载的峰值。
- 数仓任务经常会集中访问名字接近的目录,如果 range 分区的话就容易产生热点。hash 分区就没有这个隐患。
- 同样地,如果相同目录的文件位于相同 shard,这个 shard 成为热点的可能性就非常大,hash 分区再次胜出。
- Tectonic 的 list api 会同时返回文件名和 id,应用随后可以直接用 id 来访问文件,避免再次通过 Name layer。
- 数据在 RS 编码的时候既可以水平连续切 block,也可以竖直按 stripe 切 block。Tectonic 主要用连续的 RS 编码,这样大多数读请求都小于一个 chunk 的大小,就只需要一次 IO,而不像 stripe 那样每次读都要重建。在存储节点过载,直接读失败的时候会触发重建读。但这就容易造成连续的失败、重建,称为重建风暴。一种解法是使用 striping RS 编码,这样所有读都是重建读(这样真的算解决吗?),但缺点是所有读的性能都受到影响了。Tectonic 因此仍然用连续 RS 编码,但限制重建读的比例不超过 10%。
- 相比通过 proxy 中转,client 直接访问存储节点无论在网络还是在硬件资源效率上都更优,减少了每秒若干 TB 的一跳。但直连并不适合于跨 datacenter 的访问,此时 Tectonic 会将请求转发给与存储节点位于相同集群的无状态的 proxy。
Tradeoffs:
- 数仓应用在迁移到 Tectonic 后 metadata 的访问延时增加了。
- Tectonic 不支持递归 list dir,因为需要访问多个 shard。同样地 Tectonic 也不支持 du,统计信息会定期按目录聚合生成,但这就意味着不实时。
Lessons:
- 微服务架构允许 Tectonic 渐进地实现高扩展性。
- 一开始的架构将 metadata block 合并为 RS 编码的 chunk,显著减少了 metadata 的体积,但也显著削弱了容错性,因为少量节点的失败就会影响 metadata 的可用性。另外节点数的减少也阻碍了 quorum 写等优化的可能性。
- 一开始的架构没有区分 name 和 file layer,加剧了 metadata 热点。
- 规模上去之后内存错误变得常见。Tectonic 因此会在进程边界内和边界之间校验 checksum(开销还挺大的)。
Tectonic 的一个核心理念就是分离关注点(concern)。在内部,Tectonic 致力于让每一层专注于一些少量但集中的职责上(例如存储节点只感知 chunk,不感知 block 和 file)。Tectonic 自身在整个存储基础设施中的角色也是这种哲学的延伸:Tectonic 只专注于提供单个 datacenter 的容错。