原文:InfiniFS: An Efficient Metadata Service for Large-Scale Distributed Filesystems
TL;DR
InfiniFS 针对的是如何实现超大规模的单一分布式文件系统,目标上有些类似于 Facebook 的 Tectonic。但 InfiniFS 仍然是比较正统的、遵守 POSIX 语义的 fs,而 Tectonic 则是 HDFS 的升级版,目的是解决 Facebook 自身业务遇到的实际问题。
InfiniFS 看上去是 LocoFS 的后继,延续了 LocoFS 将 metadata 分成两部分的设计(但针对所有 inode 而不只是 f-inode)。另外 InfiniFS 还从 HopsFS 借鉴了并发 load inode。除此之外 InfiniFS 还有如下独特设计:
- client 端可以通过 hash 预测 inode id。结合并发 load inode,可以有效降低 network trip。
- client 与 metadata server 共同维护的一致性 cache。
- 单独的 rename coordinator。
整体看下来感觉 InfiniFS 的完成度还是比较高的,很实用,可能和有阿里云的前同事参与有比较大的关系。
Background
超大文件系统的挑战:
- data partitioning 难以兼顾良好的局部性和负载均衡性。
- 相近的文件/目录经常被集中访问,造成热点。
- 如果 hash partition,则分散了热点,但降低了局部性,同样的操作(如 path resolution/list dir)涉及更多节点。
- 如果以子树为单位 partition,则与之相反。
- 路径深度变大,path resolution 延时增加。
- Trivial 的按 dir id partition(Tectonic 再次出镜) 会导致长度为 N 的路径查找需要经历 N-1 个 trip。
- client 端 cache 的一致性维护负担加大。
- lease 机制(如 LocoFS)会导致越接近 root 的节点被 renew 的频率越高,无形中制造了热点。
在 metadata server 本身分布式之后,lease 维护代价也会变高。
- lease 机制(如 LocoFS)会导致越接近 root 的节点被 renew 的频率越高,无形中制造了热点。
但超大文件系统的好处:
- 全局 namespace 允许全局数据共享。
- 资源利用率高(Tectonic 也有讲)(集中力量办大事)。
- 避免了跨系统操作,降低了复杂度。
下图是生产环境采集到的操作数量统计(很有用):

- File 操作占了 95.8%。
- readdir 占了 93.3% 的目录操作。
- dir rename 和 set_permission 非常罕见。
Design and Implementation
Overview
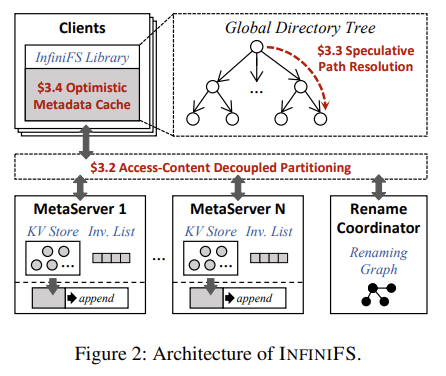
InfiniFS 有多个 metadata server,分别服务不同的 metadata partition。另外有一个全局唯一的 rename coordinator,处理 dir rename 与 set_permission。
Access-Content Decoupled Partitioning
类似于 LocoFS,但区别在于:前者将 f-inode 分成了 access 和 content 两部分,而 InfiniFS 则是将所有 inode 分成了 access 和 content 两部分。

其中 access 按 parent id partition,而 content 则按自身 id partition。这样每个 inode 的 access 就会与其 parent 的 content 分在相同的 server 上。
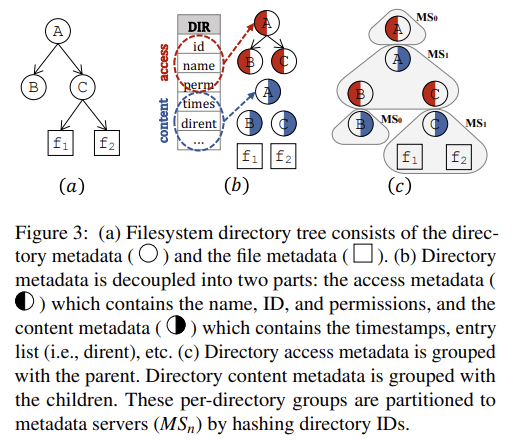
这样 create/delete/readdir 等操作就只需要访问一个节点(它们的特点是需要 parent 的 content 和 child 的 access)。由此 InfiniFS 既分散了热点,又保证了一定的局部性。
注意 path resolution 仍然需要经历 N-1 个节点。
Speculative Path Resolution
Predictable Directory ID
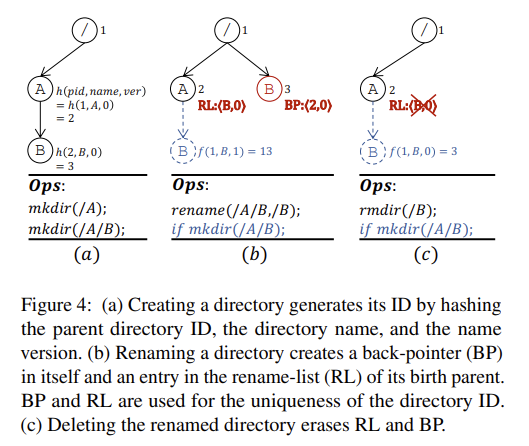
InfiniFS 使用了一种 hash 算 inode id 的方法:id = hash(parent_id, name, name_version),其中 name_version 是一个由 parent 维护的 counter,用来保证 id 的唯一性。
规则:
- 每个 dir 维护一个 rename list(RL),其中每个元素都是
(name, version),且 version 各不相同。初始 dir 的 name_version 为 0。此时 RL 为空。 - 每个 dir 在被 rename 之后,会在自身 inode 中记录一个 back pointer(BP),指向它被创建时的 parent,和自己被第一次 rename 的时候的 name_version。
- 每当有 rename 发生,所在的 dir 的 name_version 就增加。
- 每当有 id 冲突,name version 也增加。
- 存在 BP 的 dir 在被删除后,通过它的 BP 将 RL 中对应项删掉,它创建时的 dir 的 name_version 也可能因此减小。
- 某个 dir 被删除时,它对应的 RL 会直到变空才删除。
这些规则保证了:
- id 唯一性:通过 name_version 处理 hash 冲突。
- client 大概率可以直接根据 path 计算出每个 inode id。
- 被 rename 的 dir 不需要更换 id(后续在它的 birth dir 创建的相同 name 的 child 不会有相同的 name_version)。
同时我们知道 dir rename 的概率是非常低的,因此 name version 的维护开销也预期非常低。
但 name version 如果保持单调增的话,也有好处,就是一个 id 几乎永远不会被重用。当然考虑到不是 100% 保证,意义不那么大。
Parallel Path Resolution
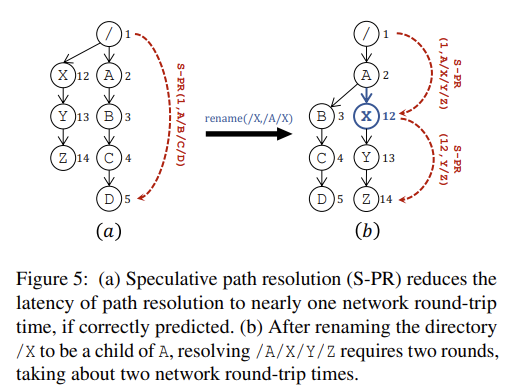
直接参考 HopsFS
Optimistic Access Metadata Cache
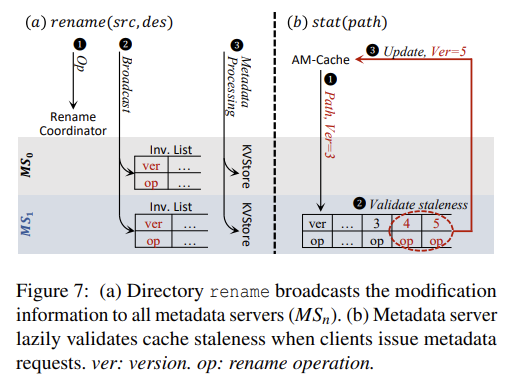
这块要先讲 InfiniFS 中 dir rename 的实现。
InfiniFS 中会有全局唯一的 rename coordinator 负责所有的 dir rename,过程如下:
- 检查 rename 之间不会冲突(经典的 rename 造成孤儿 entry)。之后为每个 rename op 赋一个单调增的 version number。
- 锁住对应的 dir,确保 rename 期间不会有请求访问对应的子树。
- 广播 rename,invalidate 所有相关的 cache。
- 真正执行 rename。
这里的广播是指向所有 metaserver 广播。每个 metaserver 会本地记录所有 rename op,但注意 metaserver 本身是没有 cache 的。
client 会在 cache 中记录每个 inode 对应的 version number,之后与 metaserver 通信时也会带上这个 version。metaserver 如果发现对应的 inode 发生过 rename,则会将 client 发来的 version 之后所有的相关 rename 都返回给 client。
这样通过 version number,我们就可以保证 client 总是会看到一致的 cache,但同时又不需要同步 invalidate。
当然上面过程也要求 rename coordinator 与 metaserver 都要记录 WAL 等信息到本地磁盘上。