原文:HopsFS: Scaling Hierarchical File System Metadata Using NewSQL Databases
TL;DR
HopsFS 目标是成为下一代 HDFS,其核心改进是使用一个分布式的 NewSQL 系统(NDB)替代了 HDFS 原本的单节点 in-memory metadata management。
亮点:
- 展示了如何使用分离的存储系统来管理 metadata。
- 仔细设计 schema 以缓解分布式事务对性能的影响。
- 并行 load inode。
NDB:
- 可以指定 partition 规则。
- 执行事务时可以根据 hint 选择最多数据所在的 node 作为 coordinator 从而降低跨机流量。
- 只支持 read-committed,但支持行级别锁。
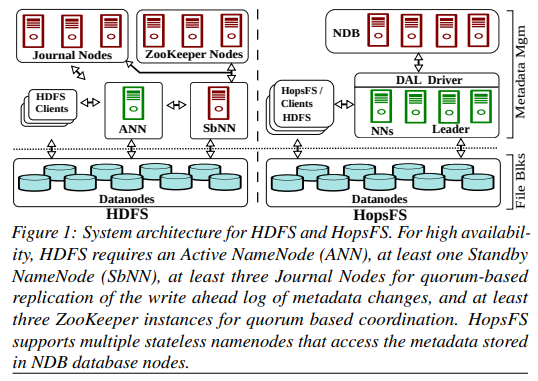
HopsFS 中有多个 namenode,其中会选出一个 leader,但所有 namenode 都可以执行 metadata 操作。
HopsFS 的 metadata partition 规则:
- inode 根据 parent id partition。
- file content metadata 根据 file id partition。
file content metadata 和 file inode 使用不同的 partition 规则,这样 listdir + open 可能会相对低效。
这种设计下越靠近 root 的 inode 越热,为了分散热点:
- root 默认 immutable,因此可以到处 cache。
- 允许前几级目录(默认 2)根据自身 name(而不是 parent id)hash partition,这样分散压力。层级越多,热点越不明显,但 rename 和 ls 的性能下降越厉害。
NDB 只支持 read-committed,但作为一个 fs,HopsFS 需要提供 serializability,因此需要结合行锁进行操作。为了避免死锁:
- 规定所有锁的获取按固定顺序,即在目录树中从左向右广度优先。
- 所有锁必须在事务开始前确定是读锁还是写锁,避免过程中锁升级导致的死锁。
HopsFS 中 path resolution 并不一开始就在事务中,而是先以 read-committed 拿到前面所有部分,直到最后一部分才需要上锁(某些情况下也要锁住 parent)
过程中如果有多个祖先节点被不同的事务修改,HopsFS 中可能看到不一致的状态。但 POSIX 没有规定这种情况下该保证什么样的一致性,因此也没问题。比如 create /a/b/c/d 的时候有人 mv /a /b,mv /a/b /a/c,那么 create 看到的 /a/b/c/d 可能实际上是 /b/b/c/d 或者 /a/c/c/d 或者 /b/c/c/d,但总归文件会被创建在 d 下面。
HopsFS 自身会维护一个 hierarchical lock,即锁某个节点也意味着锁住对应的子树。否则无法保证 serializability。
在锁住子树之后,HopsFS 还需要确保子树中没有操作正在进行,方法是对子树中每个节点加锁再解锁。
操作有点重……
事务过程中如果有 namenode 宕机,它已经加过的锁就需要由别的 namenode 后续清除,方法是查看锁的 owner 是否还存活(类似于 percolator)。
此外,事务 commit 阶段写 NDB 的时候即使中途失败,HopsFS 也要保证数据本身是一致的。看上去 NDB 没有 rollback 机制,因此 HopsFS 需要仔细设计操作顺序,比如 remove 子树需要从底向上 post-order 执行,这样保证了结果总是一致的。
最后是 HopsFS 的一个亮点:并行 load inode。
HopsFS 中 client 会缓存每个 path component 对应的 inode。当 resolve path 的时候,HopsFS 会并发拿 cache 中的每个 inode id 去 load,如果遇到 cache miss,再退化为递归式的 path resolution。这样在 fast path 下可以将 network trip 从 N 降到 1。只有 remove 和 rename 会使得 cache 失效。实际场景下退化的概率不到 2%。