TL;DR
TiFlash 是 MPP + 列存的 HTAP 引擎,这篇主要介绍它的执行器的线程模型。
TiFlash 的执行器目前使用了一种比较粗犷的多线程模型(继承自较早版本的 ClickHouse):
- 每个任务(MPPTask)会独立地创建一组线程,任务间不会共享线程。
- 算子间使用 push 模型。
- 通过特定算子控制不同阶段的并发:
UnionBlockInputStreamSharedQueryBlockInputStreamParallelAggregatingBlockInputStreamCreatingSetsBlockInputStream
Exchange会单独创建线程与 gRPC 交互。
本文使用的 sql:
1 | SELECT t1.a, sum(t2.c) |
背景知识
MPP
MPP 不是本文重点,点到为止。
下图为两节点上的 MPP plan 结构,可以看到它分为两个 stage,各有 2 个 MPP task:
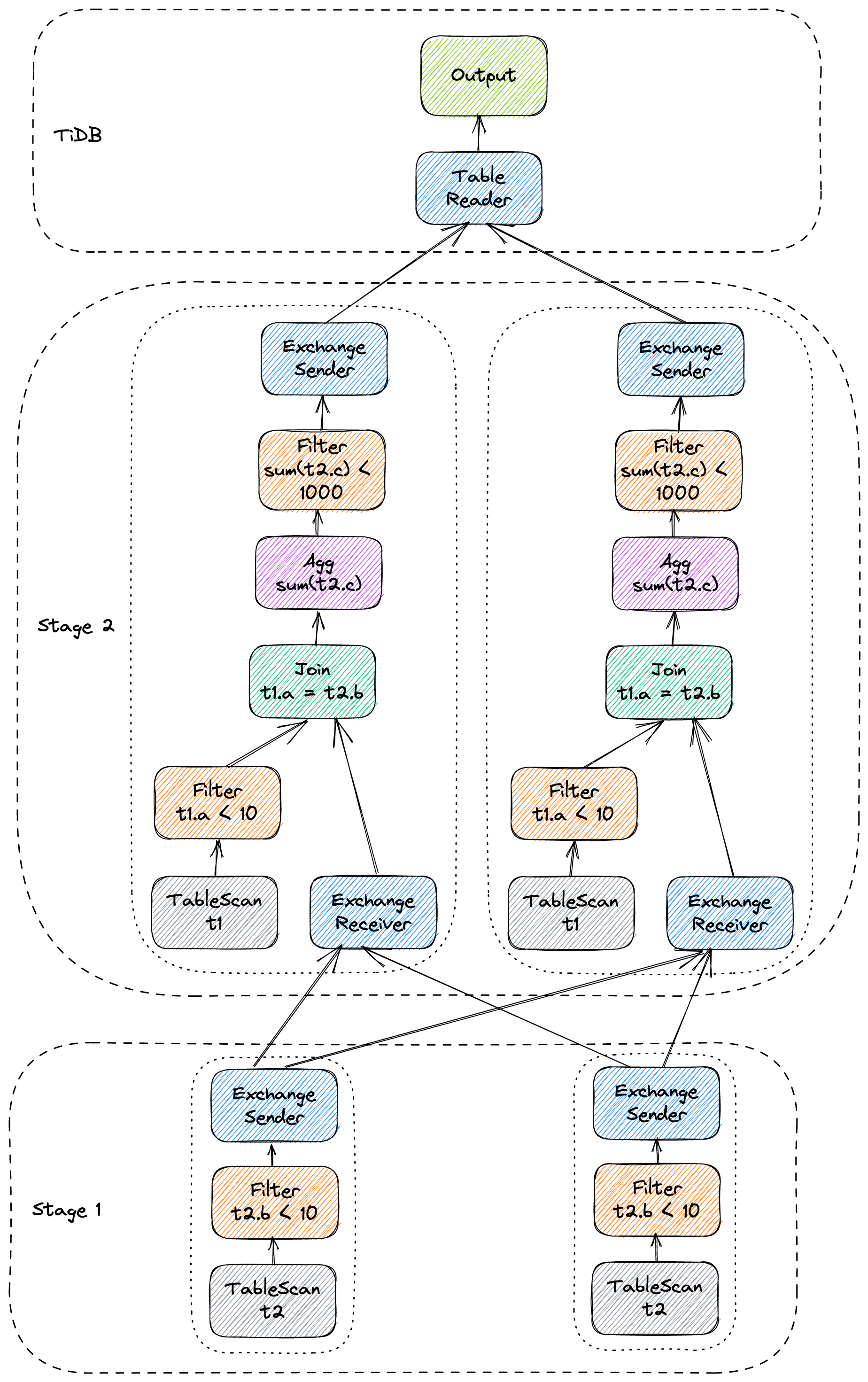
TiFlash 的 MPP 的入口在 TiDB。
TiDB optimizer 会根据规则与 cost 决定为这条 query 生成 MPP plan。每个 MPP plan 会被切分为多个 stage,每个 stage 则会实例化为若干个 MPP task。不同的 MPP task 之间通过 Exchange 算子进行通信。TiDB 与 root stage(上图中的 stage 2)之间也通过 Exchange 进行通信。
Exchange 算子是由 receiver 端主动建立连接,之后 sender 端会源源不断地将数据推送到 receiver 端。
算子
下图为 stage 2 的 MPP task 内部执行树(并发为 3):
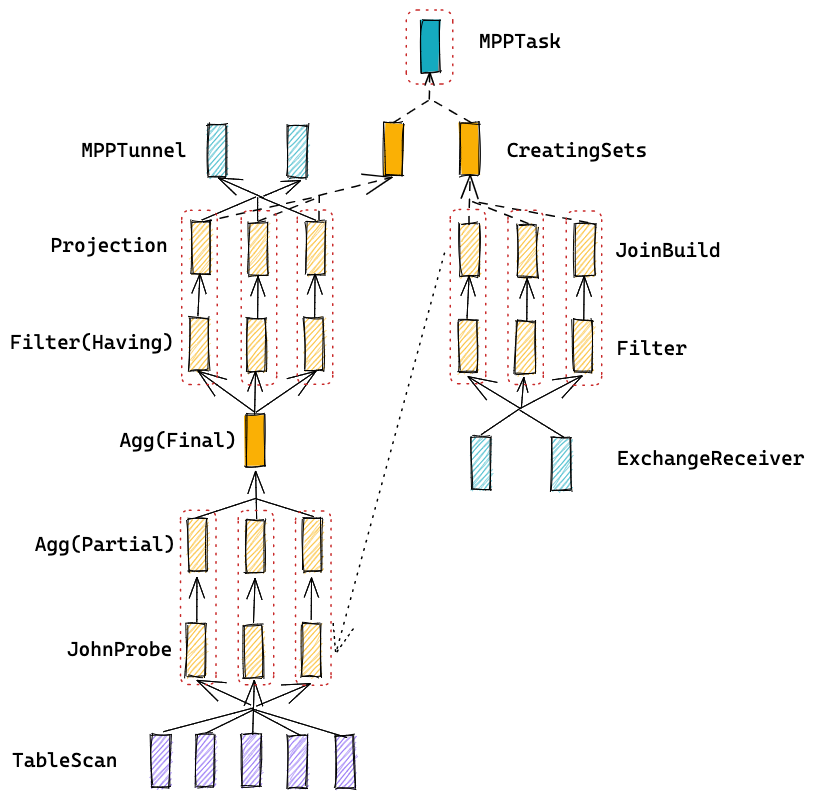
TiFlash 使用了类似于 volcano 的 pull 模型,执行流是由一个个 IBlockInputStream(下文简称 InputStream)组成的,可以认为它们就是 TiFlash 的算子。每个 InputStream) 支持以下基本接口:
- readPrefix:类似于 open。
- read:类似于 next。
- readSuffix:类似于 close。
大多数 InputStream 都只能被一个线程访问。为了能利用上多核,我们需要在执行流中显式插入几种特定的 InputStream 以实现并发:
UnionBlockInputStream:实现 1:N 的并发,将 N 个 InputStream 的输出合并为一个流。SharedQueryBlockInputStream:实现 N:1 的并发,将 1 个 InputStream 的输出分为 N 个流使用。ParallelAggregatingBlockInputStream:两阶段聚合,partial 阶段分别在 N 个线程构建 HashTable,merge 阶段则单线程或并发将 N 个 HashTable 合并起来,对外输出一个流。CreatingSetsBlockInputStream:接受一个数据 InputStream 和代表 JoinBuild 的若干个 Subquery,并发启动这些 Subquery,并等待它们执行结束之后再开始启动数据 InputStream。
上图中:
- 每个小长方形代表一个 InputStream。
- 每个虚线框代表一个线程。
- 实线代表数据流向。
- 虚线代表控制流。
(图中省略了 RPC 相关的线程)
可以通过 InterpreterDAG::execute 进一步了解 TiFlash 构建执行树的细节。
正文
为什么要用多线程模型
TiFlash 的类 volcano 执行过程中会存在大量阻塞。
如果我们使用线程池,就会遇到以下问题:
阻塞的算子会占用线程资源,整体资源利用率上不去。
线程资源无法令一个 task 的所有 job 同时运行,有死锁风险。
有两类死锁风险:
- 一个 task 内部。假设一台机器有 40 个线程,我们有 40 个 JoinBuild job 和 40 个 JoinProbe job,则显然这些 job 没办法一次运行完成。假如不幸发生了,我们没有保证这些 job 按依赖顺序调度(比如简单地令所有算子同时运行),则可能出现以下场景:40 个 JoinProbe job 占据了所有线程,等待着 JoinBuild 完成,但后者永远无法得到可用线程。
- 多个 task 之间。假设有两台机器,A 服务 task1 和 task2,B 服务 task3 和 task 4。task1 阻塞在向 task3 发送数据,因此导致 task2 无法执行;task4 阻塞在向 task2 发送数据,因此导致 task3 无法执行。由此 4 个 task 都无法执行。
而简单地令每个 task 各自创建线程,就避开了死锁和资源利用率的问题。但这种模式也有问题:
- 并发过高时,线程太多,最终会到达 OS 的限制。
- 这种频繁创建销毁线程的模式会带来额外的性能损耗(见下节)。另外对于大量依赖 thread-local 的基础库(如 jemalloc)不太友好。
你知道 TiFlash 有多努力吗
TiFlash 在 6.0 版本中引入了三个 feature 以改善线程模型:
- 弹性线程池,在 task 间复用线程以避免创建销毁线程的开销。注意它不同于常见的固定大小的线程池,弹性线程池在负载满时一定会额外分配线程,以避免死锁。当然代价是弹性线程池仍然无法控制住线程数的上限。这项功能后面会有专门的文章介绍,这里只简单说下效果:在高并发短查询场景中,线程创建销毁的开销会成为明显瓶颈,导致平均 CPU 利用率只能维持在 50% 左右,而在打开弹性线程池之后,CPU 利用率可以基本稳定在接近 100%。
- Async gRPC,将 TiFlash 中用于 RPC 的线程数控制在接近常数个。其中 server 端实现得比较好,已经将 RPC 线程数控制在常数个了,但 client 端还差一些,目前只能控制为与 task 数量成正比,后续还可以进一步改进。
- 基于 min tso 的 local task 调度,在每台机器上根据 query 的 tso 按顺序进行调度,从而控制总体线程数,同时避免死锁。
这三项功能可以很大程度上改善 TiFlash 在高并发场景中的性能和稳定性。
如何让 TiFlash 用上线程池
为了能让 TiFlash 用上线程池,一种方案是将它的 pull 模型改为 push 模型。不再一启动就创建全部算子,而是将整个 task 划分为若干个 pipeline,每个 pipeline 只在有数据时触发 job 提交到线程池中。这样每个 job 都是纯计算的,不存在阻塞。
这种方案我印象中是在 morsel driven 之后逐渐普及开的,目前最新的 ClickHouse、StarRocks、DuckDB 等系统也都使用了类似的方式。
对于 TiFlash 而言,这就需要重构整个执行模型,风险还是比较高的。
另一种方案则可以在不改变执行模型的情况下使用固定大小的线程池:用协程。
在 push 模型中每个 pipeline 都需要做状态判断,把等待数据的阻塞转换为异步操作。常见的转换方法可以用 callback,也可以依赖于上下游算子轮询。通常我们可以假设一个 query 执行过程中算子是不变的,因此每个算子的上下游都是固定的,这样轮询状态也是可以接受的。
而使用协程就相当于自动将阻塞操作给异步化了:被阻塞的协程自动挂起,等待被唤醒,物理线程则调度执行下个可运行的协程。这样我们可以保留 pull 模型,继续使用同步代码,但不需要担心阻塞问题。
我们知道协程可以分为有栈协程(stackful coroutine)和无栈协程(stackless coroutine),通常认为前者因为需要为协程分配栈,内存开销大,另外协程间的切换成本也略高于后者。但在 OLAP 这个特定领域,尤其是在结合向量化之后,通常不会有大量协程,也不会有大量切换。此时有栈协程的编程简单、侵入性低的优势就体现出来了。
我在去年 10 月尝试向 TiFlash 中引入 boost::fiber(一个有栈协程库),大概也只用了两个晚上就得到了一个基本可用的版本(需要禁掉部分依赖于 thread-local 的特性)。
这里是前段时间基于 6.0 重新 patch 的基于 boost::fiber 的 TiFlash,可能还有点小问题。可以看到我只做了几项改动:
- 将 C++ 标准库的
std::mutex、std::condition_variable等同步原语替换为 boost::fiber 对应的类型。 - 在特定位置(实际就是每个线程的 entry function)显式插入
yield,以避免一个协程消耗过多 CPU 时间片。 - 在 TableScan 上面插入一个
IOAdapterBlockInputStream,这样 TableScan 仍然在 OS 线程中执行,但与上游算子之间通过boost::fibers::buffered_channel通信。
使用 boost::fiber 的好处很明显,是用了非常小的改动换来了实际控制住了线程数(如果有时间将 IO 也异步化,那么 TableScan 也可以在协程中执行)。它的缺点是:
- 需要仔细 review 各种同步原语的使用,尤其是三方库中隐式使用的。如果不小心在协程中使用了会导致 OS 线程阻塞的函数,则整个系统的执行效率会大受影响,甚至还有死锁的风险。这点在之前阿里云 pangu 的异步化改造过程中曾经多次出现过,造成了非常坏的后果。
- 相比之前直接使用 OS 线程,使用 boost::fiber 之后 debug 难度极剧增加:没办法通过 pstack/gdb 看线程栈了。这样一旦出现了逻辑死锁,某个协程永远无法执行,我们很难在系统之外找到这个协程。但这也是所有异步化系统的通病,通常要么深度改造协程库,允许注入一些业务逻辑的标识;要么业务方自己引入一些 tracing 机制。
当然因为种种原因,这个分支在去年 10 月开发测试完成后,并没有再进一步。鉴于我即将离开 TiFlash,协程这条路应该在相当长一段时间不会出现在 TiFlash 的主干代码中。如果有朋友对我上面的分支感兴趣,欢迎评论、私信交流。