Chubby的第一个版本基于一个第三方可容错的商业数据库(下文称为3DB),它的replication有很多bug,并没有基于任何已有证明的算法,也无法证明其正确性。最终Chubby将3DB替换为了基于Paxos的实现。
作者在实现Paxos的过程中,发现这个工作并不trivial:
- 描述Paxos的伪代码只要一页就够了,但作者的C++实现多达几千行。膨胀的原因是实际的生产系统需要的很多特性和优化是原paper中没有的。
- 社区习惯于证明篇幅短的算法(一页伪代码)的正确性,但其证明方法难以扩展到几千行代码的规模,导致作者必须使用不同的广域来证明其实现的正确。
- 容错算法只能处理一个精心选择的固定集合中的错误,而真实世界有着多得多的错误类型,包括了算法本身的错误、实现的错误、操作错误。
- 真实系统很少能有精确的spec,甚至在实现过程中还会修改spec,就需要实现本身具有可塑性,也许就会有实现“误解”了spec导致的错误。
这篇文章就在讲作者将Paxos从理论搬到实际的过程中的一些挑战。
Architecture Outline
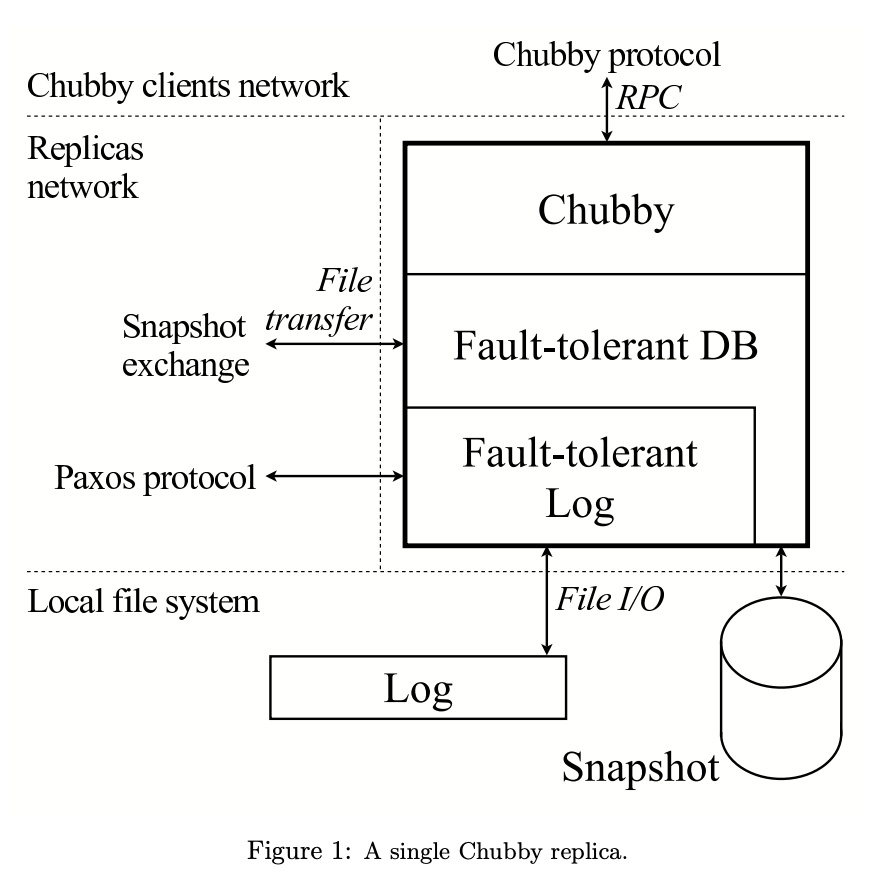
在Chubby的架构中,Paxos用来构建最底层的log,有意地与上层的DB分离,这样log层可以给其它系统复用。
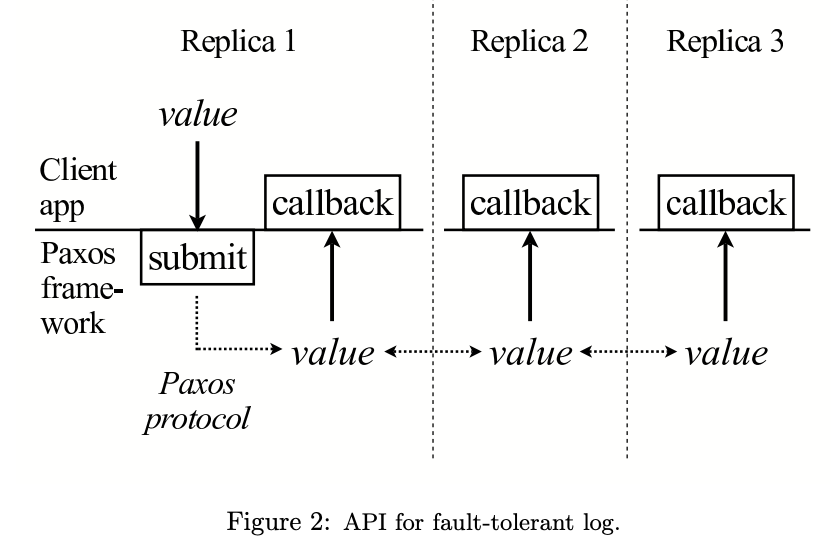
log层的API如上图。一旦一个值submit了,client在各个replica上设置的callback会被触发,并得知submit的值。
On Paxos
Paxos Basics
基本的Paxos算法包含三个阶段:
- 选出coordinator。
- coordinator选出一个值,将其包含进一个accept消息,广播给其它replica。其它replica可以回复acknowledge或reject。
- 一旦多数replica回复了acknowledge,共识达成,coordinator会广播一个commit消息。
有可能出现以下情况,多个replica都认为自己是coordinator,且选出不同的值。为了保证仍然能达成共识,有以下两种机制:
- 连续的coordinator之间有序。
- 限制每个coordinator对值的选择。
每个coordinator有自己的sequence number(或称term)来保证顺序。一个replica想要成为coordinator时,它需要产生一个大于已知所有sequence number的新number并广播包含这个number的propose消息,其它replica的回复称为promise(前面的阶段1)。
达成共识的值就不能再被修改。因此Paxos需要保证后续coordinator仍然选出相同的值,做法是replica的promise消息中包含它见过的最新的值和sequence number,新的coordinator会使用所有回复中最新的值。如果所有回复中都没有值,新coordinator才可以自由选择值。
Multi-Paxos
基本的Paxos算法只能选出一个值,当需要在一系列值上应用Paxos时,我们可以针对每个值单独运行一个Paxos实例,称为Multi-Paxos。
Multi-Paxos要求每个replica在本地持久化自己的状态,trivial的实现需要有5组同步写(propose、promise、accept、acknowledge、commit)。
一种常见的优化是将多个Paxos实例串起来,如coordinator没有变化则可以省略propose(不影响正确性,replica仍然可以试图成为coordinator)。因此Multi-Paxos中会有一个长时间的coordinator称为master,这样每个Paxos实例中每个replica只需要写一次盘,其中master是在发出accept之后,其它replica则是在回复acknowledge之前(上一轮的commit合并进下一轮的accept/acknowledge写)。
另一种优化是批量写,一轮Paxos处理多个值。
Algorithmic Challenges
实现Multi-Paxos需要很多特别的处理,一部分源自现实世界的复杂性(如磁盘错误、资源有限),一部分源自新的需求(如master lease)。这节介绍了一些需要加到Paxos算法中的机制。
Handle disk corruption
每个replica都要定期检查数据完整性。一旦数据损坏,replica就可能会食言(改变已经commit的决定),违背了Paxos的核心假设。
数据损坏包括了文件内容损坏和文件不可见。前者通过checksum解决(但检查不出文件状态回退,此时checksum正常)。后者需要与一个空的新replica区分开,做法是在GFS上做标记。
当replica发现磁盘损坏后,它会以一个无投票权的身份加入Paxos组,接着开始追数据,直到追到它开始这次追赶时的位置,再恢复为正常成员。这样保证了replica不会在状态丢失时做出食言的决定。
这种机制还允许下面这个优化:既然Paxos能处理磁盘错误,某些情况下可以省掉Paxos过程中的同步写(有点类似于HARBOR的思路)。
Master leases
在基本的Paxos算法中,读数据需要运行一个Paxos实例,以确保读到最新状态(其它replica已经选出了新的master)。
master lease的思路是master会维护自己的一个lease,只要lease不过期,在服务读请求时master就可以直接返回本地状态,而不用运行一遍完整的Paxos。
作者的实现是每个replica会在每轮Paxos中隐式授予master lease,在lease过期前拒绝掉其它replica想成为master的proposal。master端有一个比lease更短的timeout,会定期刷新lease。(完全依赖lease timeout可能有安全隐患,参见关于一致性协议和分布式锁)。
master lease还能避免出现两个replica反复争抢成为master的情况。另外Chubby中master还会定期运行一轮完整的Paxos来提升sequence number,进一步减小出现这种情况的概率。
另外replica也可以有lease(lease期间集群保证没有写请求?),这样它也可以服务读请求。
Epoch numbers
从Chubby的master开始服务写请求,到数据真正落盘,期间master可能已经丧失(过)身份了。解法是引入epoch number,所有写都变成了针对epoch的条件写(和sequence number的区别在于哪?)。
Group membership
成员变更本身可以通过一轮Paxos来实现,作者遇到的障碍是原paper中没有明确提到这一点,也没有给出正确性证明。(然而正确且高效的成员变更并不那么trivial)
Snapshots
Paxos的log在理论上是可以无限长的,需要有snapshot来避免这种情况。注意Paxos框架本身是与存储结构解耦的。
一种看起来很直接的实现是每个replica自己维护snapshot,完成snapshot后就通知Paxos清理掉无用的log,在恢复的时候使用最近的snapshot,之后再走正常的Paxos恢复流程。
但这种实现就需要保持log与snapshot这两种状态的一致,其中log完全在Paxos的控制中,但snapshot不是。以下是一些作者觉得有意思的点:
- snapshot需要有log的信息,称为snapshot handle。Chubby在handle中记录了Paxos的instance number(和sequence number的关系是?)和成员列表。
- snapshot过程中log不能停写,因此Chubby的snapshot过程分为三段,先记录snapshot handle,再开始生成snapshot(需要注意数据结构的并发访问),最后将snapshot handle告知给框架。
- snapshot可能失败,此时应用不会去通知框架。应用甚至可以同时生成多个snapshot。
- 追赶阶段,落后的replica可以直接使用其它replica的snapshot。领先的snapshot甚至可以为这次追赶生成一个snapshot。
- 需要有机制能定位snapshot,比如通过GFS。
Database transactions
Chubby实现了一种MultiOp,可以在条件满足时原子执行若干个操作。一个MultiOp包含三类元素:
- 一组guard,每个都是针对单个值的test,guard的值是所有test的与。
- 一组t_op,每个都是针对单个值的insert/delete/lookup,只有当guard为真时执行。
- 一组f_op,类似于t_op,只有当guard为假时执行。
Software Engineering
这部分主要讲工程上实现Paxos这样的共识算法需要注意什么。
第一个是算法要容易被正确表达,伪代码也行。作者发明了一种用于描述状态机的语言,可以翻译为C++代码。这样算法的检验就容易多了,只需要关注spec本身,以及翻译过程是否正确。检验过的spec就可以用来做test。作者举了个例子,一开始Multi-Paxos不允许离开group的成员再加入,这样避免断断续续的错误。但后来发现这种情况比预想的要普遍得多,需要修改算法本身来支持重新加入。有了清晰的spec,整个修改只花了1个小时(test改了3天)。
第二个是要在运行期做一致性检查。比如master会定期将自己的checksum发给各个replica(加入log流?)。作者遇到过三次DB的不一致:
- 第一次是误操作。
- 第二次没找到合理解释,回放有问题的replica的log发现是没问题的,那可能是有硬件的bit翻转。
- 第三次怀疑是引入的其它代码的非法内存访问导致的。为此作者为checksum增加了一个DB做double check。
第三个是测试。Chubby从一开始就被设计为可测试的,之后积累了庞大的测试case。作者这里介绍了两种长时间随机操作的test,每个都可以运行在Safety(校验一致性,可以没进度)或Liveness(一致且有进度)模式。
第一个test针对log。它针对随机数量replica执行随机的操作序列,其中包括网络打满、消息延迟、超时、进程崩溃与恢复、文件损坏、交错调度等。随机数seed是保存好的,保证相同的操作序列可以得到相同的结果(单线程)。
第二个test测试Chubby在底层系统和硬件错误时的稳健性。
(类似于Chaos Engineering)
作者发现一个有意思的点,容错系统被设计为会自动掩盖问题,这给发现bug带来了困难。
第四个是并发。test很重要的特性是要能复现,就需要排除并发的干扰。但真实系统就是并发的,单线程的test无法测试真实系统。这种矛盾似乎没有好的解法。
Unexpected Failures
作者遇到的非预期的错误:
- 新的Chubby的线程数是旧Chubby的10倍,但上线后没有能处理更多请求,worker线程还会阻塞其它关键线程。在回滚过程中,因为文档不清晰,SRE的操作不正确,丢失了15小时的数据。
- 几个月后再次尝试升级Chubby时,因为没有清理掉上次升级留下的文件,升级又失败了,还因为使用了一个旧的snapshot,丢失了30分钟的数据。
- 接下来作者发现了replica在失去master身份又成为master后,之前的操作没有失败,与预期不符。之后引入了epoch number。
- 之后又通过runtime check发现了某个replica的checksum与其它replica不一致。
- 从旧Chubby到新的基于Paxos的Chubby的迁移脚本多次失败,其中一次的原因是软件包配置不对。
- Linux2.4内核的fsync有bug,会将其它文件的数据也刷下去,执行时间可能很长。workaround是让大文件的flush更频繁(每个chunk flush一次),牺牲大文件的写性能来保证log的写性能。
Summary and Open Problems
- Paxos算法与真实系统之间有着巨大的gap,工程师需要对协议做许多微小的扩展,而这导致了真实系统总是基于一个未经证明的协议。
- 社区还没有工具能让实现一个容错算法变得容易。
- 社区在test方面的关注不够。