TL;DR
F1是Google用于替换分库分表的MySQL的RDBMS系统。它在Spanner之上建立了一套关系模型,拥有Spanner的跨datacenter的同步replication能力。F1还开发了新的ORM模型,从而将同步geo-replication导致的延时隐藏了起来,保证了E2E延时在替换后没有上升。
Introduction
F1的设计目标:
- 可伸缩性,要能把扩容变得平凡、业务无感知。
- 可用性,无论是datacenter中断,还是正常维护、schema变更,都不能停止服务。
- 一致性,必须提供ACID的事务,保证数据不出错。
- 易用性,要满足用户对于一个RDBMS的预期,要支持完整的SQL查询、二级索引、ad-hoc查询。
F1建立在Spanner之上,在继承Spanner原有功能(极致规模、同步replication、强一致、有序)之外,F1还增加了以下特性:
- 分布式SQL查询,包括与外部数据源做join。
- 事务一致的二级索引。
- 异步schema变更,包括db重新组织(TODO)。
- 乐观事务。
- 自动记录和发布表变更历史。
F1的设计选择导致了常规读写延时上升,因此F1使用了以下技术来隐藏掉延时,从而提供了与之前MySQL方案差不多的E2E延时:
- 使用分级的表结构和嵌套数据类型,显式将数据聚焦起来,提高了数据局部性,减少了RPC数量。
- 重度使用batch、并行、异步读,并通过新的ORM来体现这些特点。
Basic Architecture
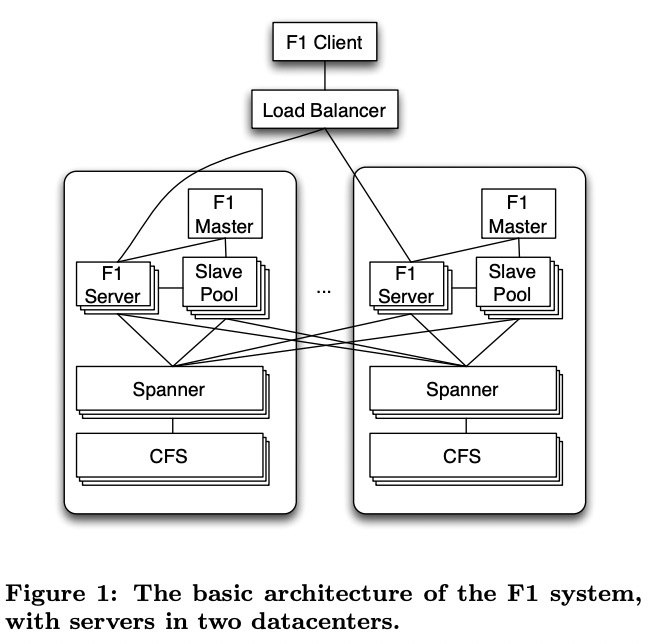
为了降低延时,F1 client和load balancer会优先选择离得最近的F1 server。
F1 server通常与对应的Spanner部署在相同datacenter中。但F1 server也可以访问其它datacenter的Spanner。Spanner的数据在CFS(Colossus File System)上,CFS是单datacenter的,因此Spanner不会访问其它datacenter的CFS。
F1 server通常是无状态的,除了client要执行悲观事务,此时F1 server会持有锁,client需要在事务期间保证与对应的F1 server的连接。
F1集群还会有slave pool来执行复杂的分布式query,这些机器由F1 master负责管理。
F1也支持将大规模的数据处理offload给MapReduce来执行,MapReduce会直接与Spanner通信获取数据,不需要再走一次F1。
因为Spanner的同步replication,一次commit的延时通常在50ms-150ms。
Spanner
Spanner是与F1一同开发的,负责底层的数据存储,包括一致性、cache、replication、容错、数据分区与移动、事务等。
Spanner中数据被分为若干个directory,每个directory至少有一个fragment。每个paxos group包含若干个fragment。
(细节略,见Spanner笔记)
Spanner提供了一个global safe timestamp,并保证不会有正在执行的事务的timestamp比它更小。gst通常落后当前时间5-10秒。小于gst的读可以由任意replica服务,也不会被正在执行的事务阻塞。
Data Model
Hierarchical Schema
逻辑上F1的表schema可以组织为树型结构。物理上F1会将子表与父表的行交织在一起,要求子表有一个foreign key是父表primary key的前缀(类似于Megastore)。比如Customer表的primary key是(CustomerId),它的一个子表Campaign的primary key是(CustomerId, CampaignId),再下层子表AdGroup的primary key是(CustomerId, CampaignId, AdGroupId)。root表的行称为root row,所有从属于某个root row的子表的行都与root row存储在Spanner的一个directory中。
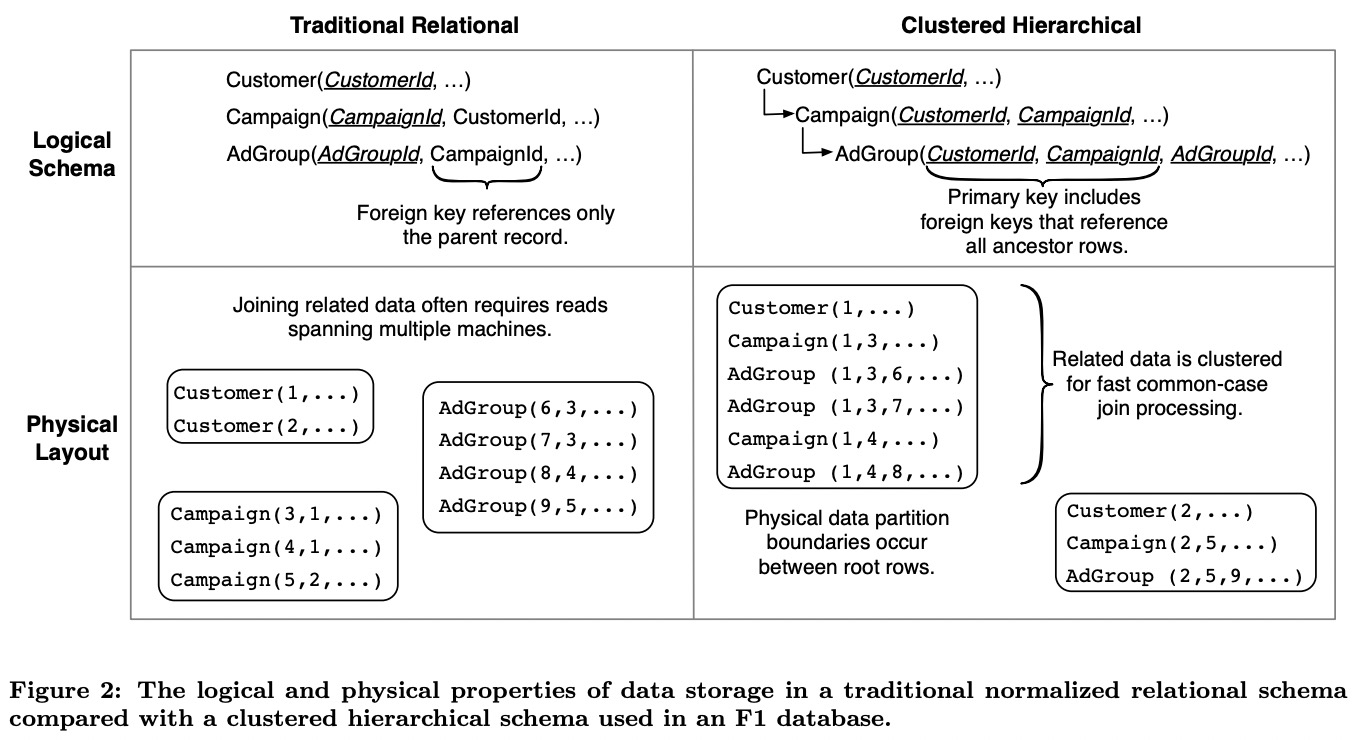
这种层级结构的好处:
- 将读某个root前缀下多个entity的操作由多次point query转为了一次range query。
- 可以用sorted join来处理两张子表间的join(相同primary key顺序),且不需要shuffle(都在一个directory中)。
这些性质能帮助F1缓解延时的上涨。
层级结构尤其对update有用:减少了涉及的paxos group数量,2PC数量大大降低,甚至可以避免2PC。
F1并不强制这种层级结构,平坦结构也是可以的。对于Ads而言,它的模式就是读写通常都以CustomerId为界限,这种层级结构有着非常明显的好处。
Protocol Buffers
F1支持数据格式为Protocol Buffers(保存为一个blob),且经常在每行父表数据对应的子表数据不多时,将子表替换为父表中的一个repeated字段,从而避免了多张表的管理开销与潜在的join开销。此外使用repeated字段常常要比用子表语义上更自然。
表可以将所有列分为几组,经常一起访问的在一起,不太修改的和经常修改的分开,不同列设置不同的读写权限,也可以并发写。使用更少的列能显著提升Spanner的性能,后者每列都有不少的开销(为什么?)。
Indexing
F1的index被单独保存为Spanner中的表,primary key是index自己的key加上主表的primary key。
F1中index分成了local和global两种。local index的key的前缀必须是root row的primary key。它类似于子表,也和root row保存在一个Spanner的directory。因此更新local index只需要增加少量开销。
global index是单独保存的,主表和global index的修改会涉及2PC,因此开销比较大。global index经常会有规模问题,主表的一次修改可能涉及很多index row的修改,导致2PC参与者数量非常多。因此F1中global index用得并不多,且写入时建议将事务拆小,避免2PC参与者过多。
Schema Changes
F1中所有schema change都是非阻塞的,非常有挑战性:
- F1的分布式规模非常大,一次schema change影响的节点特别多。
- 每个F1 server会在本地内存中缓存一份schema,难以原子修改所有缓存的schema。
- 过程中的query和事务不能停。
- schema change过程不能影响系统可用性和延时。
因此F1使用了异步schema change,在一段时间内逐步应用到所有F1 server上,隐含着两台F1 server可能同时使用不同的schema服务请求。
此时可能出现一种不兼容情况:A机器看到了主表增加一个索引,它在处理一个insert时同时向主表和索引表写了一行数据;随后的delete这行的请求发给了B机器,它没看到主表增加了索引,只删除了主表的数据,导致主表和索引表数据不一致。
为了避免这种不兼容情况出现,F1实现了以下schema change算法:
- 限制所有F1 server同时最多只能有两套schema。每个server使用lease来管理schema,lease过期后就不能再使用对应的schema。
- 将一次schema change分为若干步,每步前后都保证兼容。比如前面的例子中,F1先增加索引I,但限制它只能删除不能添加。随后再将I升级为可以执行全部写操作。之后启动一个MapRedcue任务回填历史数据。最后令I可以服务读。
Transaction
每个F1事务由若干次读和一次可选的写组成,这次写会自动提交整个事务。F1基于Spanner的事务实现了三种事务:
- Snapshot事务,使用固定的timestamp执行只读事务。如前面所述,通常Spanner的global safe timestamp会落后5-10秒。用户也可以自己选择timestamp,但太新的时间有被阻塞的风险。
- 悲观事务,直接映射为Spanner的事务。悲观事务会使用一种有状态的协议,负责处理请求的F1 server会持有锁。
- 乐观事务,它包含一个可以任意长的只读阶段(不持有锁)和一个非常短的写阶段(Spanner事务)。F1在读请求返回的每行数据中都隐含了这行上次修改时间,在最后的写阶段用于校验是否有冲突。
F1 client默认使用悲观事务。但乐观事务有以下好处:
- 可以容忍行为不端的client:读阶段不持有锁,写阶段持续时间短。
- 支持长时间的事务,比如等待用户交互响应,或单步调试。
- server端可以重试。
- server端可以failover,所有状态都在client端,可以用户无感知地切换到另一台server处理。
- 可以做speculative write,即先记录感兴趣的数据的timestamp,再用这些timestamp做一次尝试的写。
乐观事务也有一些缺陷:
- 有幻写,因为乐观事务是一种snapshot isolation,只能防已经有的数据被修改,不能防止新的数据插入。
- 高冲突时吞吐低。
Flexible Locking Granularity
F1默认的锁粒度是行级别,每行中有一个默认的lock列来控制这行的所有列。但用户也可以自己指定锁粒度,如一行有多个lock列来增加并发度。用户也可以使用父表的lock列控制子表的列,从而有意降低并发度。这种方式可以避免子表的幻写。
Change History
F1的首要设计目标就包含了自动记录change history。每个F1事务都会创建一个或多个ChangeBatch对象,其中包含了primary key和修改前后的数据。这些ChangeBatch对象会被写进单独的ChangeHistory表,作为被修改的root表的子表。如果一个事务修改了多个root行(甚至多张root表)下面的数据,每个root row都对应一个ChangeBatch,其中还会包含指向这个事务中其它行的指针,用来恢复完整的事务。
ChangeHistory表本身是可以用SQL查询的,且它与对应root表保存在一起的特性也使得记录history并不会增加Spanner写的参与者。
ChangeHistory支持pub-sub,可以用来实现change data capture(CDC),比如client可以用它来实现snapshot一致性的cache。
Client Design
Simplified ORM
F1实现了一套新的ORM系统,不使用任何join,不会隐式遍历记录。所有object的加载都是显式的,所有暴露的API都是异步的。这种设计依赖了F1 schema的两个特点:
- F1的一个DB中通常表会比其它RDBMS更少,client通常直接读出Protocol Buffers的数据。
- 层级结构使得读取一个object的所有children不需要join,只需要一次range query。
新的ORM系统写起来比之前的ORM系统要复杂一些,但更容易避免反模式,支持的规模更大,且因为避免了join,读取延时更稳定,不会因为涉及大型join而导致延时抖动得非常厉害。它的最小延时要比MySQL高,但平均延时差不多,延时长尾控制得比较好,只是平均延时的几倍而已。
SQL Interface
F1的query处理有以下关键性质:
- 既支持低延时的集中执行模式,又支持高并发的分布式模式。
- 所有数据都是远程读取的,重度使用batch以缓解网络延时。
- 所有输入数据和内部数据都可以任意分区,不太需要保证顺序。
- query过程中会经历许多基于hash的重分区步骤。
- 每个算子都是流式处理数据,并会尽快将输出发送给下游,最大化query过程中的流水线。
- 层级结构的表有着最优的访问模式。
- query的结果可以并行消费。
- 对结构化数据类型(Protocol Buffers)有着良好的支持。
- Spanner的snapshot一致性模式提供了全局一致的结果。
Central and Distributed Queries
F1有两种执行query的模式:
- 集中式模式会在一台F1 server上执行OLTP风格的短query。
- 分布式模式会在多台slave worker上执行,总是使用snapshot事务。
query优化器会启发式确定用哪种模式处理请求。
Distributed Query Example

对应的query:
1 | SELECT agcr.CampaignId, click.Region, cr.Language, SUM(click.Clicks) |
Remote Data
F1相比传统的RDBMS的一个区别在于它自己不存数据,所有数据都在Spanner上,因此请求处理的网络延时很高,而传统RDBMS主要是磁盘延时。这两者有着本质区别:网络延时可以通过batch或pipeline来缓解;磁盘延时通常是单点硬件资源争抢导致的,很难通过扩容来获得线性提升。Spanner的数据是存在CFS上的,本身就是很分散的,因此F1可以通过尽量并行化来获得接近线性的提升。
batch的一个例子发生在lookup join时,F1会聚合相同的lookup key,直到聚合的数据达到了50MB或者100K个不同的key时再开始lookup。lookup的结果会立即流式返回回来。
F1中的算子都被设计为流式处理,一有数据就输出,但这样就很难做保序等操作。尤其是这些算子自己处理也是高度并行化的,即使输入有序,并行之后也不再有序了,这样能保证最大的并行度,从而提高吞吐,降低延时。
Distributed Execution Overview
一个完整的query plan包含若干个plan part,每个plan part表示一组执行相同subplan的worker。这些plan part组成DAG,数据从叶子节点一直流向唯一的根节点。根节点本身是接受请求的F1 server,也是整个query执行的coordinator,它负解析query、分发subplan、执行最终的聚合、排序、过滤。
很多分布式DB会将多份有序数据按相同方式分片,可以下推很多算子给各个分片,省掉shuffle。但F1自己不管理数据,因此很难做这样的优化,尤其是这种优化还需要多次重排序。最终F1选择了只支持hash partition。近期的网络技术的发展也使得这种全hash partition变得实际了,几百台F1 server可以同时全速互相连接。它的缺点是F1的规模会受到交换机的资源限制,但目前还没遇到。
使用hash partition允许F1实现高效的分布式hash join和聚合算子。worker在处理hash join时,如果数据量比较大,可以将一部分hash table写到磁盘中,但不需要做checkpoint。
Hierarchical Table Joins
F1的层级结构数据允许用一个请求就执行完下面的join:
1 | SELECT * |
Spanner会交替返回父表与子表数据:
1 | Customer(3) |
读取过程中F1会使用一种类似于merge join的cluster join策略,它只需要每张表缓存一行数据,一个请求可以处理任意多张表,只要这些表沿着一条路径下降(同级只能有一张表,否则需要缓存不确定数量的行)。
当F1在join父表与多张同级子表时,它会先用cluster join完成父表与其中一张子表的join,再用其它join策略完成剩余部分。像lookup join之类的策略可以控制batch大小,避免结果集太大需要写到磁盘中。
Partitioned Consumers
为了避免coordinator本身成为数据输出的瓶颈,F1允许多个client使用一组endpoint消费同一个query的结果(比如MapRecuce)。但因为F1的流式处理,其中一个client慢了会拖慢其它client。一种未实现的优化策略是使用基于磁盘的buffer来解耦。
Queries with Protocol Buffers
这篇文章发表时F1还不支持解析一个PB对象的部分字段。
Deployment
略
Latency And Throughput
F1的读延时为5-10ms,commit延时为50-150ms。