原文:Megastore: Providing scalable, highly available storage for interactive services
TL;DR
Megastore结合了NoSQL的扩展性和RDBMS的便利性,支持局部的ACID、多datacenter间的无缝failover。
Megastore在每个datacenter有一个instance,数据存储在对应的Bigtable中,instance之间使用Paxos协调。
从性能指标来看读写延时有点高,平均在100ms以上。
Introduction
Megastore的设计目标:
- 高扩展性。
- 能支持快速开发。
- 低延时。
- 提供前后一致(consistent)的数据视图。
- 高可用。
传统RDBMS难以满足扩展性的要求,而NoSQL则缺少一致性,开发成本高。
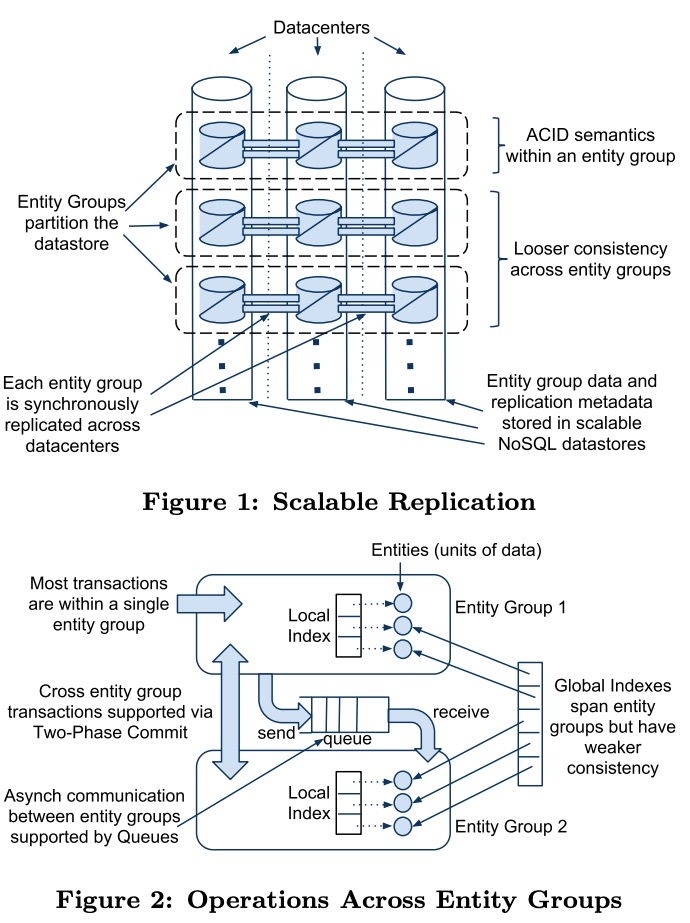
Megastore结合了这两者,将数据分片后各自单独replicate,分片内提供ACID,分片间提供有限的一致性。
Megastore还使用了Paxos来同步各个datacenter的数据,而不只是用Paxos来选master或同步metadata。
Toward Availability and Scale
- 针对可用性,Megastore实现了同步的、容错的、针对远距离链路优化的log replicator。
- 针对扩展性,Megastore将数据切分为很多小分片,每个分片独立有log,存储在各个instance对应的Bigtable中。
Replication
Megastore放弃了那些可能丢数据、或不保证ACID、或需要有很重的master(避免单点不可用)的replication策略。
Megastore使用了Paxos,但做了一些扩展,允许:读任意足够新的本地replica;写只需要一轮往返。
另外Megastore每个分片使用单独的log也是为了提高Paxos的扩展性。
Partitioning and Locality
Megastore中每个数据分片称为一个entity group,entity group内支持1PC的ACID,之间只支持2PC或异步通信(最终一致)。注意这里的异步通信是在逻辑的不同分片间的,而不是物理上不同datacenter之间,后者是同步且强一致的。
局部索引支持ACID,全局索引支持最终一致。
不同应用分片策略不同:
- Email根据account。
- Blog需要根据不同维度,比如profile、blog、blog的唯一标识。有些操作会跨不同entity group,需要选择用2PC还是异步通信。
- Maps可以根据经纬度分片,如果分得过细,跨分片的操作会太多;如果分得过粗则总吞吐有限。
Megastore的数据存储在Bigtable上,同一分片的数据对应在Bigtable的连续的行上。用户可以参与指定数据的存储方式。
A Tour of Megastore
API Design Philosophy
规范化的关系schema依赖于查询时join,因此不适合Megastore:
- join的延时难以预测。
- Megastore中读远多于写,因此将工作从读移到写是合算的。
- Bigtable适合存储和查询分级的数据。
使用分级布局和声明式的反规范化有助于消除大多数的join。用户需要的时候可以自己在应用代码中实现join,比如有用户自己基于并行查询实现了outer join。
(作者给了一些Megastore不支持join的理由,但不是很有说服力)
Data Model
Megastore中数据按表 - entity - property来组织。每个property可以是基础类型,也可以是protobuf对象,可以是required、optional、repeated。
表可以是entity root表,或是child表。每个child表都有可以唯一标识root表中entity的外键。
每个entity对应Bigtable上的一行。
1 | CREATE SCHEMA PhotoApp; |
IN TABLE User表示所有Photo entity都会直接存储在User对应的Bigtable表中,且物理上与User entity相连。这样可以拍平分级的join。
索引既可以定义在任意property上,也可以定义在protobuf对象的内部字段上。局部索引适用于entity group内部,会与主表entity同步原子更新。全局索引跨entity group,但更新是异步的。
使用STORING可以减少索引反查主表的次数。
定义在repeated property上的索引,每个不同的property value对应一个索引行,与主表entity是N:1的关系。
索引可以内联到更上层主表中,此时索引项相当于上层主表entity的一个repeated property。如将PhotosByTime定义为内联到User的索引,这样每个User对应若干项PhotosByTime。
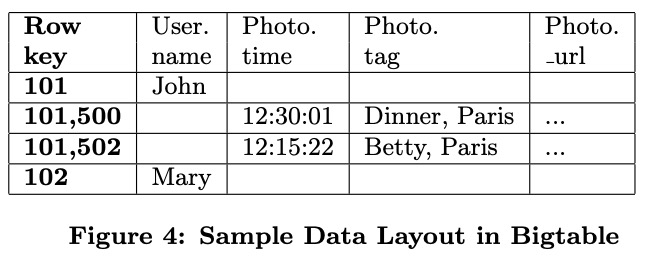
每个entity group的metadata和log也会保存到entity root对应的Bigtable表的一行中,这样可以原子更新。
Transactions and Concurrency Control
Megastore中的事务是先将修改写进entity group对应的WAL中,再更新Bigtable表。
Megastore使用了MVCC来保证修改的原子性:所有修改都完成后再提升readable version。
Megastore提供了三种读级别:
- Current:确保readable version提升到当前的committed version。
- Snapshot:使用当前readable version。
- Inconsistent:无视readable version,直接读,可能读到不一致或不完整的数据(但能避免读entity group metadata?)。
写事务总是先做一次current read来确定下个log位置,然后将所有修改打包为一个entry,使用更大的timestamp,再通过Paxos提交。使用一个server来批量提交所有写事务能避免冲突。
完整的事务周期:
- 读metadata。
- 读应用数据。
- 使用Paxos提交。
- 更新Bigtable表。
- 清理垃圾数据。
跨entity group的操作可以走异步消息队列,但也可以使用2PC,虽然Megastore不推荐应用依赖于2PC。
Replication
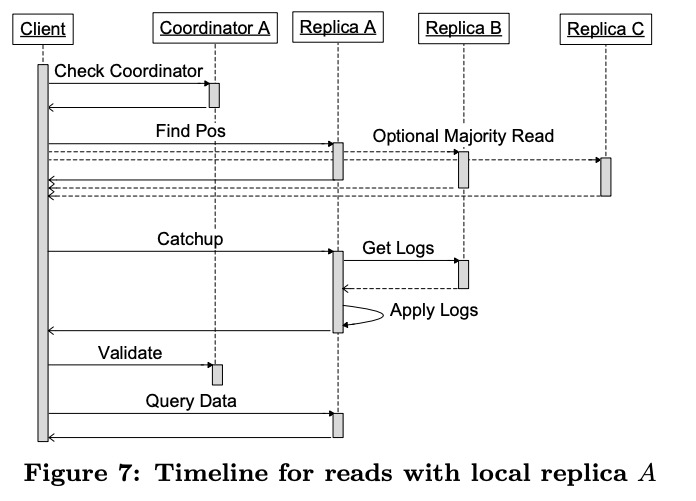
Megastore的Paxos不依赖于某个master,任意replica都可以服务读写请求。
为了保证读请求大多数情况下可以只读本地,Megastore在每个instance中增加了一个coordinator,它记录了哪些entity group的本地replica足够新。写请求负责在有写失败时通知coordinator将对应的entity group去掉。
原生的Paxos的写需要两轮往返,通常的优化是基于master,master可以把上个请求的ACCEPT和下个请求的PREPARE合并为一个请求,这样变成一轮。Megastore不想要master带来的单点可用性问题。相反,它使用了leader。每个entity group的每个replica有一套单独的Paxos来选出一个特殊的leader,leader可以直接发起proposal为0的ACCEPT,其它writer仍然要走正常的两轮Paxos协议。
应用写本地Bigtable不需要走replication server。
replication log中每个log entry对应Bigtable中的一个cell,Megastore允许某个replica的log中间有空洞,这样刚failover的replica可以尽快参与到投票中。

在做current read时,至少有一个replica的readable version要追上committed version,称为catch up。完整过程:
- 读本地的coordinator判断当前entity group是否足够新。
- 获取committed version并选择replica:
- 如果本地replica足够新就读本地。
- 否则走正常的Paxos读。
- 触发对应replica的catch up。
- 如果选择的是本地replica,且完成了catch up,则向coordinator发送一个请求来判断entity group是否健康。应用不需要等待这个请求返回,如果失败了后续的读请求还会自动重试。
- 读数据。
写流程:
- 询问leader是否接受当前log entry作为0号proposal,如果是,直接跳到步骤3。
- 向每个replica发送PREPARE。
- 询问其它replica是否接受当前proposal。
- 与拒绝或失败的replica对应的coordinator通信,移除这个entity group。
- 更新接受的replica对应的Bigtable。