TL;DR
在 cache coherence 方面经常被人引用的 paper。
Overview
为什么要用单独的 cache service:
- 读请求数量远多于写(高一个数量级)
- 多种数据源(MySQL,HDFS,以及其它后端服务)
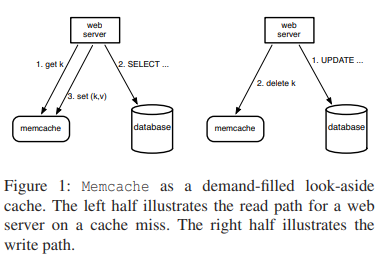
Facebook 用 cache service 的方式:
- 作为 query cache 减轻 DB 的负担,见图 1。具体用法是按需填充(demand-filled)的 look-aside cache,即读请求先请求 cache,未命中再请求 DB,然后填充 cache;写请求直接写 DB,成功后再发请求给 cache 令对应的 key 失效(删除而未更新是为了保证幂等)。
Is Memcached look-aside cache?
The distinction between look-aside and look-through caches is not whether data is fetched from the cache and memory in serial or in parallel. The distinction is whether the fetch to memory on a cache miss originates from the caller or the cache. If the fetch to memory originates from the caller on cache miss, then you’re using a look-aside cache. If the fetch to memory originates from the cache on cache miss, then you’re using a look-through cache.
应用自己处理 cache miss 之后的 fill 就是 look-aside,cache 自己处理 fill 就是 look-through,学废了没有?
- 作为更通用的 key-value 存储(字面理解是不再绑定到具体的后端上了?)
memcached 本身只是单机的,Facebook 将其修改为可以支持 cluster。这样,他们就多了两个需要处理的问题(在原有问题的基础上,笑):
- 如何协调多个 memcached 节点。
- 如何维护 cache 与 DB 的一致性。
这也是本文的两个重点:
- 优化
- 一致性
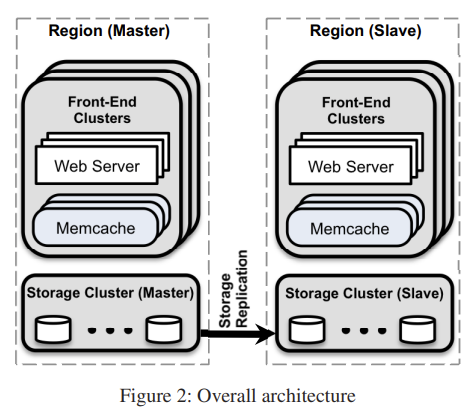
In a Cluster: Latency and Load
Reducing Latency
通常一个业务请求会对应很多次 cache 访问,比如作者的一份数据是平均 521 次 get(P95 是 1740 次)。在使用 memcached 集群后,这些 get 会根据某些 sharding 规则(实际是一致性 hashing)分散到不同的 memcached 节点。当集群规模增大后,这种 all-to-all 的通信模式会造成严重的拥塞。replication 可以缓解单点热点,但会降低内存的使用率。
Facebook 的优化思路是从 client 入手:
将数据间的依赖关系梳理为 DAG,从而能并发 batch fetch 相互不依赖的数据(平均一个请求可以 fetch 24 个 item)。
完全由 client 端维护 router,从而避免 server 间的通信。
client 通过 UDP 发送 get 请求,从而降低延时。数据显示在高峰期 0.25% 丢包率。set 和 remove 仍然走 TCP。
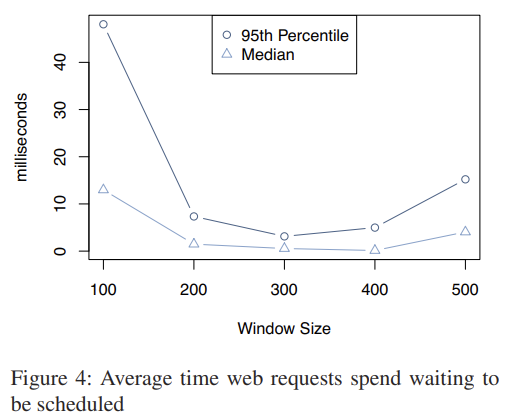
client 端使用滑动窗口来控制发出的请求数量,避免 response 把机架或交换机的网络打满。滑动窗口的拥塞策略类似于 TCP,即快下降+慢上升。与 TCP 不同的是,滑动窗口针对进程的所有请求生效,而 TCP 则是针对某个 stream 生效。如下图可见,窗口太小,请求并发上不去;窗口太大,容易触发网络拥塞。
Reducing Load
Leases
作者引入 lease 是为了解决两类问题:失效的 set;惊群。前者发生在多个 client 并发乱序 update 一个 key 时。后者发生在一个很热的 key 不停被写,因此不停被 invalidate,读请求不得不反复请求 DB。
每个 memcached 实例可以为某个 key 生成一个 token 返回给 client,client 后续就可以带着这个 token 去更新对应的 key,从而避免并发更新。memcached 会在收到 invalidation 请求后令对应 key 的 token 失效。
为了顺便解决惊群问题,作者对 lease 机制加了个小小的限制:每个 key 最多每 10s 生成一个 token。如果时间没到就有 client 在 cache miss 下请求 token,memcached 会返回一个特定的错误,让 client 等一会重试。通常这个时间内 lease owner 就有机会重新填充 cache,其它 client 下次请求时就会命中 cache 了。
另一个优化是 memcached 在收到 invalidation 请求后,不立即删除对应的数据,而是暂存起来一小会。这期间一些对一致性要求不那么高的 client 可以使用 stale get 获取数据,而不至于直接把寒气传递给 DB(笑)。
Memcache Pools
单独的 cache service 就要能承载不同的业务请求,但很多时间业务之间相互会打架,导致某些业务的 cache 命中率受影响。作者因此将整个 memcached 集群分成了若干个 pool,除了一个 default pool,其它的 pool 分别用于不同的 workload。比如可以有一个很小的 pool 用于那些访问频繁但 cache miss 代价不高的 key,另一个大的 pool 用于 cache miss 代价很高的 key。
作者给的一个例子是更新频繁(high-churn)的 key 可能会挤走更新不频繁(low-churn)的 key,但后者可能仍然很有价值。分开到两个 pool 之后就能避免这种负面的相互影响。
Replication Within Pools
replication 会被用于满足以下条件的 memcached pool:
- 业务会定期同时获取大量 key。
- 整个数据集可以放进一两台机器。
- 但压力远高于一台机器的承载能力。
这种情况下 replication 要比继续做 sharding 更好。
空间换负载均衡
Handling Failures
memcached 一旦无法服务,DB 就很容易被压垮,导致严重的后果。
如果整个 memcached 集群不可服务,所有请求都会被导到其它集群。
范围很小的不可服务会被自动处理掉,但处理前出错可能已经持续长达几分钟了,足以导致严重的后果。因此集群中会预留一小部分(1%)机器,称为 Gutter,用于临时接管这种小范围的机器不可服务。
client 如果收不到 response,就会假设目标 memcached 挂了,接着请求一台 Gutter 机器。如果再请求失败,就会查询 DB,再将 key-value 写到 Gutter 机器上。
Gutter 机器会快速令 cache 失效,这样它就不用处理 invalidation 请求,能降低负载。代价是一定的数据不一致。
这种方法不同于传统的 rehash data 的地方在于,rehash data 有扩大失败范围的风险。比如有 key 非常热的时候,它去哪,哪出问题。而使用 Gutter 就可以很好地将风险控制在指定的机器范围内。
Gutter 的另一个好处是将那些访问失败的请求集中了起来,增加了它们后续命中的机会,也因此降低了 DB 的负载。
In a Region: Replication
随着业务压力增长而无脑扩容反倒可能让问题恶化:
- 业务请求越多,热点 key 越热。
- 随着 memcached 节点增多,网络拥塞也会越来越严重。
另一个可能的点:n 个 client 与 m 个 server 之间可能的连接数是 n*m。
作者的解法是将 memcached 加上 webserver 一起划成若干个 region 对应同一个 DB,好处:
- 异常情况的影响范围小(俗称爆炸范围小)
- 可使用不同的网络配置
不同 region 对应同样的 DB,因此会有数据重复(即 replication),但分散了热点,允许不同的配置,这样用空间换取了其它好处。
Regional Invalidations
在 region 化之后,数据可能同时存在于多个 region 上,当有 client 更新了对应的 key 之后,我们要能保证所有 region 的 cache 都能被正确 invalidate 掉。
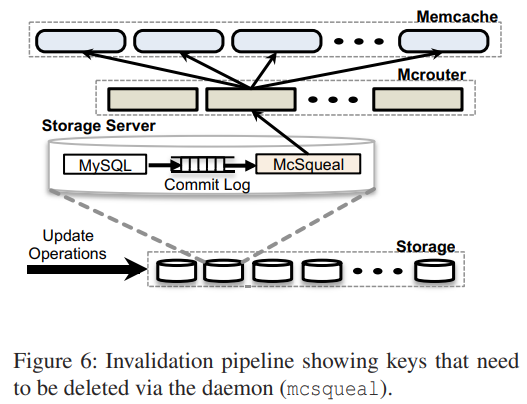
作者的做法是在每台 DB 上部署一个名为 mcsqueal 的 daemon,它会在事务提交之后,将其中被影响到的 cache keys 取出来,广播给所有业务集群。为了降低 invalidation 的发包速度,daemon 会聚合一组 invalidation 发给部署有 mcrouter 的业务机器,再由这些机器将请求转发给具体的 memcached。
这种做法,相比于 web server 直接发送 invalidation 给 memcached,好处:
- mcsqueal 的聚合效果更好
- mcsqueal 有机会重发 invalidation(直接通过 DB 的 WAL)。
但如果数据本身是没有 MVCC 的,这种做法仍然有非常小的不一致风险:
- get data v0
- update data to v1
- invalidate data
- fill cache with v0
Regional Pools
如果将用户请求发给随机的一个前端集群,则最终每个集群都会 cache 几乎相同的数据。这样好处是我们可以单独下线一个集群而不会影响 cache 命中率。但另一方面,这会造成数据过度拷贝(over-replicating)。作者的解法是令多个前端集群共享同一组 memcached server,称为一个 regional pool。
此时有个挑战时,如何决定哪些数据应该在每个 cluster 中都有副本,哪些应该一个 region 只有一份。前者的跨集群流量更少,延时更低,但后者更省机器和内存。
作者给出的标准是:
- 用户越多,越倾向于 cluster
- 访问频率越高,越倾向于 cluster
- value 越大,越倾向于 cluster
Cold Cluster Warmup
为了解决集群刚启动时 cache 有效数据极少,命中率极差的问题,冷集群可以从热集群中搬数据过来,而不用直接请求 DB。这样一个集群的预热可以在几小时内完成(相比之前要几天时间)。
这里要注意的是避免数据不一致。一种常见的不一致场景是,来自从热集群获取数据与收到 invalidation 之间乱序,即先收到 invalidation,再收到 stale data。作者的解法比较 hack:令 invalidation 等待两秒再操作。这样仍然会冒一些数据不一致的风险,但实践中显示两秒是非常安全的。
真的吗,我不信.jpg
Across Regions: Consistency
Facebook 会 region 化部署 MySQL 集群,从而:
- 用户可以请求距离最近的 region,从而降低延时
- 控制爆炸半径
- 新集群往往可以享受到能源或经济上的好处
MySQL 本身会有一个全局的 master 实例,其它 region 都是只读副本,region 之间使用 MySQL 的 replication 协议保持数据同步。但备实例落后于主实例却容易导致 memcached 与 DB 有数据不一致。
这种不一致本质上也来自收到数据与收到 invalidation 之间乱序。备集群收到数据是延后的,如果 invalidation 提前到达,就没有指令可以令 stale data 失效了。
一致性模型往往会带来性能上的额外开销,使其无法应用在大规模集群上。Facebook 的优势是 DB 与 memcached 可以协同设计来在一致性与性能之间取得比较好的平衡。
master region 发起的写入
考虑到一个位于 master region 的 webserver 刚写完 DB,它直接发送 invalidation 给各个 master region 的 memcached 是安全的,但发给其它 replica region 就不安全了:对应 region 可能还没有收到相应的修改。
此时前面引入的 mcsqueal 就起了重要的作用:各个 region 都通过自身的 mcsqueal 来 invalidate 失效数据,保证了每个 region 的 DB 与 cache 状态是一致的。
非 master region 发起的写入
现在考虑非 master region 的写请求,如果仍然等 mcsqueal 来 invalidate,就会违反 read-your-write 语义;如果直接 invalidate,就可能导致数据不一致。
作者引入了 remote marker 来最小化数据不一致的风险。remote marker 可以标记本地的某个 key 可能已失效,需要将请求转发给 master region。注意当有并发写入同一个 key 的情况时,过早删除 remote marker 仍然可能导致用户看到过期数据。
Single Server Improvements
all-to-all 通信模式下,单点就可能成为瓶颈,提升单点性能也因此变得重要。
Performance Optimiztions
优化的起点是一个使用固定大小 hashtable 的单线程 memcached。第一波优化:
- 自动扩容 hashtable。
- 引入多线程并用一个 global lock 保护共享结构。
- 每个线程单独的 UDP 端口以降低争抢。
接下来的优化:
- 引入细粒度的锁:hit get 提升 2 倍;missed get 提升 1 倍。
- TCP 替换为 UDP:get 提升 13%,multiget 提升 8%。
Adaptive Slab Allocator
为啥不直接用 jemalloc,自家的产品?一定是历史原因
The Transient Item Cache
memcached 支持 ttl,会自动踢掉过期的 key。作者将其改成了 lazy eviction,直到下次访问时才判断过期。这带来了一个新问题:一波短生命期的 key 可能一直待在 LRU list 中直到被踢掉,期间一直在占用着内存。
作者因此使用了一种混合方法:大多数情况下 lazy evict,对少数短生命期的 key 则 proactively eveit。这些 key 会被放到一个环形 buffer,称为 Transient Item Cache。memcached 每秒会扫描这个 buffer。
Software Upgrades
为了避免集群升级导致 cache 变冷,memcached 会将数据保存在共享内存中,这样新进程启动之后仍然可以有足够的本地数据。