TL;DR
一篇相对早期(2012 年)的 paper,介绍了服务特定领域(WebUI)的 OLAP 系统 PowerDrill。PowerDrill 貌似在狗家命运不太好,这篇 paper 发表前后已经被 Dremel 给取代了。
Introduction
PowerDrill 是一个 in-memory 的列存分析引擎。它主要为 Google 的一个交互式的 WebUI 提供分析服务,需要高可用和低延时。因此 PowerDrill 选择了 in-memory 架构,这是它和 Dremel 最大的区别。优点是性能好,单个查询能扫描的行数比 Dremel 多,缺点是能支持的总数据量远小于 Dremel。
PowerDrill 的一些数据(看看就好):
- 2008 年底上线,2009 年面向 Google 内部开放使用。
- 每个月有超过 800 名用户(其实不少了)执行约四百万个 SQL query。
- 最多的用户每天花在 WebUI 上的时间超过 6 小时,触发多达一万两千次查询,扫描多达 525 万亿(trillion)个 cell。
Basic Approach
The Power of Full Scans vs. Skipping Data
列存相对于行存的主要优势是:
- 典型查询只需要加载少部分列。(这里提到的是不多于 10 列 vs 上千列,看来是宽表场景)
- 列存压缩效率高,更节省 I/O 与内存占用。
另外列存系统通常会着重优化扫描性能。对于像 PowerDrill 这样的大量 ad-hoc query 的系统,传统的二级索引已经无法满足需求了(维护过多列上的索引的代价是非常巨大的)。
有一个经验法则,相对于通过索引,全表扫描的优点是:
- 随机 I/O 更少。(索引扫描本身是顺序的,但回表是随机 I/O)
- 内循环更简单,更容易被优化
- cache 局部性好。这一点对于内存中的数据尤为关键,访问 L2 性能要比内存高一个数量级。
在全表扫描基础上,我们可以再引入 skip index。这就需要在数据导入时将数据切成若干个小 chunk,每个 chunk 维护简单的数据结构用于在查询时过滤掉整个 chunk。这就需要 skip index 本身不能有 false-negative。
PowerDrill 中 partition + skip index 的效果远好于传统的索引,因为前者可以适用于所有查询,且不需要存储冗余数据(比如相比于 C-Store)。
Partitioning the Data
PowerDrill 的 partition 策略是:
- 用户选择一组用于 partition 的列(有序)。
- 从一个大 chunk 开始,每次用 partition columns 二分(range partition)将其分成两个小 chunk。
- 重复第 2 步直到每个 chunk 行数不超过 5 万行。
缺点是需要用户干预
注意查询时 partition columns 并不会被特殊对待。
但它们本身的 range 会反映到 skip index 上
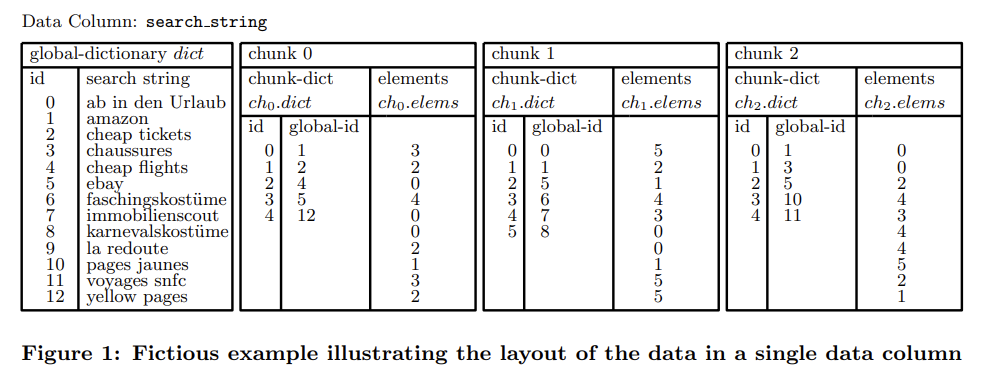
Basic Data-Structures
PowerDrill 主要面向的是字符串。它使用了 global + local directionary 来编码:
- 全局 dict 有序。
- 每个 chunk 维护这个 chunk 的 local dict 与 global dict 的映射关系。
- 实际数据用 local dict 编码。
这样的优点是:
- local -> global mapping 本身可以当作 skip index 使用。
- local dict 元素数量少于 global dict,编码长度更短。
How to Evaluate a Query
1 | SELECT search_string, COUNT(*) as c FROM data |
主要在讲怎么用 skip index 加速
IN
Basic Experiments
这节先测量基准性能,PowerDrill 完全没 partition 数据,只用本身的列存查询引擎。
Query 1: top 10 countries
1 | SELECT country, COUNT(*) as c FROM data |
Query 2: number of queries and overall latency per day
1 | SELECT date(timestamp) as date, COUNT(*), |
Query 3: top 10 table-names
1 | SELECT table_name, COUNT(*) as c FROM data |
下面的 CSV 和 record-io 都是行存。
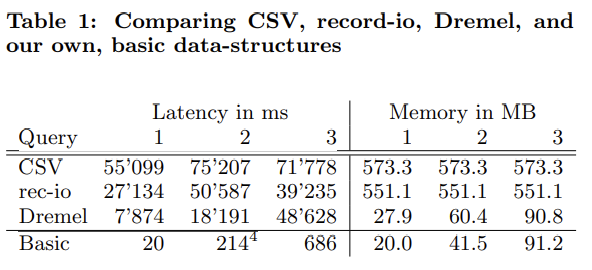
解读:
- I/O 不是瓶颈。
- PowerDrill 的 dict encoding 在 query 1 的 group by 发挥了巨大的作用。
脚注里写 PowerDrill 会将参与 group by 的多列物化为一列,但这三个 query 似乎没有这种场景。
- 所有数据常驻内存对性能影响巨大。但即使去掉这个假设,PowerDrill 性能仍然达到了 Dremel 的 30 倍以上。
- PowerDrill 使用的未压缩的 dict encoding 占用也和 Dremel 压缩后的体积差不多。
- 另外即使有如
date这样的函数,PowerDrill 仍然可以应用 dict encoding,是因为它默认物化了所有表达式。(笑)
Key Optimizations
PowerDrill 的第一优化原则就是在内存中容纳尽可能多的数据。
Partitioning the Data into Chunks
partition 列为 country 和 table_name,最终产生了 150 个 chunk。
内存占用:
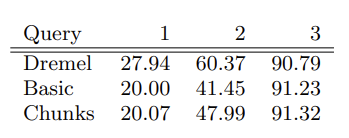
partitioning 略微增加了一些内存占用,其中 query 2 增加得相对较多是因为 local dict 中 distinct 值更多。
Optimize Encoding of Elements in Columns
目前 dict code 还是用 int32 保存,但实际上我们可以根据 NDV 选择合适的 bits。当只有一个 distinct value 时,直接保存 rows n 就可以了。
下面是自适应使用 1/2/4 字节的 dict code 的优化效果(左边是 chunk dict 占用,右边是总占用):
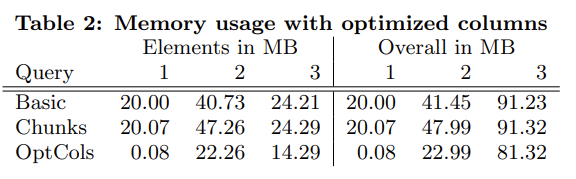
Query 1 的效果显著得过分了。但 query 3 的总体占用仍然非常高(table_name 有非常多的 distinct value),且主要是 globa dict 占用的。
Optimize Global-Dictionaries
global dict 满足以下两个条件:有序;通常公共前缀很长。因此 PowerDrill 用建立在 array 上的 trie tree 来编码 string -> code 的映射,这个方向的内存占用就明显降低了。为了同时也能支持 code -> string 的查询,trie tree 的每个 inner node 取 4 bit 长度的数据,这样一个 node 最多 16 个 child。
code -> string 这段没看懂,实际上我们需要做的是在 trie tree 中维护 count,我猜可能是 node 的 fanout 小一些可以减少 children 占用的空间。
trie encoding 的效果是 table_name 的 global dict 从 67.03MB 降到了 3.37MB,query 3 总占用从 81.31MB 降到了 17.66MB。
Generic Compression Algorithm
接下来再应用 Zippy(Snappy 的内部版):
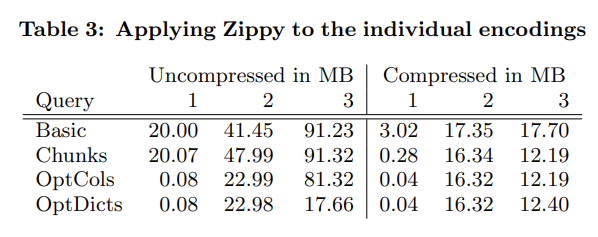
效果很好,但相对 Basic 的优势也减小了。
为什么前面还要自己搞那些优化:前面的 encoding 不需要解压就可以随机访问。毕竟只有很少量的数据会被用到。
为了平摊解压本身的开销,PowerDrill 使用了两级结构:数据首先以压缩状态加载到内存中,随后被访问时再转换为解压状态。
Reordering Rows
我个人非常喜欢的一个优化
接下来,为了帮助 Zippy,PowerDrill 使用了一种优化,将不同行数据按字典序进行排序。这样相近的数据排列在一起,能明显提升压缩效率。这个优化尤其适合与 RLE 配合使用。

最优的排序方式本身是 NP-hard 的,一种比较好的启发式算法是先按 cardinality 增序决定列的相对顺序。
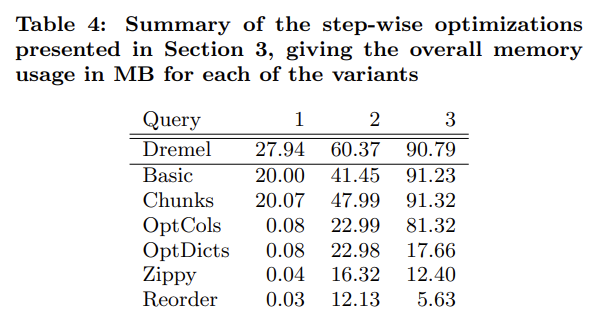
Dremel 中也提到了这个优化,看起来效果很好。但奇怪的是似乎不太能见到 Google 以外的系统用到这个优化。可能它太偏向离线了?在线系统在 compaction 时也有机会做这类优化。
Distributed Execution
比较没意思,略
Extensions
Complex Expressions
物化表达式
Count Distinct
近似算法而不是精确值
Other Compression Algorithms
ZLIB 和 LZO。ZLIB 的压缩率很好,但解压太慢。LZO 的一个变种最终被用于了生产环境。
Further Optimizing the Global-Dictionaries
为了避免加载无用的 dict,作者将整个 global dict 分成了若干个 sub-dict,lazy load。另外作者还用到了 Bloom-filter 来进一步避免加载无用的 sub-dict。
Improved Cache Heuristics
为了避免单个 query 对 LRU cache 的冲击,PowerDrill 使用了类似于 ARC 的 cache。