TL;DR
Deuteronomy 终于进化到了 MVCC 加持。新的 Deuteronomy 仍然是 TC + DC 的分离架构,但做了大量的优化,如 Bw-Tree、caching、lock-free 算法/数据结构、epoch reclamation 等。
大多数系统其实不是架构不行,而是单纯优化不到位。
总得来说我们能从 Deuteronomy 上看到很多后来的 cloud database 的影子。
Overview
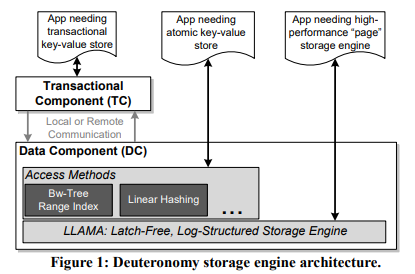
Deuteronomy 有三种组件:
- Transaction Component(TC):请求入口,维护 transaction、mvcc table、log buffer、read cache。
- Data Component(DC):存储状态机。
- TC Proxy:将 TC 的 committed transaction 发给 DC。
Deuteronomy 的核心思想是 TC 与 DC 分离,这样就可以为多种不支持事务的 DC 增加事务能力。但它的旧实现严重制约了它的性能,尤其是当 DC 经过几次演进之后,使用了 Bw-tree、LLAMA 等高性能结构之后,原有的 TC 的性能就成为了瓶颈。
这篇 paper 就是在讲如何重新设计实现 TC(包括新加入的 TC Proxy),使其能充分发挥 DC 的高性能。
全文看完,感想:
- TC 和 DC 分离的思路是非常适合分布式环境的。比如 FoundationDB 就用了类似的思路实现了非常好的扩展性和性能。
- TC 本身看上去是个单点,如何确保它的高可用是个复杂的问题。
- MVCC 的粒度是 record,当数据量非常大的时候是个问题。不同领域可以考虑用不同的粒度,比如传统的 RDBMS 可以用 page,OLAP 可以用 chunk 或者 partition 等。这里不同粒度需要 TC 和 DC 共同确定。
- 大量读时,TC 本身可能成为瓶颈,在保证语义的前提下 bypass TC,直接访问 DC,可能是另一大优化。
这篇 paper 架构层面没有做大的改变,对我而言主要价值来自:
- 并发控制方面,为何选择用 TO 而不是 OCC。
- 如何在实践中贯彻 latch-free,真正发挥硬件的能力。
- 如何通过区分 fast path 和 slow path 兼顾性能与正确性。
- 手把手教你怎么实现 epoch reclamation。
TC
旧的 TC 的事务采用了 2PL,lock 开销很大。新 TC 引入了类似于 [Hakaton] 的 MVCC,其特点是每个 record 对应一个 valid version range。另外每个事务是可以读到其它未提交事务的修改的,因此需要在 commit 时确保所有依赖的事务都 commit 了,否则就要级联式 rollback。
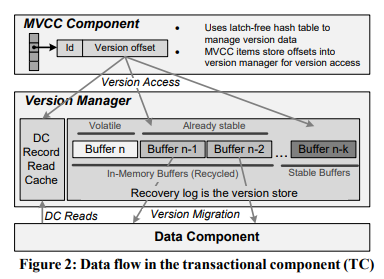
TC 中与 MVCC 有关的有(见图 2):
- MVCC table,一个无锁的 hash-table,其中每个 item 不保存具体数据,而是指向其它结构。
- Version manager:
- Log buffer:所有 redo log records,其中包含已经持久化的 records,但仍然保留在内存中用作 cache。
- Read cache:从 DC 读到的 records,与 log buffer 可能有重叠。
注意 TC 只使用了 redo log,而没有 undo log,是因为只有 committed transaction 才会被发往 TC Proxy,最终持久化到 DC 上。在 TC recovery 过程中,没有对应 committed record 的 transaction 会被直接丢弃。因为不需要 undo,redo log 中不需要保存旧值(因此也不需要读取旧值),进一步降低了开销。
旧设计 中先写 DC 再写 log,因此 DC 还要处理 rollback。DC 还要确保不能将 TC 还未标记 stable 的 log 写下去,由此还引入了 EOSL(End Of Stable Log)机制,由 TC 来精细控制 DC 何时刷盘。新设计明显简化了 DC 的职责,也减少了 RPC 次数。
另外新设计中 DC 写不再位于关键路径,用户请求只在 log 成功持久化到 TC 之后就返回。
作者表示新的 TC 性能提升了两个数量级,主要归功于:
- MVCC
- readonly transaction 的 fast path
- 延迟向 DC 发送 log
- 将 log buffer 用作 cache
- batch 发送 log
- redo log 不需要读取旧值
- 新的 latch-free 结构(buffer 管理与内存回收)
Concurrency Control
新设计的 MVCC 相比 Hekaton 的 snapshot isolation 更进一步:serializability。作者选用了 Timestamp Order(TO),理由:
- Hyper 的经验表明 TO 对短事务效果非常好。
- 只要过程中严格保证 ts 顺序,TO 在事务 commit 时不需要做任何额外检查(不会有冲突)。(但如前所述,可能存在级联 rollback)
TC 上所有事务的状态保存在了 transaction table 中。TC 定期会计算得到当前最老的活跃事务 OAT(oldest active transaction),用于垃圾回收。
MVCC table 是用无锁的 hash-table 实现的,分成了若干个 bucket,其中每个 item 对应一个 record,定长且对应一个 cacheline,包含:
- 定长的 hash
- 定长的 key 指针(key 本身是变长的)
- 访问过当前 record 的最高的 ts
- record 对应的一个或多个 version,其中每个 version 也是定长的,包含:
- 对应的 transaction id
- version offset,对应到 log buffer 或 read cache
- aborted 位
整个 MVCC table 是无锁的,新增 record 就是 append 到对应 bucket 的末尾,而移除则只是设置一个 remove bit,后续再遍历 list,结合 epoch reclamation 真正物理移除。
旧设计 中只读事务也要在 log buffer 中占一个位置,走完整的 commit 流程才能返回,这显然无法支撑大量读。新设计中作者使用了如下优化:
只读事务过程中记录访问过的事务对应的最高的 LSN,到它自己 commit 时,如果这个 LSN 已经持久化好了,只读事务就不用再真正将 commit record 加到 log buffer 中了;反之,则仍然要走完整的 commit 流程。这是一种优化 fast path 的思路。
接下来,MVCC table 需要定期 gc:
- 比 OAT 依赖的事务还老的 record 可以回收。
- 已经持久化到 DC 的 record 可以回收。
Managing Versions
TC 处理事务的写操作时,首先通过 MVCC check 是否满足 TO 要求,接下来直接在 log buffer 中分配一个 item,然后再将这个 item 的 offset 和 version 一起写入 MVCC table。这样就能避免数据被反复移动。
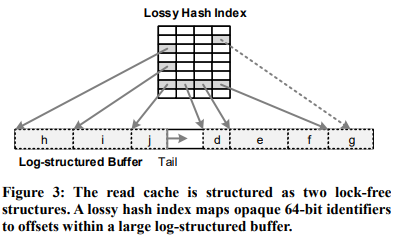
log buffer 本身可以用作 cache,除此之外,read cache 存放 DC 返回的数据。两者共同实现 TC 的 caching 机制。
read cache 的结构见图 3,它由两个 latch-free 的结构组成:一个 hash table,一个 ring buffer。hash table 可以与 log buffer 共用相同的 id 机制,间接指向 ring buffer 中的某个位置。read cache 的 ring buffer 会随着写入逐渐覆盖老 version(间接达到 LRU 的效果)。所以 hash table 只能当作 hint。
一种潜在优化是比较热的 version 不应该被直接覆盖,而是应该重新加到 tail,给它第二次机会,但作者表示没有动力做。
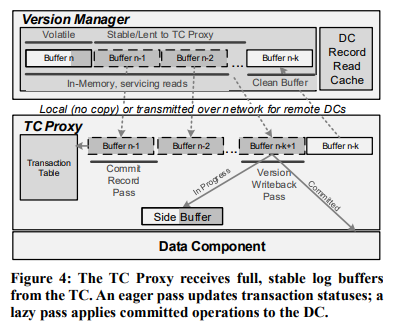
TC Proxy
TC Proxy 永远与 DC 部署在一起。TC 会定期将持久化好的 log 发给 TC Proxy(如果 TC 与 DC 在相同机器上,只会发送引用,避免拷贝)。
注意 TC 向 TC Proxy 发送的 log 是包含未 committed 的事务的,因此 TC Proxy 需要维护 transaction table。TC Proxy 会定期扫描自身的 log buffer,将所有确定 committed log records 写入 DC,剩余结果未知的 log records 则转移到一个 side buffer(预期很少),这样整个 log buffer 可以重用,效率更高。
如前所述,Deuteronomy 只有 redo log,不需要读取旧值,因此 TC Proxy 只通过 upsert 向 DC 写入数据。这还允许 DC 中的 Bw-tree 直接向仍在磁盘上的 page 应用 delta(而不需要预先加载到 cache 中)。
在配合 TC 回收 MVCC records 上,TC Proxy 会维护两个 LSN:
- T-LSN:TC Proxy 已收到的最高 LSN。
- O-LSN:DC 已连续持久化的最高 LSN。
通过维护两个 LSN,我们可以确保长事务不会阻塞 gc:所有 LSN <= O_LSN 且 commit LSN <= T_LSN 的 MVCC records 都可以被 gc。
commit LSN <= T_LSN 说明 TC Proxy 已知事务已 committed,可能是指此时可以放心去读 DC?
Supporting Mechanisms
作者提到,他们一开始实现 latch-free 时,主要依赖 CAS(compare-and-swap) 操作,但后来换成了 FAA(fetch-and-add)。这也是这一领域的共识:尽量用总是成功的 FAA 替代可能冲突严重的 CAS,从而提升多核下的并发性能。
具体到 buffer 的 offset 上,作者用低 32 位维护 offset,高 32 位维护当前活跃的 user count:每次 FAA 2^32 + SIZE 来修改 active user count。
FAA 的结果如果超出 buffer capacity,说明这个 buffer 已经被 seal 了,不能再使用。那个恰好令它超过 capacity 的线程负责 flush buffer。其它发现 buffer 被 seal 的线程则尝试分配新 buffer(一次 CAS,只有一个能成功)。
接下来是 epoch reclamation。LLAMA 和 Bw-tree 中已经介绍了 epoch reclamation 的实现。作者在这里又应用了 thread-local 来优化性能,减少争抢。
具体实现:
- 全局有一个 global epoch,一个固定长度的 buffer。
- 每当 buffer size 超过阈值(比如 capacity/4)就会提升 global epoch。
- 所有需要删除的对象和它所属的 epoch 一起打包扔进一个固定长度的 buffer。
- 每个线程维护 thread-local 的 epoch,每个操作前复制 global epoch 到 tls,操作后将其设置为 NULL。
- 维护一个 min tls epoch,每当 global epoch 提升或阻碍了 buffer 回收时就重新计算。
这样昂贵的操作(计算 min tls epoch)和全局争抢(提升 global epoch)都被分摊了,主要路径只有很少的原子操作。
线程管理方面 Deuternomy 主要考虑了 NUMA 和 cache 亲和性,尽量避免跨 NUMA 通信。另外 Deuternomy 使用了协程,且优化了内存分配,确保协程栈分配在栈上,而不是堆上。